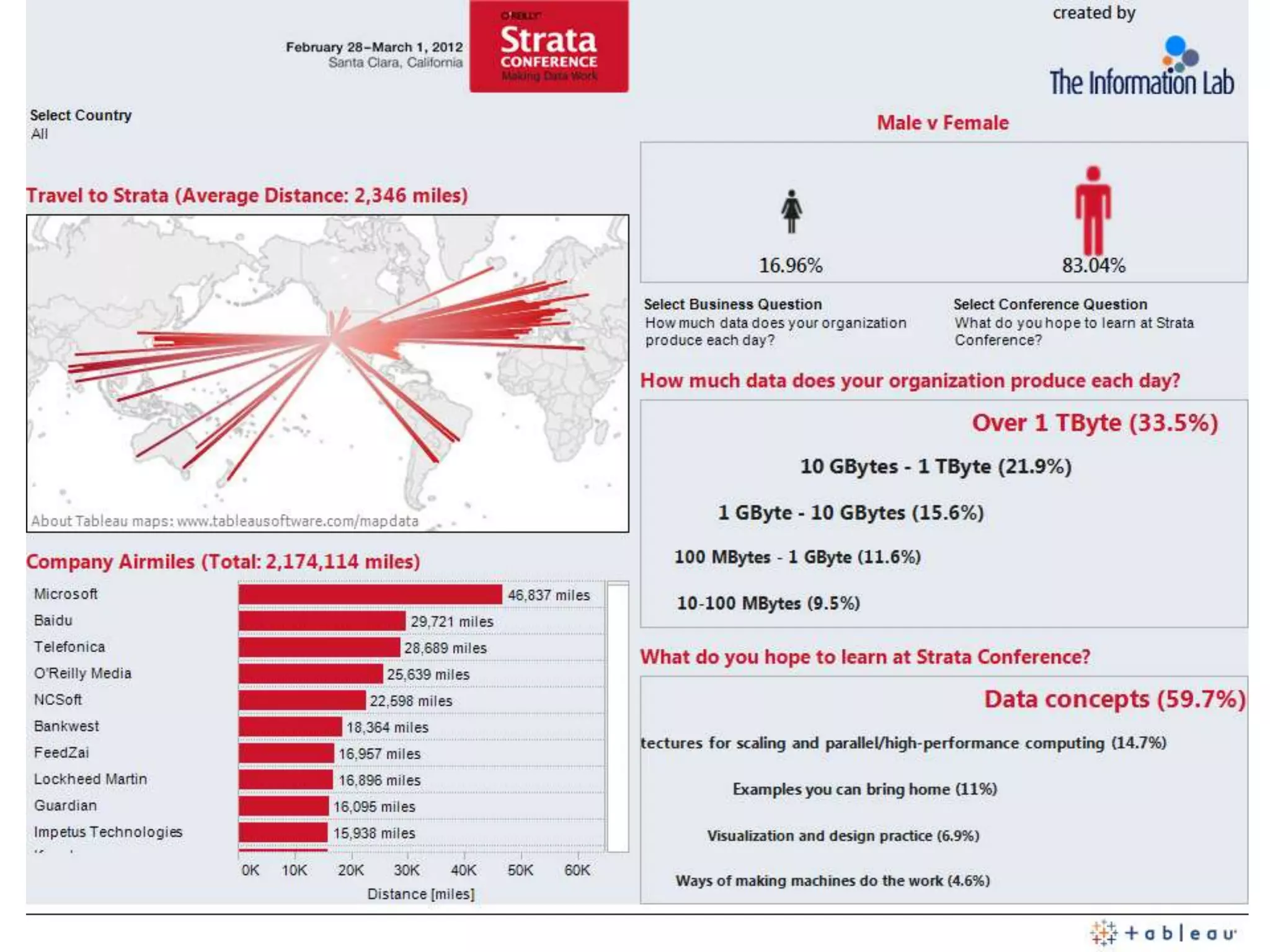
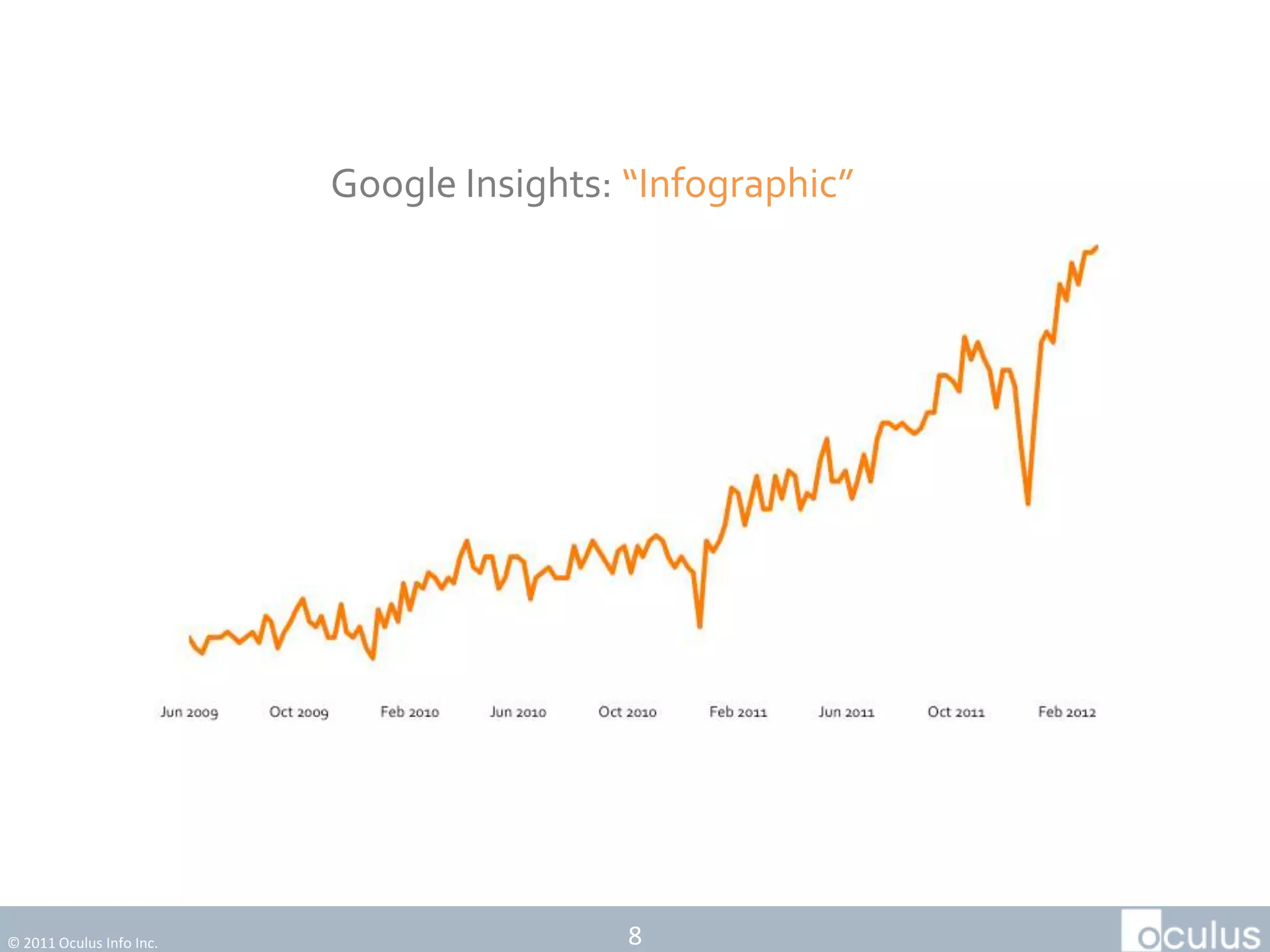
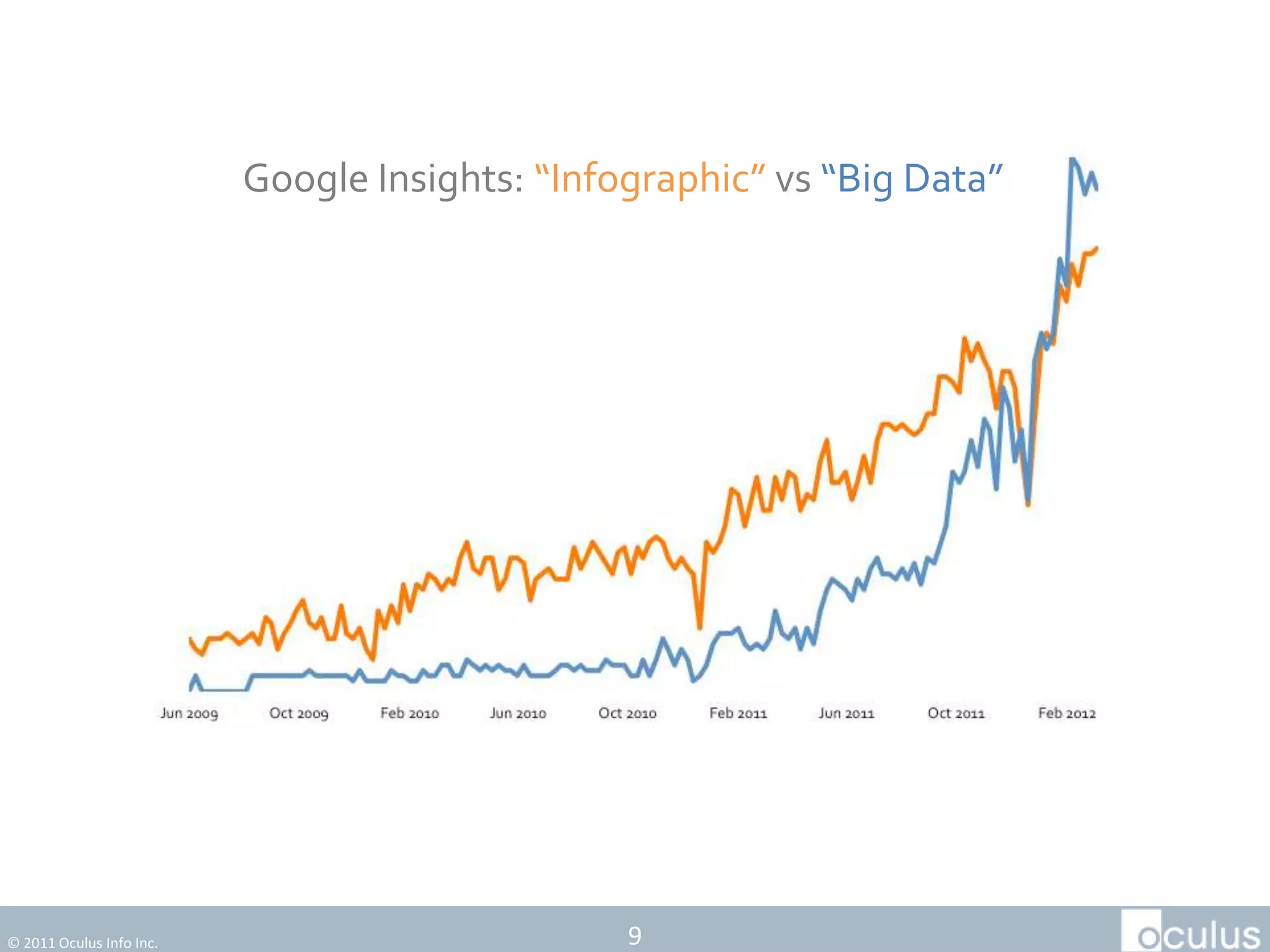
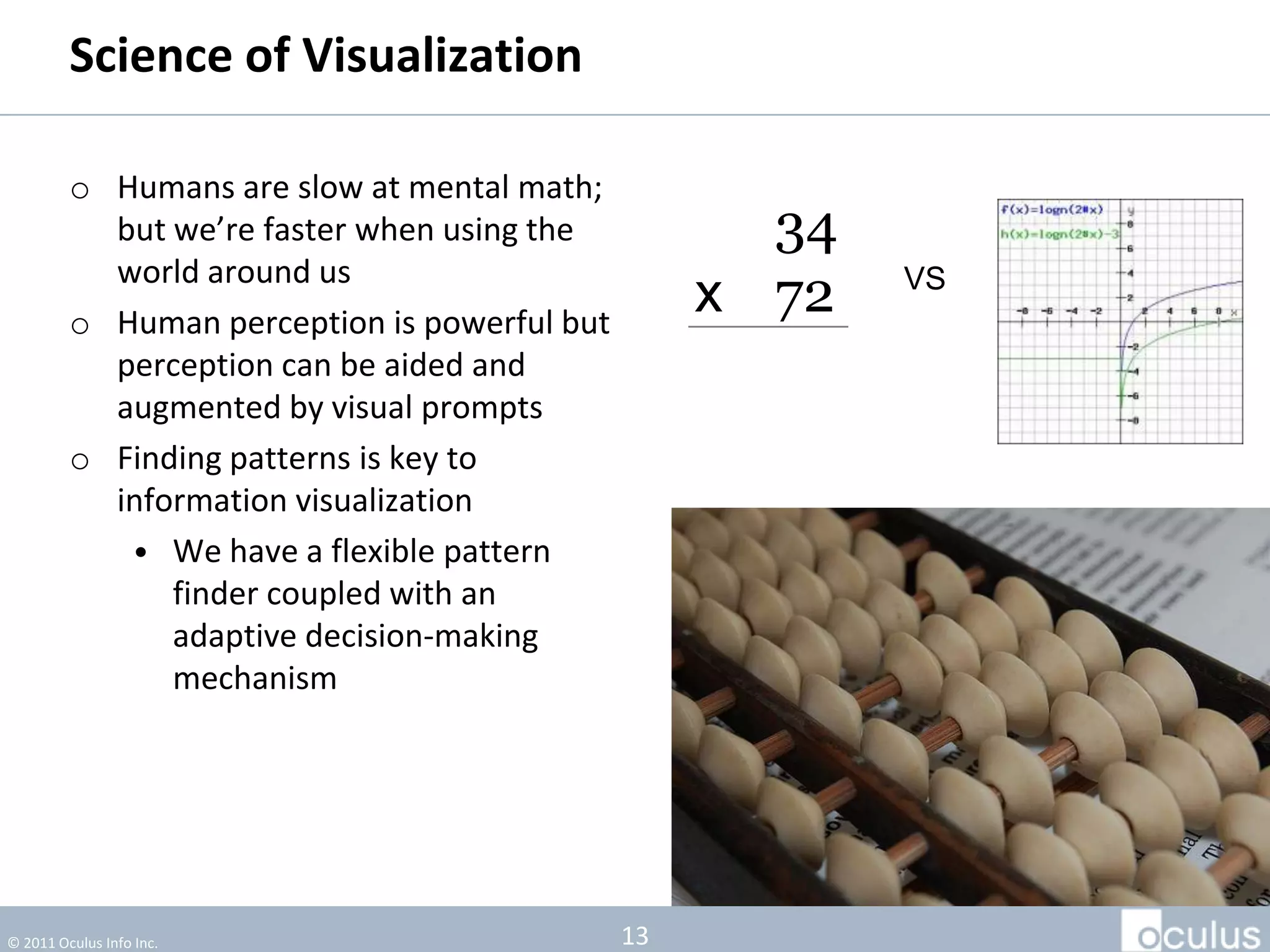
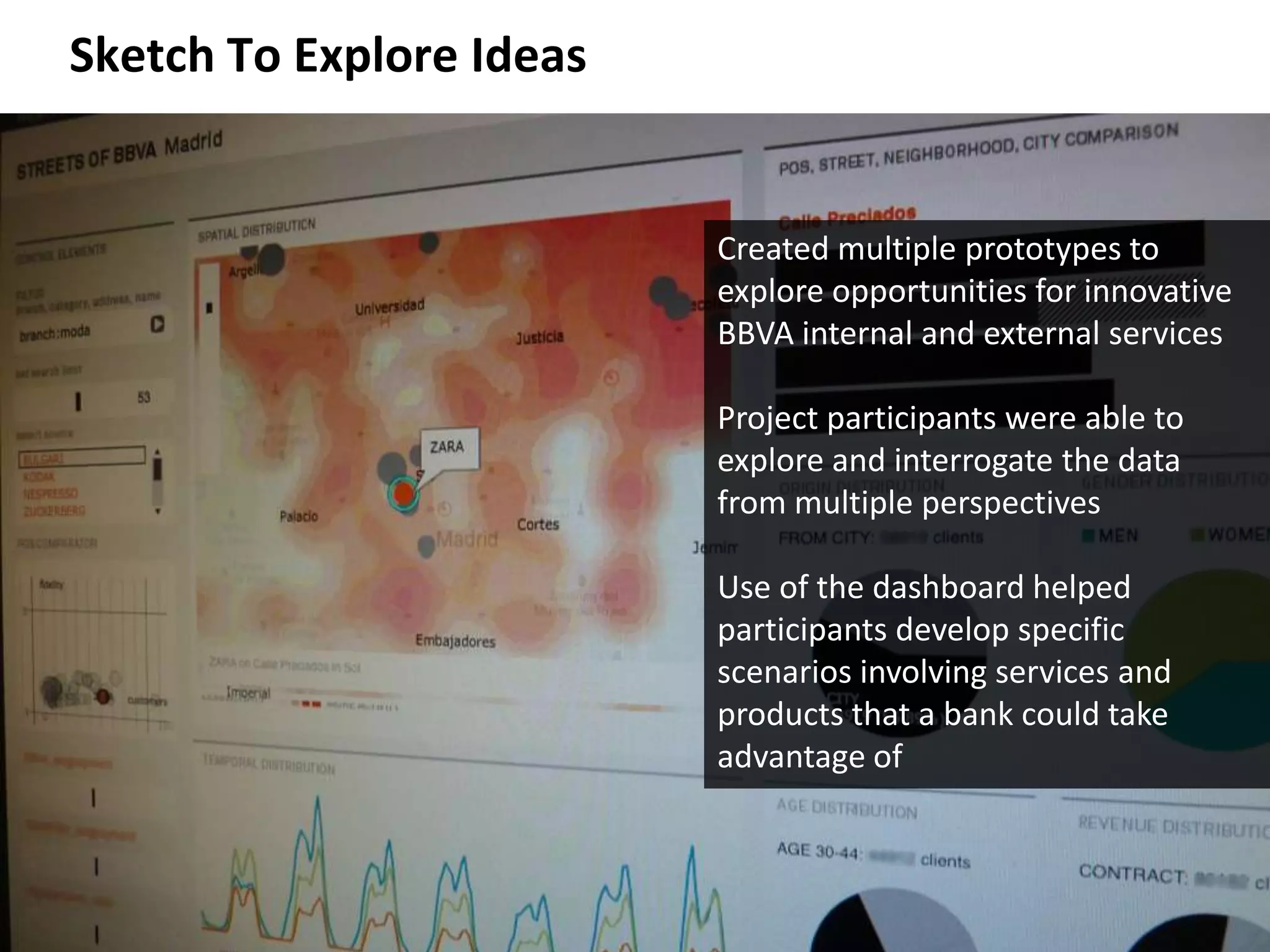
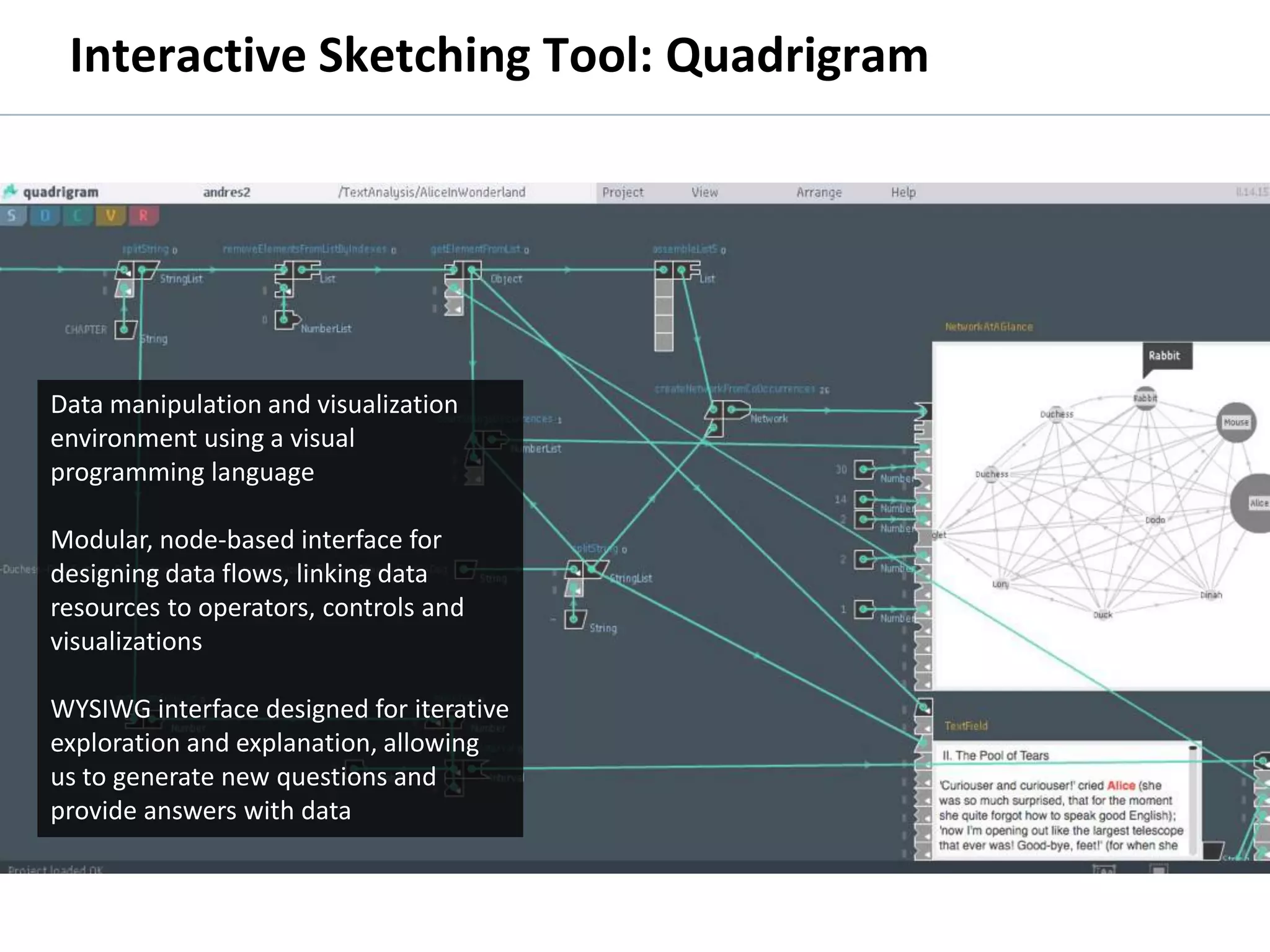
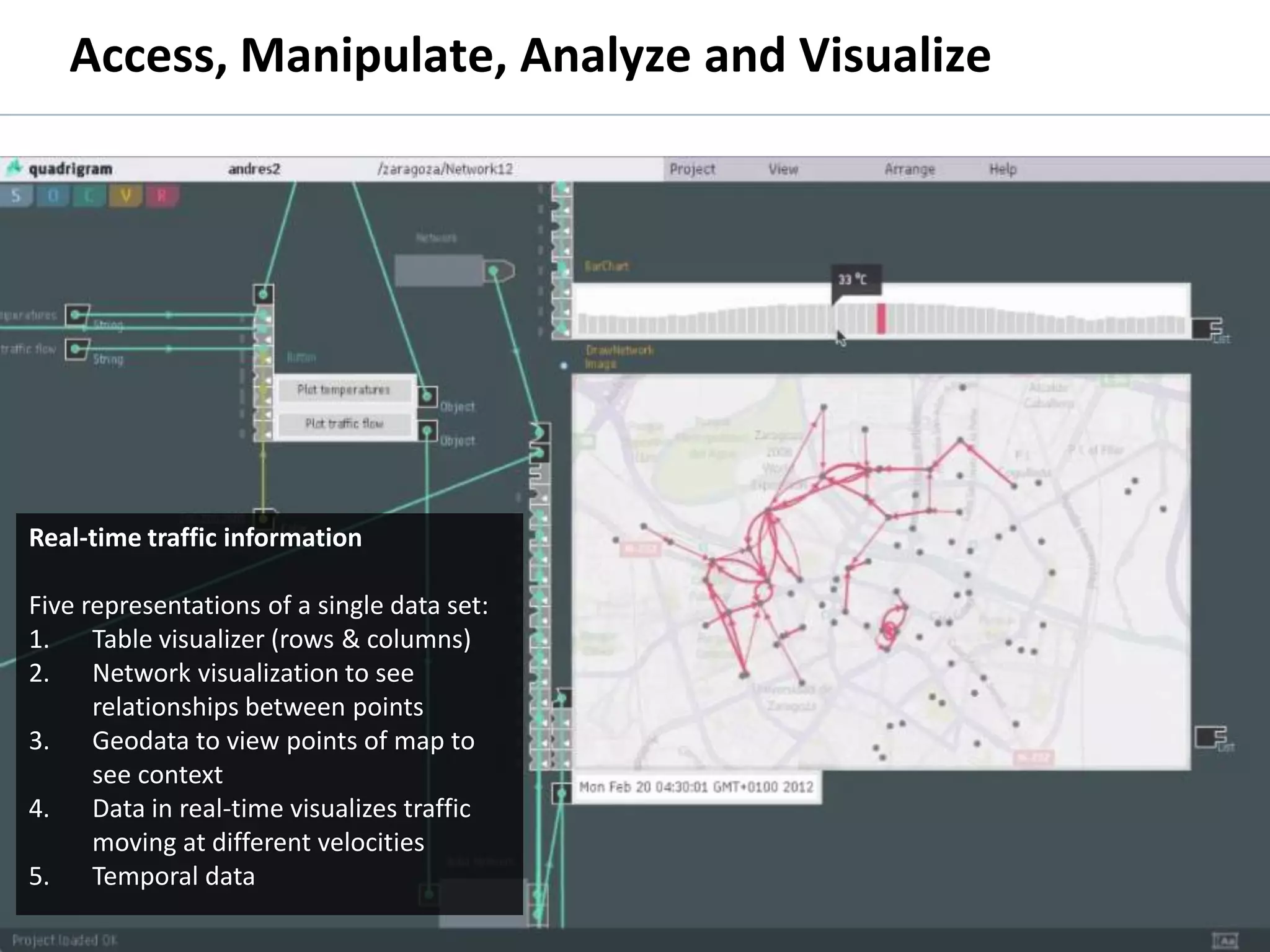
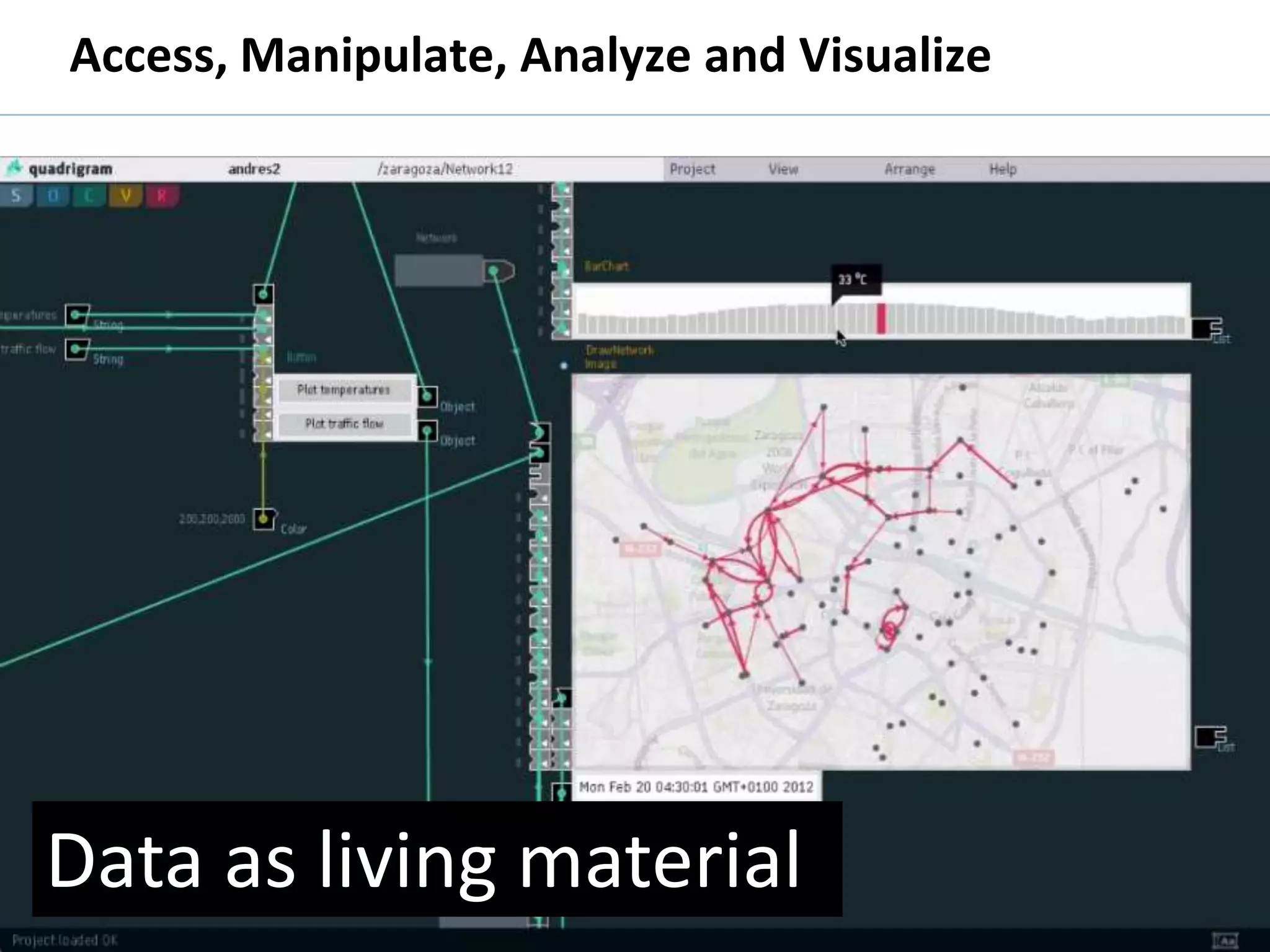
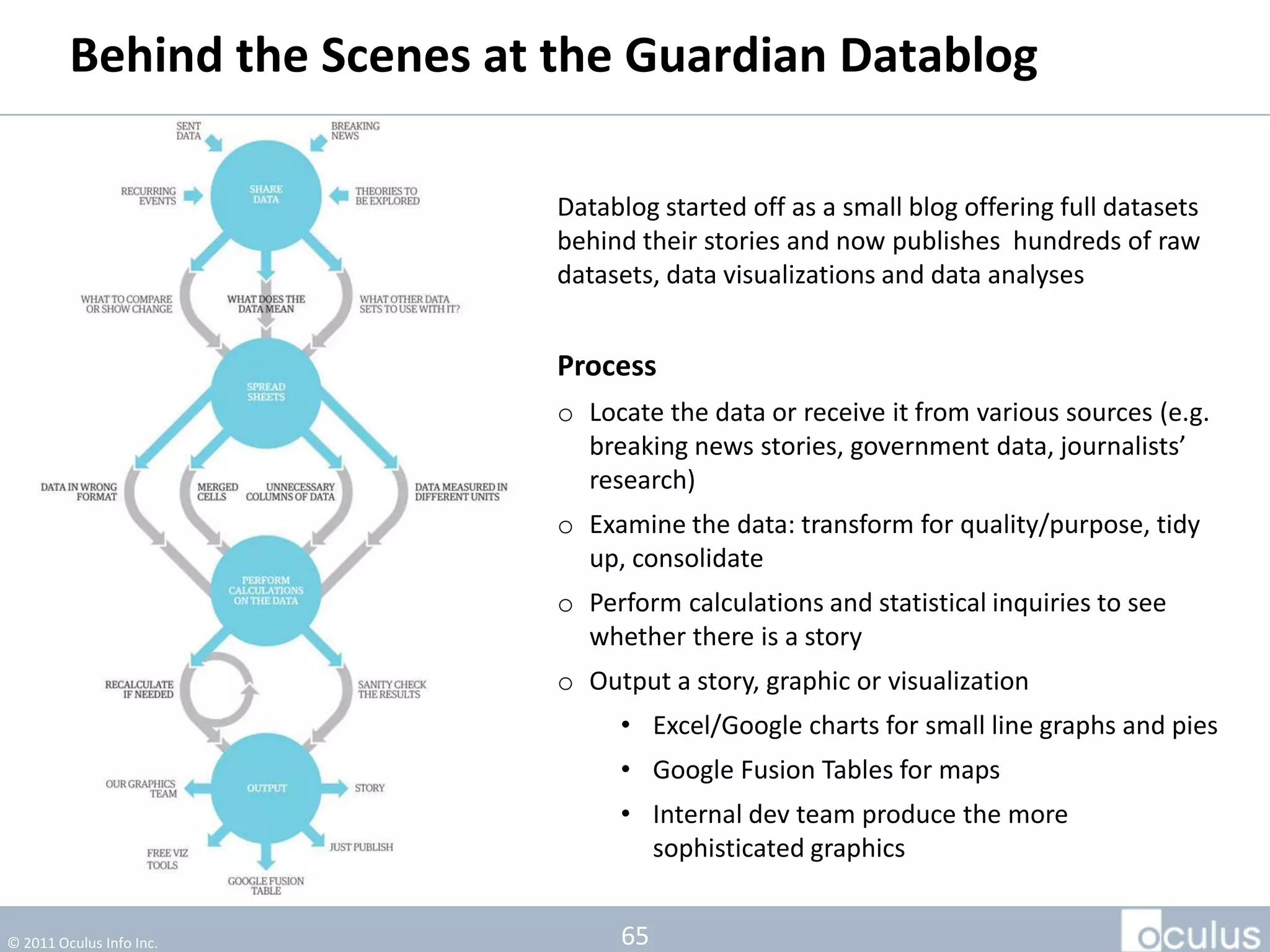
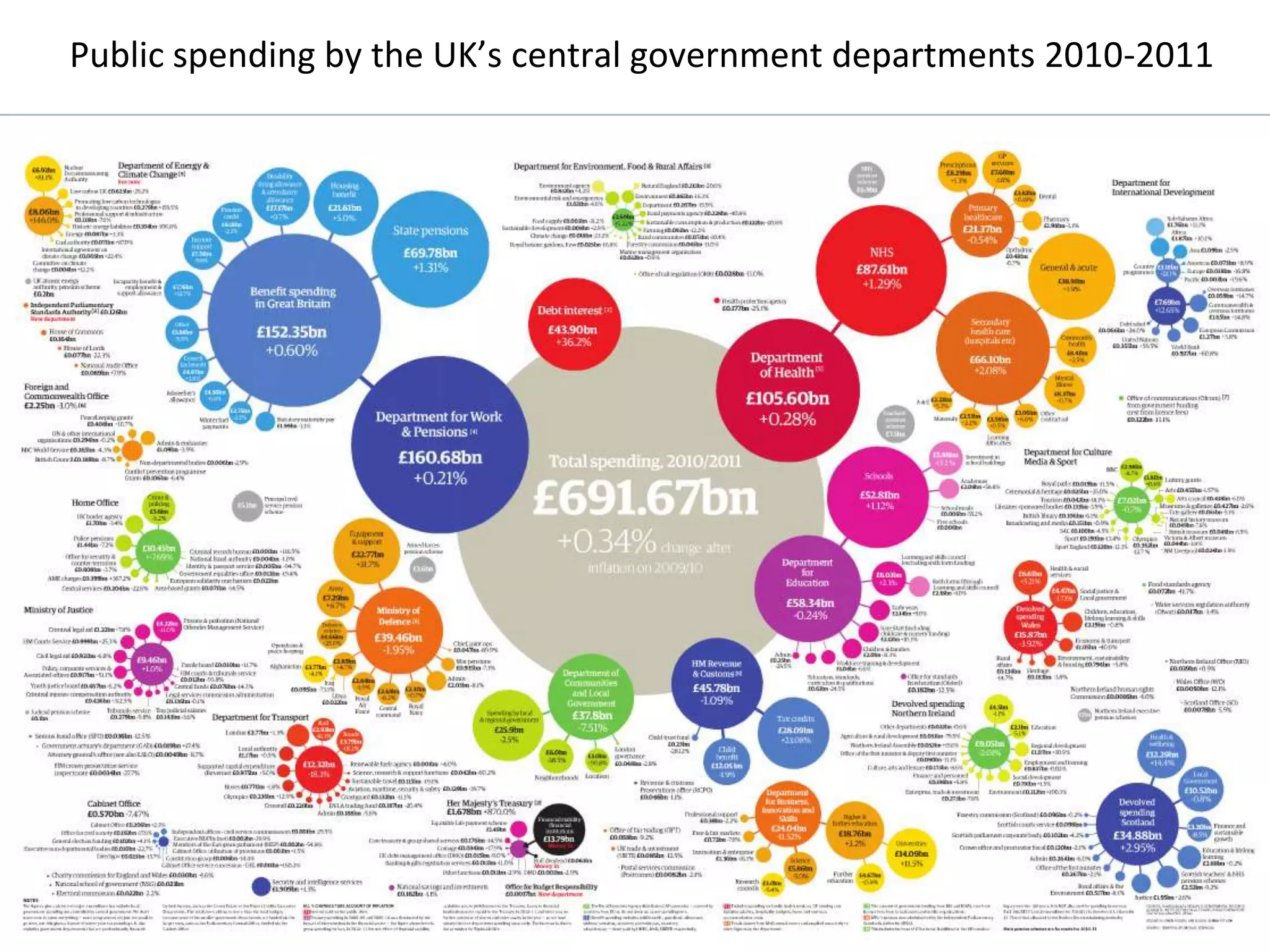
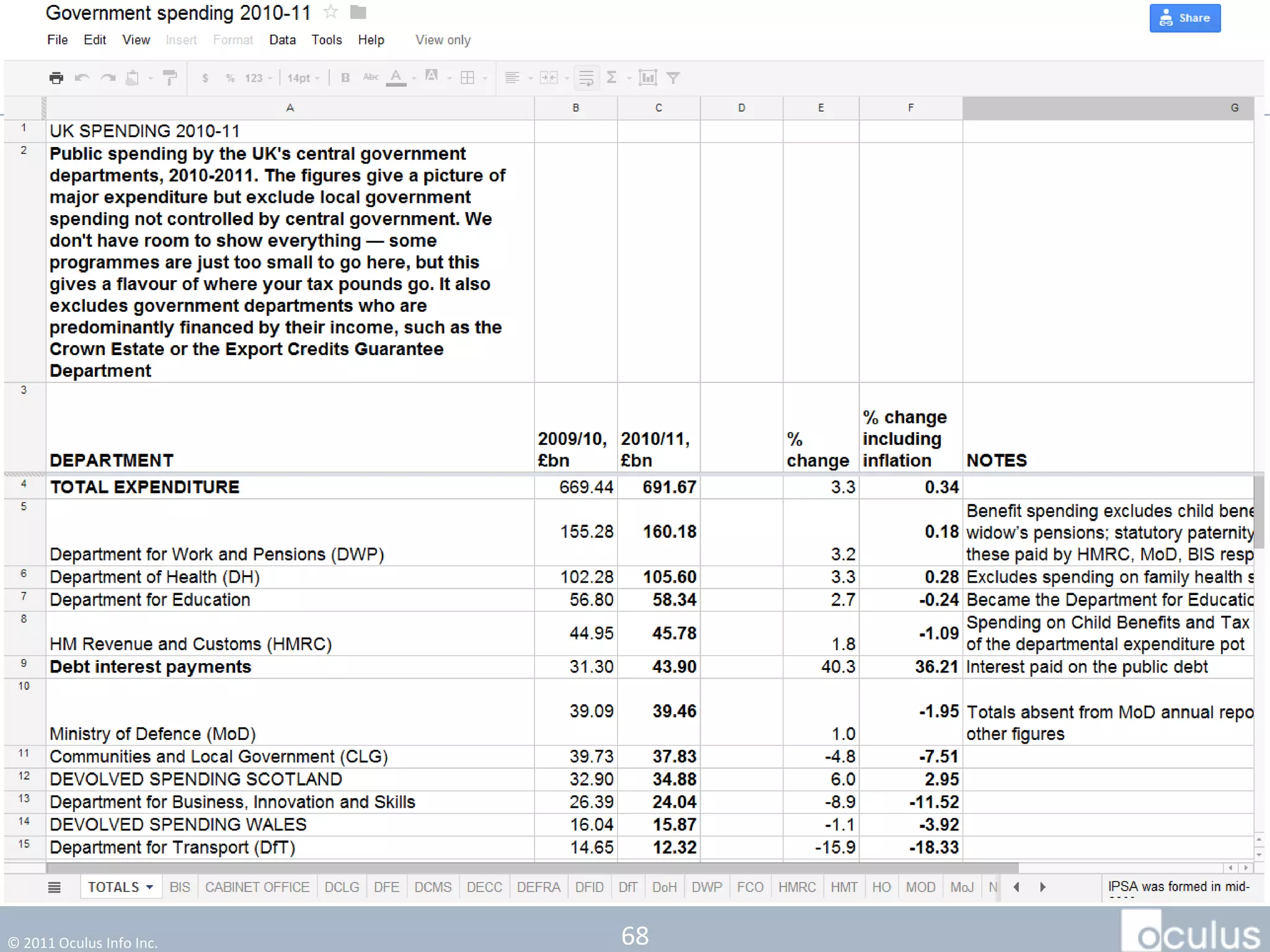
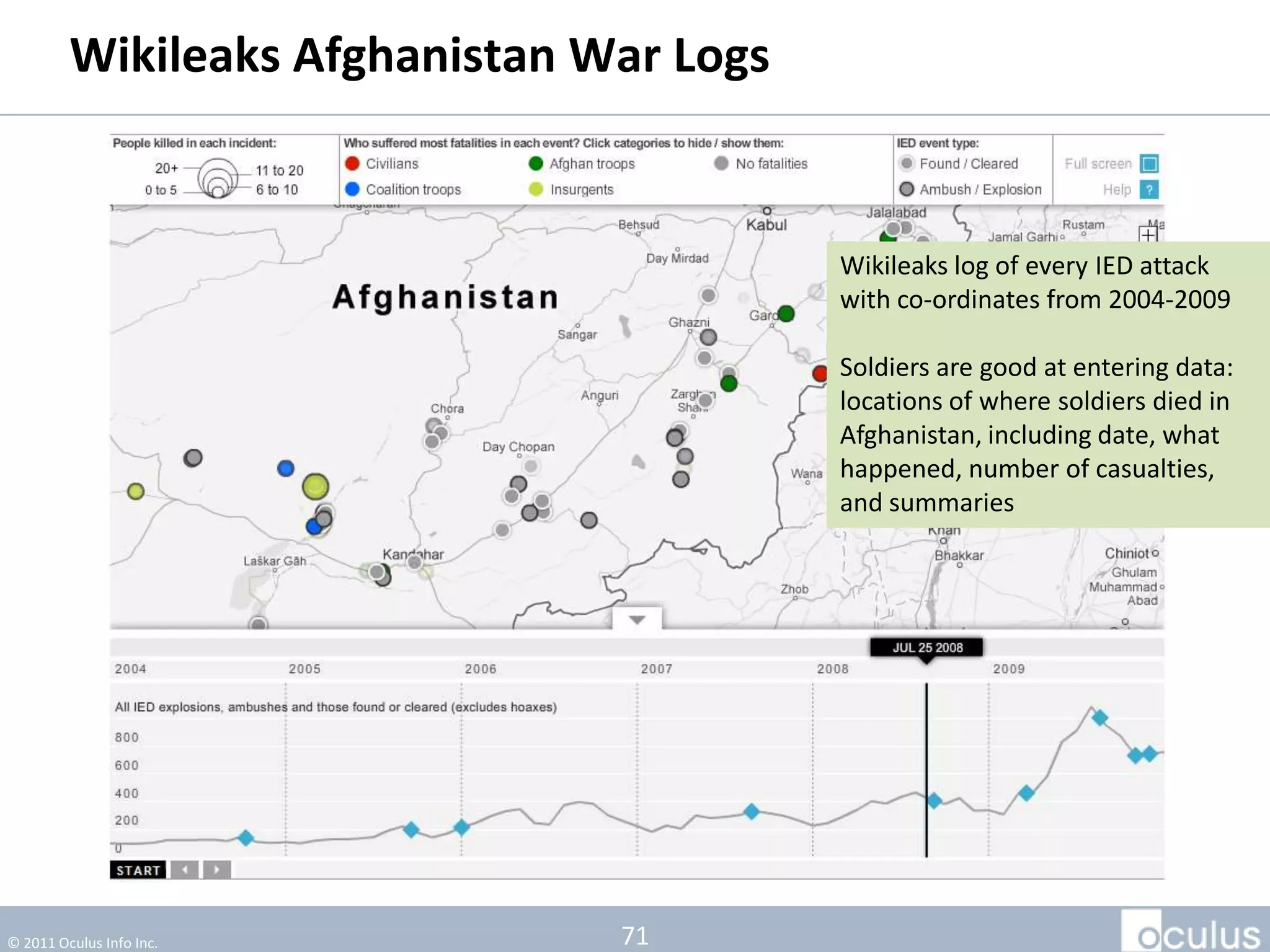
The document discusses the history and process of data journalism at the Guardian Datablog. It describes how the Datablog started as a small blog publishing underlying datasets for stories and has grown to publish hundreds of datasets, visualizations, and analyses. The process involves locating data, examining it for quality, performing calculations to identify potential stories, and publishing stories, graphics, or visualizations using tools like Excel, Fusion Tables, and custom graphics developed internally. It notes that the first example of data journalism at the Guardian was a 1821 table of school data in Manchester that revealed inaccuracies in official statistics and caused a large reaction.




































































![[BROCHURE] Italy Tour Project | @SlideON](https://cdn.slidesharecdn.com/ss_thumbnails/brochure8-251215152319-2805af68-thumbnail.jpg?width=640&height=640&fit=bounds)

















