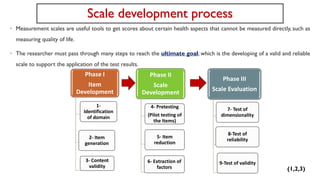
The document outlines the comprehensive steps for developing a valid and reliable scale of measurement in health research. It details the phase-wise process, including item development, scale evaluation, and testing of validity and reliability, with specific methodologies such as content validity and factor analysis. An example involving the development of a stress scale for pregnant women in a South Asian context illustrates the application of these steps.







![ContentValidity Ratio (CVR):
• The experts are requested to specify whether an item is necessary for the construct or not.
-Score 1 for: [not necessary] item.
-Score 2 for: [useful but not essential] item.
- Score 3 for: [essential] item.
.
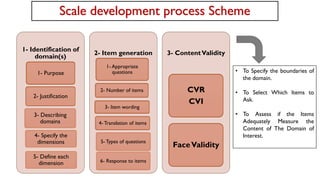
Phase 1: Item development
Step 3: ContentValidity
(Number of experts indicating essential - The
total number of experts/2) / The total number
of experts / 2.
• For minimum number of expert (5 or 6 experts) CVR must be not
less than 0.99,
• for 8 experts not less than 0.85
• for 10 experts not less than 0.62
otherwise the item should be eliminated from the scale .
CVR
(13)](https://image.slidesharecdn.com/copyofstepsindevelopingavalidandreliablescale-230325215322-e631c17e/85/Steps-in-Developing-A-Valid-and-Reliable-Scale-pdf-13-320.jpg)
![Content validity index (CVI):
Panel members are asked to rate instrument items in terms of clarity and relevancy to the construct on a 4-point scale:
-Score 1 for: [not relevant or not clear] items.
-Score 2 for: [somewhat relevant or item somewhat clear and need some revision] items.
-Score 3 for: [quite relevant or quite clear] items.
-Score 4 for: [highly relevant or highly clear] items
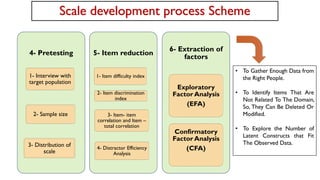
Phase 1: Item development
Step 3: ContentValidity
For each item:
Experts giving 3 or 4 score / the
Total number of experts
I-CVIs
• >79%, the item is appropriate and retained
within the scale.
• If between 70 and 79 % it will need
revision.
• <70 percent, it is eliminated from the scale
The number of relevant items by
agreement of all experts / Total
number of items
S-CVI/UA
Should be not less than 0.80
Sum of I-CVIs for the items
/ Total number of items
S-CVI/Ave
Should be not less than 0.90
(14)](https://image.slidesharecdn.com/copyofstepsindevelopingavalidandreliablescale-230325215322-e631c17e/85/Steps-in-Developing-A-Valid-and-Reliable-Scale-pdf-14-320.jpg)





































































