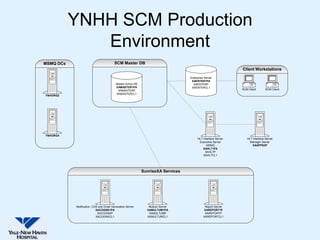
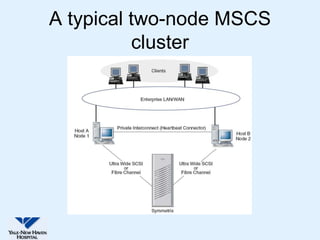
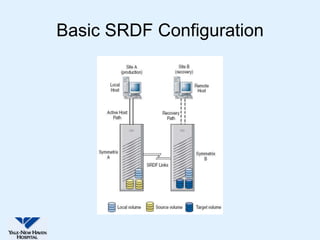
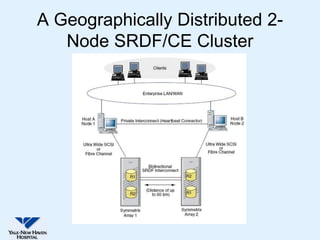
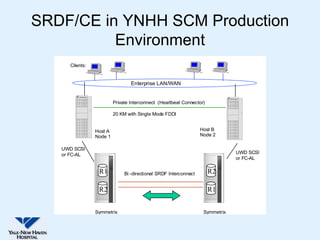
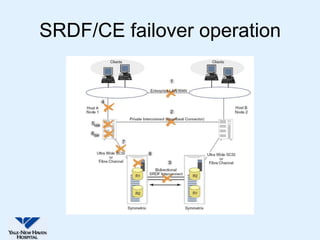
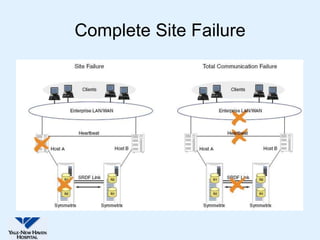
This document discusses Yale-New Haven Hospital's implementation of disaster recovery for their Sunrise Clinical Manager (SCM) environment using Microsoft Cluster Service (MSCS) and EMC's SRDF technology. The hospital uses two geographically separated data centers over 2 km apart with clustered servers and storage to provide continuous uptime. SRDF synchronously mirrors the database between sites to enable rapid disaster restart in case of an outage. Testing showed that the configuration successfully recovered from various failure scenarios with near 100% uptime over the past three years.