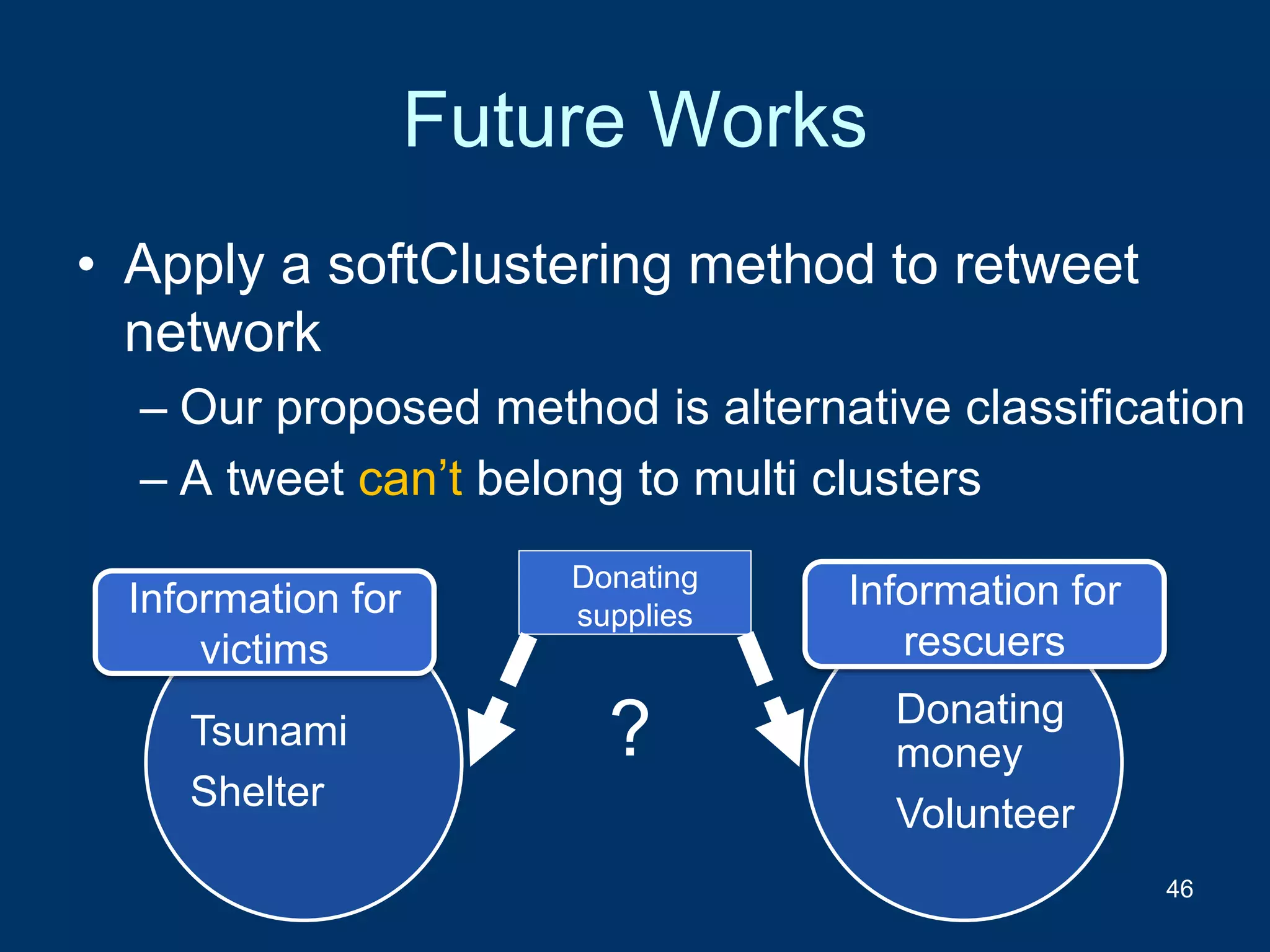
This document describes a method for classifying tweets without using text data. It clusters tweets based on the similarity of users who retweeted them. An experiment showed 89% of clusters had tweets that examiners found topic-similar. Some clusters had low linguistic similarity but captured useful disaster information. Future work includes soft clustering to allow tweets in multiple clusters and reducing computation time for rapid information in disasters.




![How to collect information in
disaster situation ?
• From mass media ?
– General and public information only
– Not personalized
• From social media ?
– They perform well
• [10 Mendoza],[11 miyabe],[10 sakaki]
– In particular, Twitter is useful
• We also focus on Twitter
5](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-5-2048.jpg)


![Focusing on Retweet
• RT(Retweet): Suggest a user has interest
in a Tweet[13 Toriumi]
8
「Shut off the gas」
「My head hurts」
「Wear shoes」
「Good morning !」
「A head office」
「Protect your head」
:
Group
Cluster①
「Shut off the gas」
「Wear shoes」
「Protect your head」
Cluster②
:
Interest](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-8-2048.jpg)








![Network Clustering
• It is assumed that large component have
various topics
• Apply clustering method based on
Newman method [04 Newman] to retweet
network
– To extract clusters that contain similar tweets
17](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-17-2048.jpg)

![Result Example 1
• Cluster about shelter
19
The Oura cafeteria on the Ueno Campus of the
Tokyo University of the Arts is open. You can
spend the night there.
[a quick report] Okumakodo is open! It looks like it
has some blankets http://twitpic.com/48f6y2
Are you all right? [The Tokyo Bunka Kaikan just
opened. It's getting dark and cold, so if you are
around Ueno Station, please go there.]](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-19-2048.jpg)
![Result Example 2
• Cluster about advice for victims
20
If you are evacuating with a baby, wrap the baby
in a blanket and carry it in a tote bag. No baby
buggies! #jishin
[Please spread] If you use Twitter by mobile
phone, turn off your icons to conserve battery life.](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-20-2048.jpg)





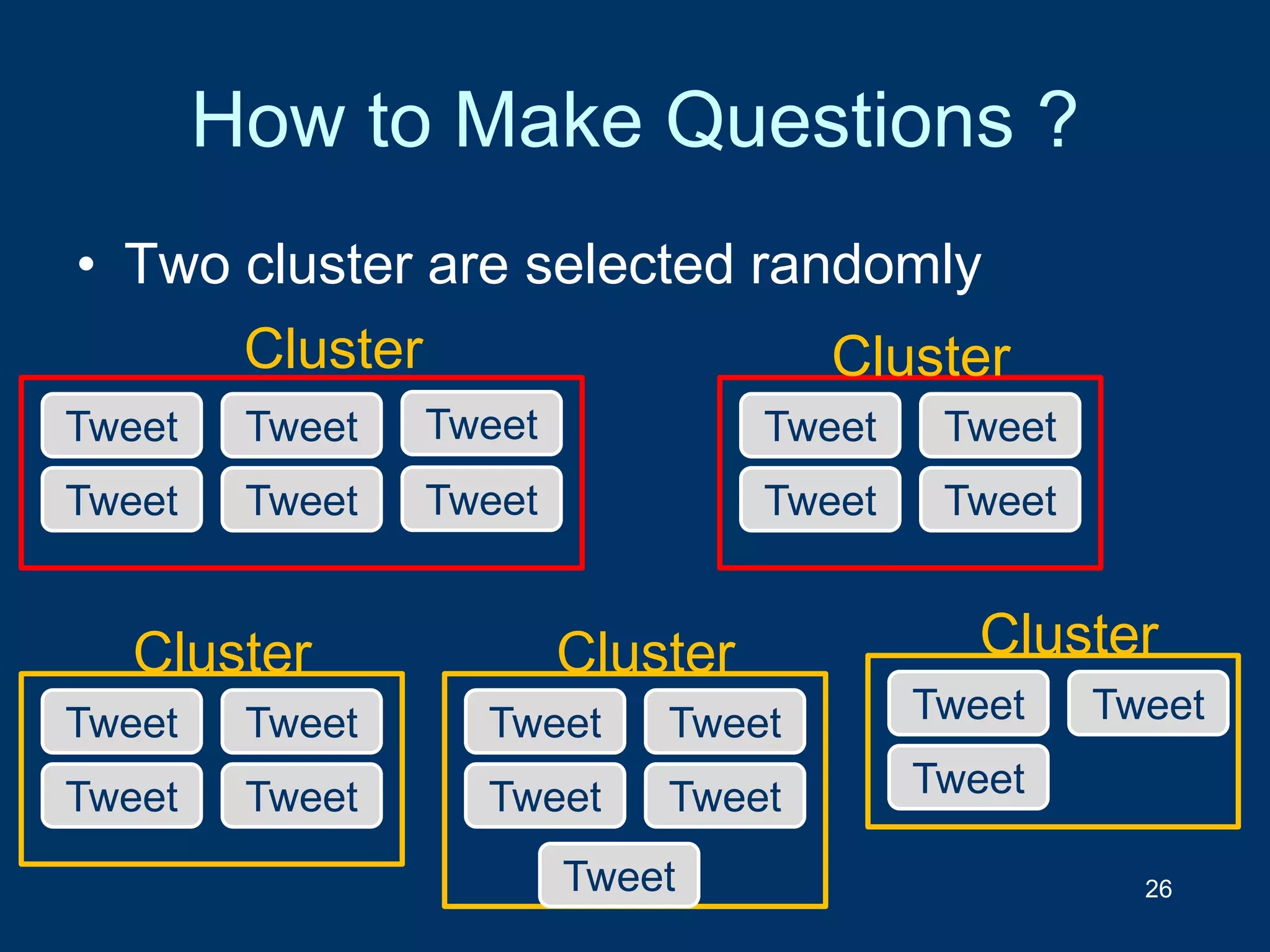
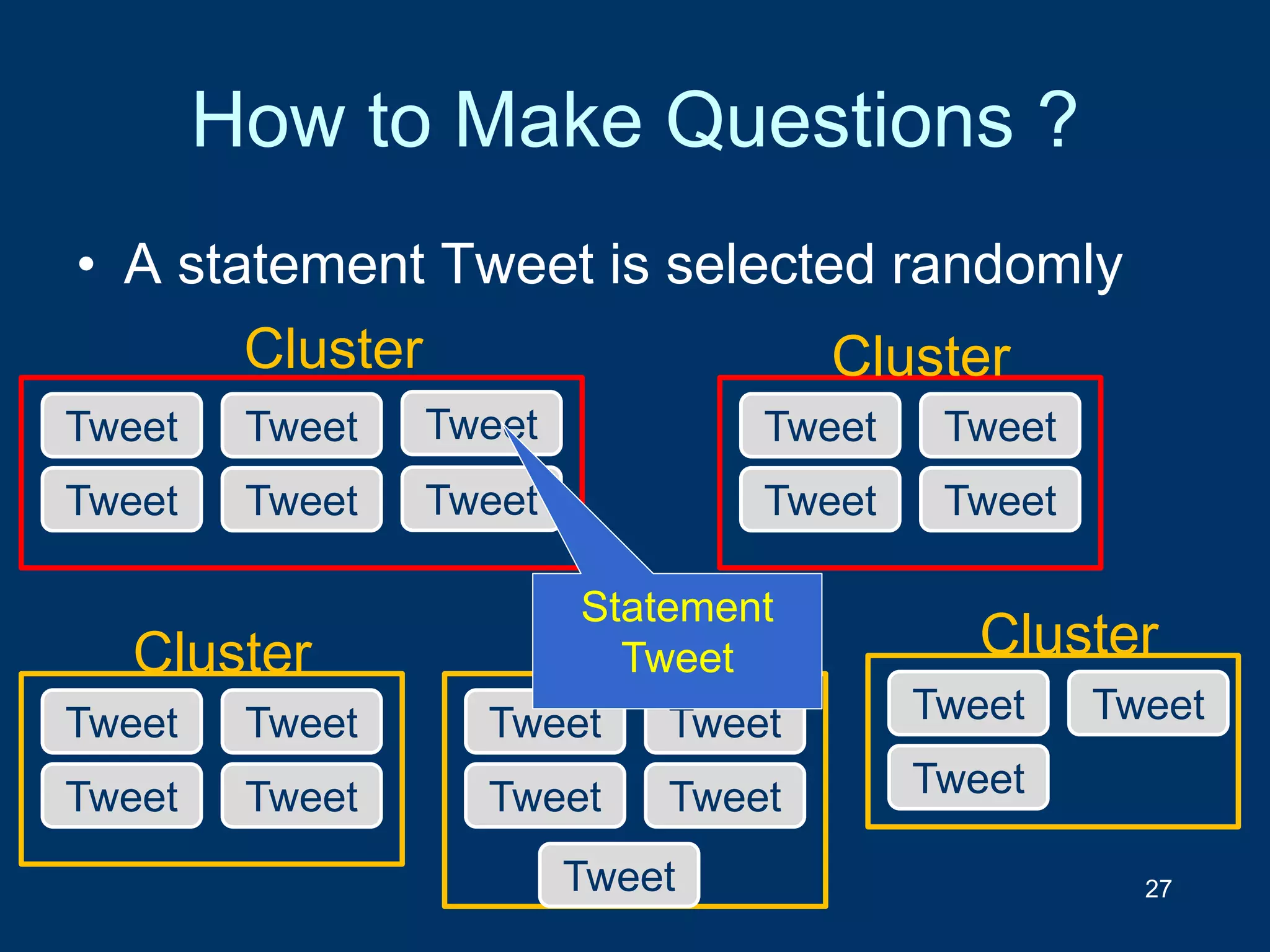
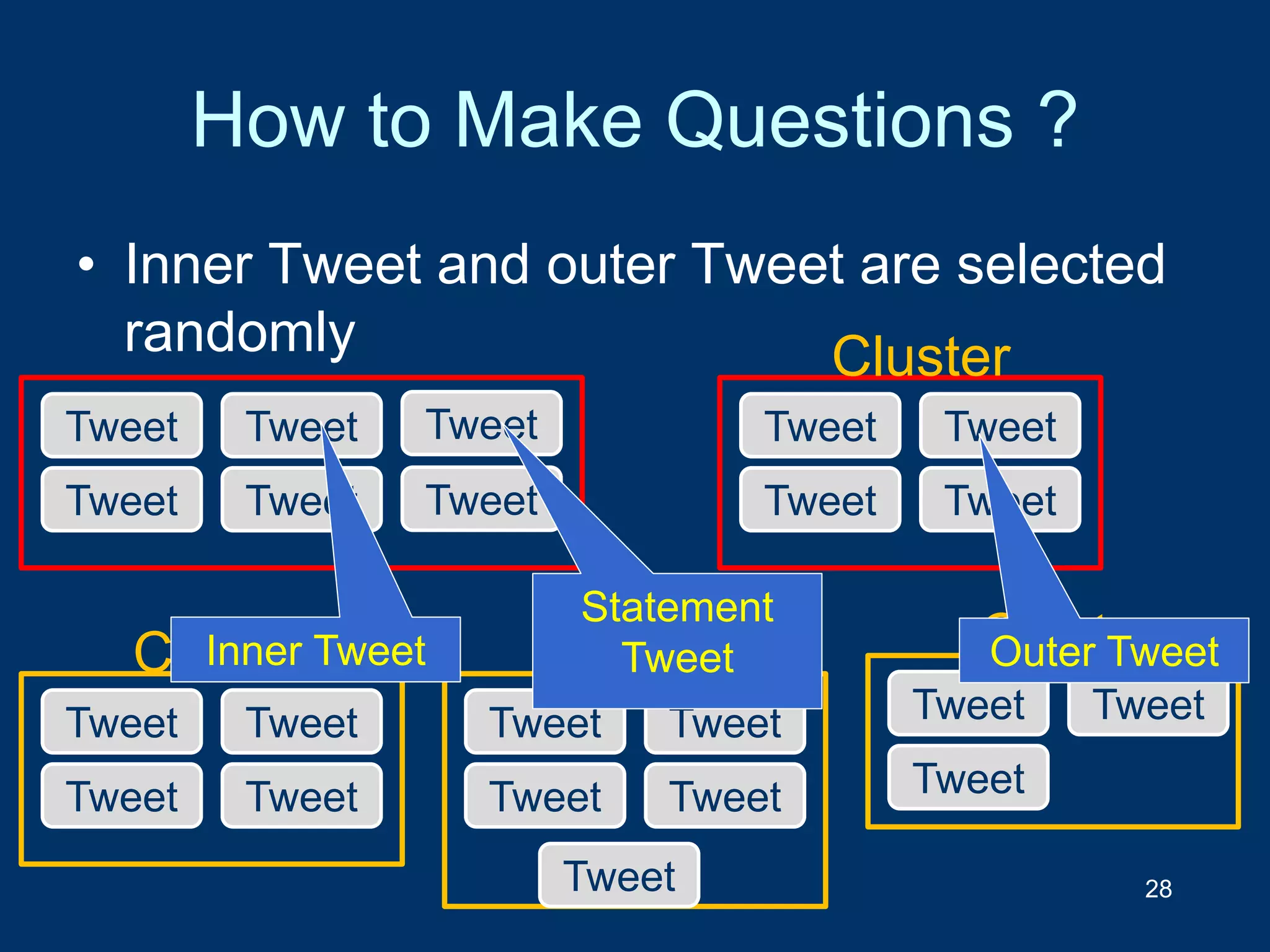






![Can classification based on text
mining group them?
35
This tweet was posted by a volunteer center.
Yesterday, more than 1000 people read it and
learned about dangerous areas and shortages.
What should we do? http://t.co/4JpWlXt #jishin
RT [please spread] Check that your car has a jack
for changing tires. They are useful for rescuing
victims from rubble. #jishin #jisin
• Some clusters have little linguistic similarities
– Which are difficult to group by using text mining
Cluster about advice for victims](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-35-2048.jpg)






![Example of Clusters with low
linguistic similarities 2
• Cluster about advices for victims
– Linguistic similarity is 0.0052
42
RT [Summarize the information]
Open the door, Cook some rice, Place baggages
in an entrance, Buy water, Snacks and a towel,
Blankets, Wear shoes ....
My friend who survived the Great Hanshin
Earthquake evacuated his house in pajamas. So
tonight, sleep in clothes just case you have to
leave quickly.](https://image.slidesharecdn.com/swdm15-150519083712-lva1-app6891/75/Swdm15-42-2048.jpg)