기업은이런요구사항이있었습니다
클라우드 서버를 활용하여개발할 수 없는 빅데이터
소프트웨어가 있다. 이의 개발이 가능한 독립적인 서
버 환경을 달라.
01
02
03
우리 기업은 대용량 스토리지(100TB)와 고속 처리 하
드웨어(SSD, GPU 등) 인프라가 필요하다.
우리 장비는 다른 기업과는 별개의 스위치를 독립적
으로 할당해 달라. ABRC 관리자조차도 우리 서버에
는 접근하지 못하게 해달라.
7.
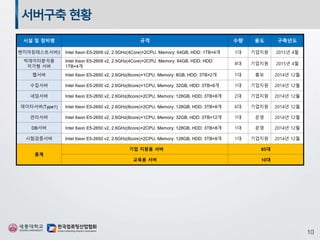
센터 인프라 현황
서버구축
인공지능-빅데이터연구센터 구축
구 분 1차년도 2차년도 3차년도 4차년도 합계
기업 지원용
서버
25대 41대 14대 5대 85대
교육용 서버 10대 - - - 10대
소재지: 세종대학교 학술정보원 7층
면적: 360m2
서버구축현황
시설 및 장비명규격 수량 용도 구축년도
GPU서버(Type3)
Intel Xeon E5-2630 v4, 2.2GHz(10core)×1CPU, Memory: 128GB, HDD: 4TB×1개,
SSD: 512GB MLC SSD, NVIDIA TESLA P100
2대 기업지원 2017년 9월
GPU서버(Type4)
Intel Xeon E5-2630 v4, 2.2GHz(10core)×1CPU, Memory: 64GB, HDD: 4TB×1개,
SSD: 512GB MLC SSD, NVIDIA TESLA P4
3대 기업지원 2017년 9월
SSD서버
Intel Xeon E5-2680 v4, 2.4GHz(14core)×2CPU, Memory: 256GB, HDD: 2TB×8개,
SSD: 1TB×10개
4대 기업지원 2017년 2월
GPU서버(Type1)
Intel Xeon E5-1680 v4, 3.4GHz(8core)×1CPU, Memory: 64GB, HDD: 2TB×2개,
SSD: 256GB, NVIDIA GTX Titan X, NVIDIA GTX 1080
4대 기업지원 2017년 2월
GPU서버(Type2)
Intel Xeon E5-2630 v4, 2.2GHz(10core)×2CPU, Memory: 64GB, SSD: 256GB,
NVIDIA GTX Titan X, NVIDIA GTX 1080, Supporting up to 20GPUs
1대 기업지원 2017년 2월
데이터서버(Type6) Intel Xeon E5-2609 v4, 1.7GHz(8core)×2CPU, Memory: 64GB, HDD: 2TB×4개 5대 기업지원 2017년 2월
데이터서버(Type4) Intel Xeon E5-2697 v3, 2.6GHz(14core)×2CPU, Memory: 768GB, HDD: 4TB×16개 1대 기업지원 2016년 2월
데이터서버(Type5)
Intel Xeon E5-2680 v3, 2.5.GHz(12core)×2CPU, Memory: 256GB, HDD:
2TB×16개
3대 기업지원 2016년 2월
테스트서버 Intel Xeon E5-2620 v3, 2.4GHz(6core)×1CPU, Memory: 8GB, HDD: 1TB 2대 기업지원 2016년 2월
데이터서버(Type2) Intel Xeon E5-2630 v3, 2.4GHz(8core)×2CPU, Memory: 128GB, HDD: 1TB×8개 10대 기업지원 2016년 1월
데이터서버(Type3) Intel Xeon E5-2630 v3, 2.4GHz(8core)×2CPU, Memory: 64GB, HDD: 1TB×4개 25대 기업지원 2016년 1월
교육용서버 Intel Xeon 4 Core E3-1220v3 3.1GHz×1CPU, Memory: 8GB, HDD: 1TB 10대 교육 2015년 4월
벤치마킹테스트서버1 Intel Xeon E5-2640 v3, 2.6GHz(8Core)×2CPU, Memory: 128GB, HDD: 1TB×4개 2대 기업지원 2015년 4월
벤치마킹테스트서버2 Intel Xeon E5-2609 v3, 1.9GHz(6Core)×2CPU, Memory: 64GB, HDD: 1TB×4개 1대 기업지원 2015년 4월
10.
서버구축현황
시설 및 장비명규격 수량 용도 구축년도
벤치마킹테스트서버3 Intel Xeon E5-2609 v2, 2.5GHz(4Core)×2CPU, Memory: 64GB, HDD: 1TB×4개 1대 기업지원 2015년 4월
빅데이터분석용
저가형 서버
Intel Xeon E5-2609 v2, 2.5GHz(4Core)×2CPU, Memory: 64GB, HDD: HDD:
1TB×4개
8대 기업지원 2015년 4월
웹서버 Intel Xeon E5-2650 v2, 2.6GHz(8core)×1CPU, Memory: 8GB, HDD: 3TB×2개 1대 홍보 2014년 12월
수집서버 Intel Xeon E5-2650 v2, 2.6GHz(8core)×1CPU, Memory: 32GB, HDD: 3TB×8개 1대 기업지원 2014년 12월
네임서버 Intel Xeon E5-2650 v2, 2.6GHz(8core)×2CPU, Memory: 128GB, HDD: 3TB×8개 2대 기업지원 2014년 12월
데이터서버(Type1) Intel Xeon E5-2650 v2, 2.6GHz(8core)×2CPU, Memory: 128GB, HDD: 3TB×8개 6대 기업지원 2014년 12월
관리서버 Intel Xeon E5-2650 v2, 2.6GHz(8core)×1CPU, Memory: 32GB, HDD: 3TB×12개 1대 운영 2014년 12월
DB서버 Intel Xeon E5-2650 v2, 2.6GHz(8core)×2CPU, Memory: 128GB, HDD: 3TB×8개 1대 운영 2014년 12월
시험검증서버 Intel Xeon E5-2650 v2, 2.6GHz(8core)×2CPU, Memory: 128GB, HDD: 3TB×8개 1대 기업지원 2014년 12월
총계
기업 지원용 서버 85대
교육용 서버 10대
11.
센터장비지원단계별목표
4차
년도
지원서버수: 85대
지원기업수: 25개
장비가동률:90%
3차
년도
지원서버수: 80대
지원기업수: 19개
장비가동률: 88.0%
2차
년도
지원서버수: 66대
지원기업수: 18개
장비가동률: 90.5%
1차
년도
지원서버수: 14대
지원기업수: 2개
장비가동률: 82.8%
인프라구축
지원
성장•확대
안정화
12.
기업맞춤형장비지원
가상서버와 물리서버의 장점을혼합한
사용자 맞춤형 하이브리드 구성
고객 전용 프라이빗 클라우드
혹은 서버 가상화 환경 구성
물리서버의 안정적이며 높은 성능을
활용한 구성
SDX(Software Defined Everything)
환경 구성
13.
국내IDC센터vs.AWSvs.ABRC
서버지원형태 서버지원형태 세부분류국내 IDC 센터
아마존 웹 서비스 (AWS
)
ABRC
기업 맞춤형
빅데이터
플랫폼 구축 지원
고사양 서버 지원 △ △ ○
기업 맞춤형 빅데이터 플랫폼 구성 ⅹ ⅹ ○
빅데이터 플랫폼 전문인력 지원 ⅹ △ ○
물리적 서버 지원 ○ ⅹ ○
클라우드 형태의 빅데이터 테스트 환경 지원 ⅹ ○ ○
빅데이터 퍼포먼스 서포팅 서비스 ⅹ ⅹ ○
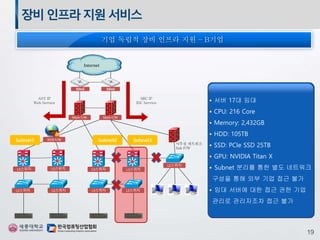
장비인프라지원서비스
• 서버 6대임대
• 기업의 클라우드 솔루션을 이용하여 가상화 환경 구축
• 가상머신을 이용한 빅데이터 교육 플랫폼 구축
• 교육 진도에 맞춰 개인별 가상머신과 빅데이터 플랫폼을 생성하고 삭제할 수 있음
Cluster Group
VirtualizationVirtual
Machine
Group
Virtual
Machine
장비인프라지원서비스
Internet
ANY IP
Web Service
SRCIP
IDC Service
DDoS DDoS
WEB F/W
L2스위치 L2스위치 L2스위치 L2스위치
L3스위치 L3스위치
L2스위치
사무실 네트워크
Sub F/W
Main F/W Main F/W
L3스위치L3스위치
Subnet3Subnet2Subnet1
• 서버 17대 임대
• CPU: 216 Core
• Memory: 2,432GB
• HDD: 105TB
• SSD: PCIe SSD 25TB
• GPU: NVIDIA Titan X
• Subnet 분리를 통한 별도 네트워크
구성을 통해 외부 기업 접근 불가
• 임대 서버에 대한 접근 권한 기업
관리로 관리자조차 접근 불가
20.
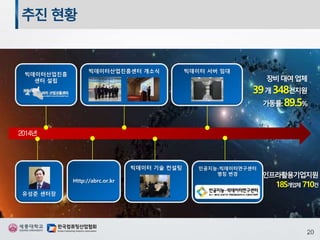
추진 현황
빅데이터산업진흥
센터 설립
유성준센터장
빅데이터산업진흥센터 개소식
Http://abrc.or.kr
빅데이터 서버 임대
빅데이터 기술 컨설팅 인공지능-빅데이터연구센터
명칭 변경
장비지원현황(2017년)
2017년도 장비 가동률:86.1% 지원 기업 수: 20개 기업
7
12
11
12
13
9
16 16 16
18
85 86
69
75
100 100
86 86 86 86
0
2
4
6
8
10
12
14
16
18
20
0
10
20
30
40
50
60
70
80
90
100
1월 2월 3월 4월 5월 6월 7월 8월 9월 10월
장비가동률과 장비 지원 기업 수
23.
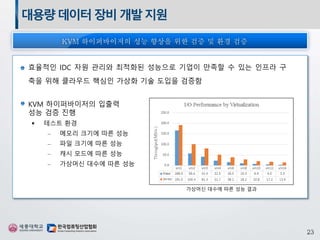
대용량데이터장비개발지원
KVM 하이퍼바이저의 입출력
성능검증 진행
테스트 환경
‒ 메모리 크기에 따른 성능
‒ 파일 크기에 따른 성능
‒ 캐시 모드에 따른 성능
‒ 가상머신 대수에 따른 성능
효율적인 IDC 자원 관리와 최적화된 성능으로 기업이 만족할 수 있는 인프라 구
축을 위해 클라우드 핵심인 가상화 기술 도입을 검증함
가상머신 대수에 따른 성능 결과
24.
대용량데이터장비개발지원
virt-manager를 통한 자원사용 현황
가상머신의 자원 사용률을 실시간으로
확인이 가능 함
KVM 기반의 로그 수집기 개발
휘발성인 virt-manager의 사용률을 수
집하여 과거 이력으로 저장함
이를 통해 가상머신의 사용률에 대한
통계와 예측이 가능함
25.
대용량데이터장비테스트서비스제공
기업에서 수집하는 막대한양의 빅데이터를 관리하고 머신러닝과 데이터마이닝
을 지원하기 위해 빅데이터 분야의 다양한 플랫폼을 구축하고 이를 검증함
호튼웍스 데이터 플랫폼을 통한
빅데이터 처리 환경 구축
지원 서비스
‒ Hadoop, Spark, Hive, Pig,
Sqoop, HBase …
‒ GUI 환경의 웹 콘솔 제공
‒ 실시간 자원 모니터링






















![인공지능-빅데이터연구센터[ABRC] 산학협력사례집](https://cdn.slidesharecdn.com/ss_thumbnails/random-171113042049-thumbnail.jpg?width=640&height=640&fit=bounds)







![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)



![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[중소기업형 인공지능/빅데이터 기술 심포지엄] 대용량 거래데이터 분석을 위한 서버인프라 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/6-180918045307-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016 데이터 그랜드 컨퍼런스] 2 2(빅데이터). skt beyond big data](https://cdn.slidesharecdn.com/ss_thumbnails/2-2-161125005000-thumbnail.jpg?width=640&height=640&fit=bounds)

![[코세나, kosena] 빅데이터 기반의 End-to-End APM과 비정형 데이터 분석 자료입니다.](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataapmunstructureddata-140604123332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[giip] A.I. Infrastructure Advisor (인공지능 인프라 어드바이저)](https://cdn.slidesharecdn.com/ss_thumbnails/giip-ai-slideshare-161227-161227065053-thumbnail.jpg?width=640&height=640&fit=bounds)


![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










![[2018 Bigdata win-win conference] 2](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference2-181126075214-thumbnail.jpg?width=640&height=640&fit=bounds)






![[중소기업형 인공지능/빅데이터 기술 심포지엄] LSTM기반 가스 배관 안전도 예측 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/4-180918044844-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 데이터 전처리 기법 및 도구](https://cdn.slidesharecdn.com/ss_thumbnails/2-180918044401-thumbnail.jpg?width=640&height=640&fit=bounds)

![[중소기업형 인공지능/빅데이터 기술 심포지엄] 온라인 고객 리뷰 빅데이터 신뢰도,방향성 분석 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/7-180918045439-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 머신러닝 기반 군 전력장비 수리부속/장비수요 예측시스템](https://cdn.slidesharecdn.com/ss_thumbnails/5-180918045000-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 워드벡터를 활용한 관광지 리뷰 분석시스템](https://cdn.slidesharecdn.com/ss_thumbnails/3-180918044635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 5](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference5-181126075632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 국내 인공지능-빅데이터 산업의 문제점 및 해결방안](https://cdn.slidesharecdn.com/ss_thumbnails/1-180918043612-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018 Bigdata win win conference] 1](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference1-181126075052-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 4](https://cdn.slidesharecdn.com/ss_thumbnails/4-181127005320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 3](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference3-181126075308-thumbnail.jpg?width=640&height=640&fit=bounds)