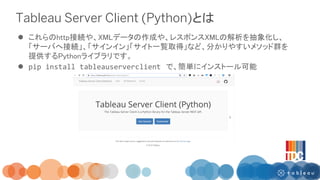
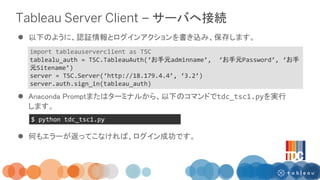
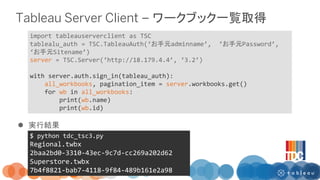
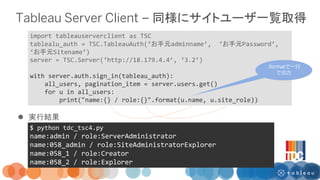
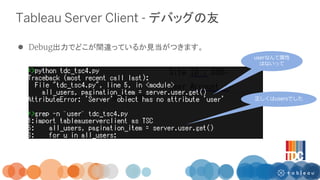
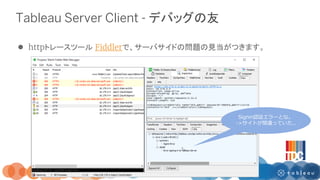
1/24 Tableau Developers Clubで実施したREST APIを活用したワークショップの資料です。 REST APIとは何か? 実際に試してみるためのコードが記載されています。 作成者はシリウスデータサイエンス小今井さんとTableauの飯村さんです。
















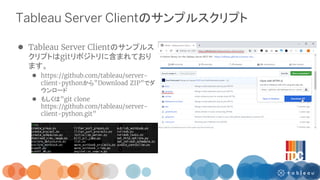
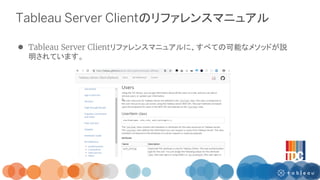









![『モビリティ・インテリジェンス』の社会実装 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/misocial-190218070258-thumbnail.jpg?width=640&height=640&fit=bounds)





























