Downloaded 57 times







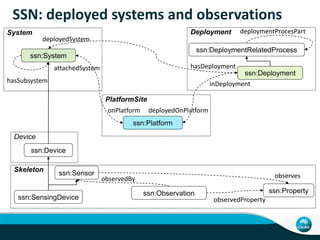


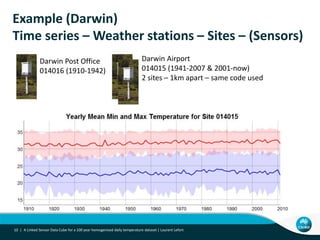
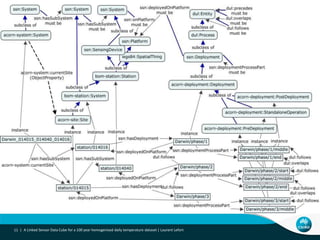

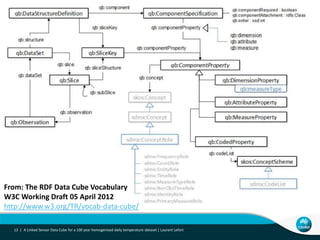
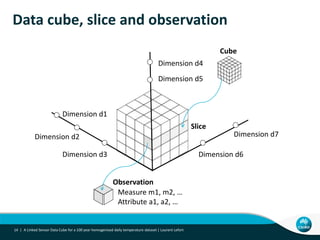
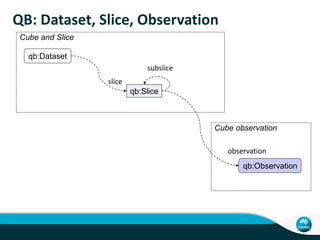

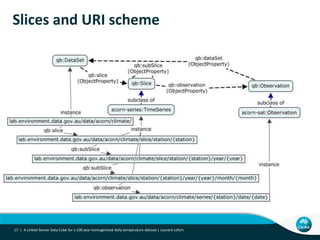



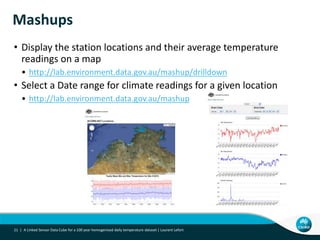






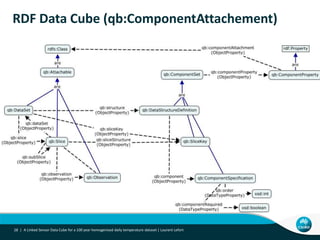


This document describes linking the ACORN-SAT climate dataset as linked open data using the Semantic Sensor Network (SSN) ontology and RDF Data Cube vocabulary. It presents the ACORN-SAT dataset, motivation for publishing it as linked data, and details how SSN is used to describe sensor deployments and observations while RDF Data Cube structures the data into observations, dimensions and measures. Lessons learned include opportunities to improve vocabularies and link additional climate and environmental datasets.














































































