Downloaded 40 times





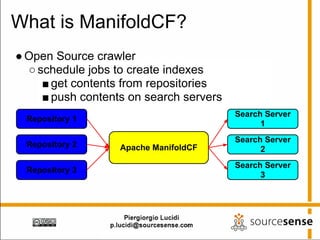

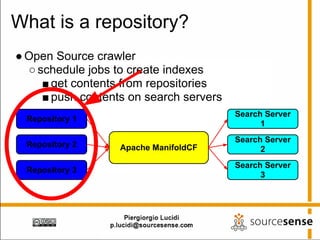


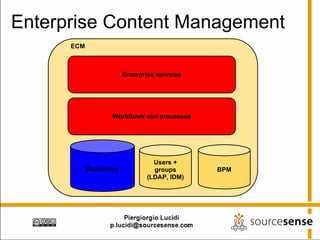

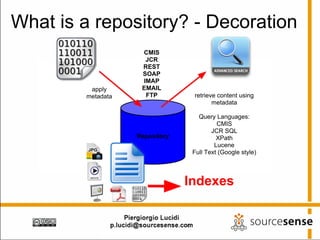
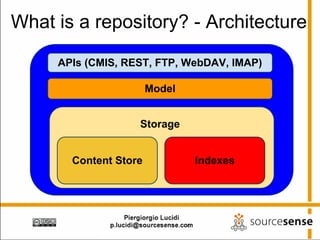


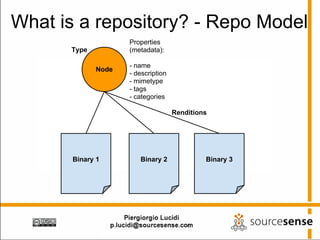
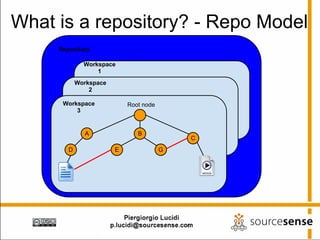


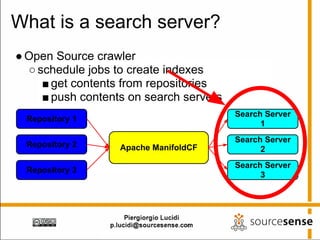

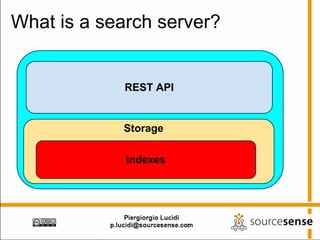

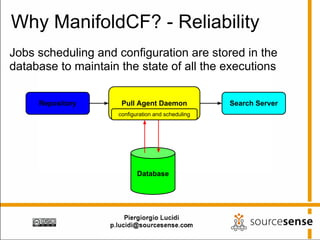
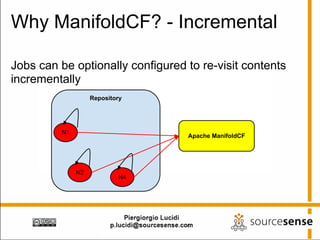


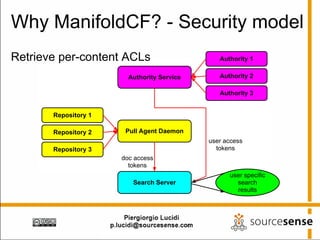



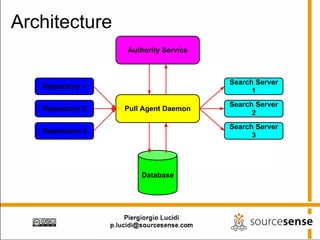

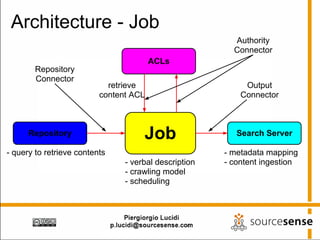










The document provides an overview of Apache ManifoldCF, an open source content management system. It describes ManifoldCF's capabilities, including crawling repositories to index their contents and push those contents to search servers. It details the key components of ManifoldCF like the Pull Agent Daemon, jobs, connectors, and monitoring UI. The document also outlines ManifoldCF's history and major releases from its incubation at Apache to becoming a top-level project.

















































































