Pivot3는 더 스마트한인프라를 제공.
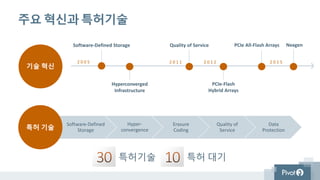
검증된 혁신기술
• 소프트웨어 정의 스토리지
• 서비스품질
• 플래시 어레이 아키텍쳐
30 특허기술
53개국, 3000여 고객사
광범위한 기술제휴
BOULDER
MEXICO CITY
AUSTIN
HOUSTON
LONDON
DUBAI
SINGAPORE
SEOUL
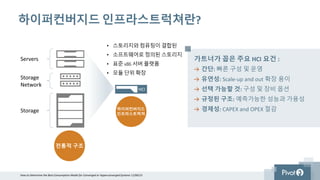
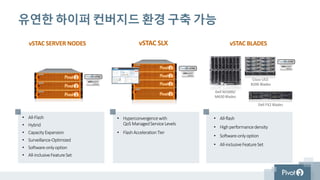
하이퍼컨버지드 인프라스트럭쳐란?
가트너가 꼽은주요 HCI 요건 :
간단: 빠른 구성 및 운영
유연성: Scale-up and out 확장 용이
선택 가능할 것: 구성 및 장비 옵션
규정된 구조: 예측가능한 성능과 가용성
경제성: CAPEX and OPEX 절감
How to Determine the Best Consumption Model for Converged or Hyperconverged Systems 11/06/15
HCI
Servers
Storage
Network
Storage
• 스토리지와 컴퓨팅이 결합된
• 소프트웨어로 정의된 스토리지
• 표준 x86 서버 플랫폼
• 모듈 단위 확장
전통적 구조
하이퍼컨버지드
인프라스트럭쳐
6.
선두기업은 hyper scale방식의 업무 모델을 생각합니다.
지역적 Erasure
coding
Erasure coding은 구글 아마존 같은 Hyper scale 회사에 적용하는 핵심
데이터 보호기술 입니다.
Erasure coding은 RAID 6 보다 10,000 배 이상의 안정성이
있으며, Peta Byte규모의 데이터를 유지하기 위한 유일한 방법입니다.
Pivot3는 기존 Erasure Coding기술에 응답시간을 개선한 Scalar
Erasure Coding 을 하이퍼 컨버지드 인프라에 적용하여 높은
효율과 극한의 안정성을 보장합니다.
어플라이언스
Erasure Coding
여타 HCI는 mirror방식만을 사용하지만
Pivot3는 모든 노드의 모든 디스크를 전부 사용합니다.
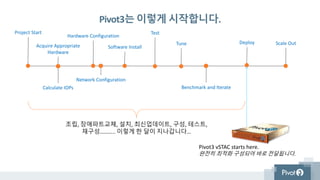
Pivot3는 이렇게 시작합니다.
조립,장애파트교체, 설치, 최신업데이트, 구성, 테스트,
재구성……….. 이렇게 한 달이 지나갑니다…
Pivot3 vSTAC starts here.
완전히 최적화 구성되어 바로 전달됩니다.
Project Start
Acquire Appropriate
Hardware
Calculate IOPs
Hardware Configuration
Network Configuration
Software Install
Test
Tune
Benchmark and Iterate
Deploy Scale Out
9.
Pivot3 – 좀더 스마트한 인프라 솔루션
더 나은 결과
고가용성이
보장된 플랫폼
Hyperconverged Infrastructure and Flash Storage
중요한 것을
우선 처리
10.
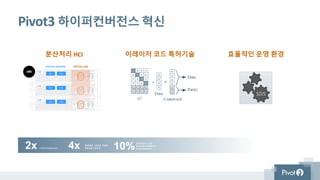
Pivot3 하이퍼컨버전스 혁신
PE R F O R M A N C E2x M O R E I O P S P E R
D E S K T O P S4x O P E R A T I N G
E N V I R O N M E N T
O V E R H E A D10%
분산처리 HCI 이레이저 코드 특허기술 효율적인 운영 환경
SDS
VIRTUAL SERVERS VIRTUAL SAN
VM VM
VM VM
VM VM
x86
11.
더 높은 효과를보장
VIRTUAL SERVERS VIRTUAL SAN
VM VM
VM VM
VM VM
VM VM
x86
Hyperconverged Infrastructure
필요에 따라 표준 x86서버를 늘려가는
유연한 아키텍쳐
모듈방식
x86 Nodes
극대화된 자원 효율성을 위해
스토리지와 컴퓨팅을 동시에
확장하는 분산 Scale-out 구조
분산
Scale-out
7% 의 시스템 리소스만을 사용하는
효율적인 HCI
효율적인
운영환경
12.
고성능이 유지되는 고가용환경
Hyperconverged Infrastructure
최대 94% utilization 제공하는 유연한
데이터보호 기술
99.9999%의 데이터 안정성
특허 기술
Erasure
Coding
장애시에도
85%이상의 성능을 보장하면서
고 가용성을 보장
Availability
With
Performance
VIRTUAL SERVERS
VM VM
VM VM
VM VM
VM VM
x86
VIRTUAL SAN
Raid 1
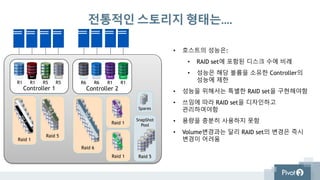
전통적인 스토리지형태는….
• 호스트의 성능은:
• RAID set에 포함된 디스크 수에 비례
• 성능은 해당 볼륨을 소유한 Controller의
성능에 제한
• 성능을 위해서는 특별한 RAID set을 구현해야함
• 쓰임에 따라 RAID set을 디자인하고
관리하여야함
• 용량을 충분히 사용하지 못함
• Volume변경과는 달리 RAID set의 변경은 즉시
변경이 어려움
Raid 1
Raid 5
Raid 6
Raid 1
Raid 5
SnapShot
Pool
Spares
Controller 1
R1 R1 R5R5
Vol 0 Vol 1 Vol 2 Vol 3
Controller 2
R6R6 R1R1
Vol 4 Vol 5 Vol 6 Vol 7
16.
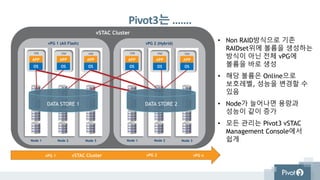
vSTAC Cluster
Pivot3는 …….
•Non RAID방식으로 기존
RAIDset위에 볼륨을 생성하는
방식이 아닌 전체 vPG에
볼륨을 바로 생성
• 해당 볼륨은 Online으로
보호레벨, 성능을 변경할 수
있음
• Node가 늘어나면 용량과
성능이 같이 증가
• 모든 관리는 Pivot3 vSTAC
Management Console에서
쉽게
vSTAC ClustervPG 1 vPG 2 vPG n
Node 1 Node 2 Node 3
VM VM VM
vPG 1 (All Flash)
APP
OS
APP
OS
APP
OS
Node 1 Node 2 Node 3
VM VM VM
vPG 2 (Hybrid)
APP
OS
APP
OS
APP
OS
DATA STORE 1 DATA STORE 2
17.
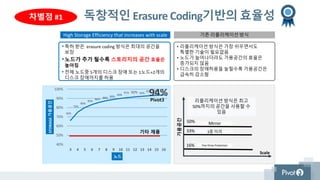
독창적인 Erasure Coding기반의효율성
66%
75%
80%
83%
86% 88% 89%
90%
91% 92% 92%
93% 93%
94%
40%
50%
60%
70%
80%
90%
100%
3 4 5 6 7 8 9 10 11 12 13 14 15 16
STORAGE가용공간
노드
• 특허 받은 erasure coding 방식은 최대의 공간을
보장
•노드가 추가 될수록 스토리지의 공간 효율은
높아짐
• 전체 노드중 5개의 디스크 장애 또는 1노드+2개의
디스크 장애까지를 허용
High Storage Efficiency that increases with scale
리플리케이션 방식은 최고
50%까지의 공간을 사용할 수
있음
가용공간
Scale
Mirror50%
33%
16%
• 리플리케이션 방식은 가장 쉬우면서도
특별한 기술이 필요없음
• 노드가 늘어나더라도 가용공간의 효율은
증가되지 않음
• 디스크의 장애허용을 늘릴수록 가용공간은
급속히 감소함
기존 리플리케이션 방식
3중 미러
Five Drive Protection
차별점 #1
Pivot3
기타 제품
18.
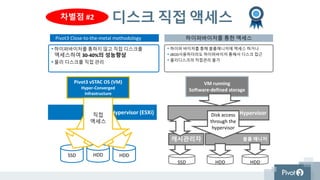
볼륨 매니저
디스크 직접액세스
하이퍼바이저를 통한 액세스
Hypervisor (ESXi)
HDD
Pivot3 vSTAC OS (VM)
Hyper-Converged
Infrastructure
•Pivot3 Close-to-the-metal methodology
• 하이퍼바이저를 통하지 않고 직접 디스크를
액세스하여 30-40%의 성능향상
• 물리 디스크를 직접 관리
Hypervisor
SSD
VM running
Software-defined storage
Disk access
through the
hypervisor
• 하이퍼 바이저를 통해 볼륨매니저에 액세스 하거나
• JBOD사용하더라도 하이퍼바이저 통해서 디스크 접근
• 물리디스크의 직접관리 불가
차별점 #2
HDD HDD
HDDSSD
직접
액세스
캐시관리자
19.
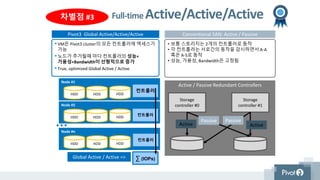
Full-time Active/Active/Active
Pivot3 GlobalActive/Active/Active Conventional SAN: Active / Passive
Active / Passive Redundant Controllers
Storage
controller #0
Storage
controller #1
Passive
Active
Passive
Active
• VM은 Pivot3 cluster의 모든 컨트롤러에 액세스가
가능
• 노드가 추가될때 마다 컨트롤러의 성능+
가용성+Bandwidth이 선형적으로 증가
• True, optimized Global Active / Active.
• 보통 스토리지는 2개의 컨트롤러로 동작
• 각 컨트롤러는 서로간의 동작을 감시하면서 A-A
혹은 A-S로 동작
• 성능, 가용성, Bandwidth은 고정됨
Node #1
HDD HDD HDD
Node #n
HDD HDD HDD
Node #2
HDD HDD HDD
컨트롤러
컨트롤러
컨트롤러
∑ (IOPs)Global Active / Active =>
차별점 #3
20.
Global Virtual DriveSparing
Pivot3 Virtual Global Sparing Conventional sparing system
Appliance #1
HDD
Spare
HDD
• 전통방식의 스페어는 각 노드마다 하나씩의
스페어를 할당하여 디스크 장애에 대비함
• HDD 전체 성능은 디스크수-스페어수 (ex 900 IOPS)
• HDD장애시 해당 노드의 모든 HDD가 리빌딩에 참여하여
정상적인 성능을 낼 수 없음
• 각 노드마다 스페어 디스크를 미리 지정하지 않고
전체 노드에 스페어 공간을 가상으로 배정
• Pivot3 클러스터에 하나의 디스크 공간만큼만
소비됨
• HDD의 장애가 발생 하더라도 성능의 저하 없이
복구되며 수동작업은 전혀 불필요
• HDD장애시 모든 노드의 HDD가 작업을 나눠서
조금씩 리빌딩에 참여 성능의 저하가 없음
HDD HDD
Appliance #2
HDD
Spare
HDD
HDD HDD
Appliance #n
HDD
Spare
HDD
HDD HDD
Pivot3 Re-positioning
차별점 #4
Appliance #1
HDD HDD HDD HDD
Virtual sparing
Appliance #n
HDD HDD HDD HDD
Virtual sparing
Appliance #2
HDD HDD HDD HDD
Virtual sparing
21.
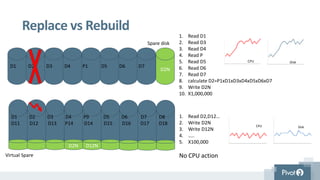
Spare disk
1. ReadD1
2. Read D3
3. Read D4
4. Read P
5. Read D5
6. Read D6
7. Read D7
8. calculate D2=P1xD1xD3xD4xD5xD6xD7
9. Write D2N
10. X1,000,000
Virtual Spare
1. Read D2,D12…
2. Write D2N
3. Write D12N
4. …..
5. X100,000
No CPU action
D2N
D2N D12N
CPU Disk
CPU Disk
D1 D2 D3 D4 P1 D5 D6 D7
Replace vs Rebuild
D1 D2 D3 D4 P9 D5 D6 D7 D8
D11 D12 D13 P14 D14 D15 D16 D17 D18
22.
HDD 응답 시간
HDD1Drive 2 HDD3
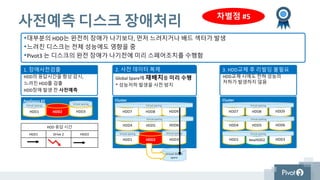
사전예측 디스크 장애처리
•대부분의 HDD는 완전히 장애가 나기보다, 먼저 느려지거나 배드 섹터가 발생
•느려진 디스크는 전체 성능에도 영향을 줌
•Pivot3 는 디스크의 완전 장애가 나기전에 미리 스페어조치를 수행함
Cluster
HDD7
Appliance #3
Virtual Global
spare
HDD4
HDD1
HDD8
HDD5
HDD2
HDD9
HDD6
HDD3
Virtual sparing
STEP 2
Global Spare에 재배치를 미리 수행
* 성능저하 발생을 사전 방지
2. 사전 데이터 복제STEP 1
HDD의 응답시간을 항상 감시,
느려진 HDD를 검출
HDD장애 발생 전 사전예측
1. 장애사전검출 STEP 3
HDD교체 시에도 전혀 성능의
저하가 발생하지 않음
3. HDD교체 후 리빌딩 불필요
Cluster
HDD7
HDD4
HDD1
HDD8
HDD5
HDD9
HDD6
HDD3NewHDD2
HDD1 HDD2 HDD3
Virtual sparing
Virtual sparing
Virtual sparing Virtual sparing
Virtual sparing
Virtual sparing
Virtual sparing
Virtual sparing
차별점 #5
23.
#1 Node
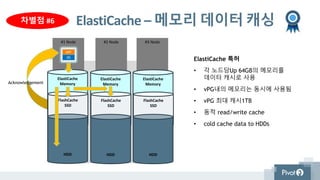
ElastiCache –메모리 데이터 캐싱
ElastiCache 특허
• 각 노드당Up 64GB의 메모리를
데이터 캐시로 사용
• vPG내의 메모리는 동시에 사용됨
• vPG 최대 캐시1TB
• 동적 read/write cache
• cold cache data to HDDs
#3 Node#2 Node
ElastiCache
Memory
FlashCache
SSD
HDD
ElastiCache
Memory
FlashCache
SSD
HDD
ElastiCache
Memory
FlashCache
SSD
HDD
Acknowledgement
APP
OS
차별점 #6
24.
Node 1 Node2 Node 3
VM VM VM
vPG (Hybrid)
APP
OS
APP
OS
APP
OS
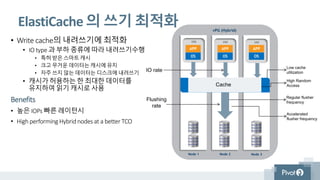
ElastiCache 의 쓰기 최적화
• Write cache의 내려쓰기에 최적화
• IO type 과 부하 종류에 따라 내려쓰기수행
• 특허 받은 스마트 캐시
• 크고 무거운 데이터는 캐시에 유지
• 자주 쓰지 않는 데이터는 디스크에 내려쓰기
• 캐시가 허용하는 한 최대한 데이터를
유지하여 읽기 캐시로 사용
Benefits
• 높은 IOPs 빠른 레이턴시
• High performing Hybrid nodes at a better TCO
Regular flusher
frequency
Flushing
rate
Accelerated
flusher frequency
IO rate
Low cache
utilization
Cache
High Random
AccessCache
25.
Flexible Deployment Options
Node1 Node 2 Node 3
Data
Only
vPG
VM
APP
OSVM
APP
OS
VM
APP
OS
VM
APP
OSVM
APP
OS
VM
APP
OS
VM
APP
OSVM
APP
OS
VM
APP
OS
Node 4
Only the drive types/sizes need to be the same
스토리지의 증설은:
• CPU 성능, 개수에 무관
• 메모리 용량에 무관
• 필요에 따라 증설
모델 All-flash HCI Watch Data
Compute
Latency
용량
어떠한 요구에도 대응할 수 있는 유연한
모델 선택의 자유
All-flash : 가장 빠른 응답시간
HCI : 일반적인 가상화, VDI
Watch : 많은 용량이 요구되는 서비스
Data : 기존환경에 용량만 증설
26.
Hybrid / Watch/DATA
12 X 3.5 in drives
Sizes range from:
1 TB = 12 TB Node
2 TB = 24 TB Node
4 TB = 48 TB Node
6 TB = 72 TB Node
8 TB = 96 TB Node
Watch/ DATA
1cpu, 2PCIslot
Data
No ESX
Dual 400
GB SSDs
10GB
Copper or
SFP+
10GB,
Copper or
SFP+
Power
supplies
750W
1
2 3
4
5
1- SSD cache
2- Full x16 PCI-e bay
& x8
3- low profile X8 &
X1 PCI-e slots
4- onboard USB for
usb SSD
5- Dual SD cards for
ESX install
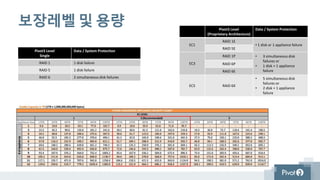
보장레벨 및 용량Pivot3 Level
(Proprietary Architecture)
Data / System Protection
EC1
RAID 1E
• 1 disk or 1 appliance failure
RAID 5E
EC3
RAID 1P • 3 simultaneous disk
failures or
• 1 disk + 1 appliance
failure
RAID 6P
RAID 6E
EC5 RAID 6X
• 5 simultaneous disk
failures or
• 2 disk + 1 appliance
failure
Pivot3 Level
Single
Data / System Protection
RAID 1 1 disk failure
RAID 5 1 disk failure
RAID 6 2 simultaneous disk failures
30.
Top Ten StorageChallenges
폐사의 IT인프라에서 스토리지에 관련된 최대 과제는 무엇입니까?
N=212 multiple responses Source: Enterprise Strategy Group, 2016
31.
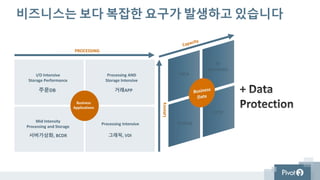
비즈니스는 보다 복잡한요구가 발생하고 있습니다
Latency
I/O Intensive
Storage Performance
주문DB
Processing AND
Storage Intensive
거래APP
Mid Intensity
Processing and Storage
서버가상화, BCDR
Processing Intensive
그래픽, VDI
Business
Applications
PROCESSING
CCTV
BI
Annalistic
Backup
Infra
32.
스토리지 미션완수
가장 빠른PCIe Flash Arrays
All-flash and hybrid
동적 QoS
사업요구에 즉시 부합하는 성능
관리의 단순화
세밀한 정책기반 관리
환상의 성능옵션!
단일서버에 300KIOPS
適材適所
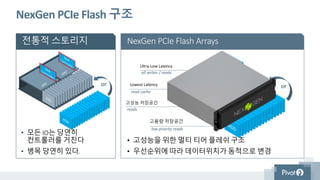
NexGen PCIe Flash구조
• 모든 IO는 당연히
컨트롤러를 거친다
• 병목 당연히 있다.
• 고성능을 위한 멀티 티어 플레쉬 구조
• 우선순위에 따라 데이터위치가 동적으로 변경
전통적 스토리지 NexGen PCIe Flash Arrays
Ultra-Low Latency
고성능 저장공간
Lowest Latency
고용량 저장공간
or or
all writes / reads
read cache
reads
low priority reads
35.
NexGen 데이터효율화 기술의효과
2.5X acceleration*
50% lower latency
Reduced IO vs. PCIe Flash IO2.5X
4X
4X SSD life extension
7:1 consolidation ratio** from PCIe Flash
writes to SSD writes
2:1
50% average capacity reduction
2:1 data reduction ratio***
No performance impact
* 2.5X acceleration based on v3.5 software benchmarks; ** 7:1 consolidation ratio based on NexGen customer measured
metrics; *** 2:1 capacity reduction based on NexGen customer measured metrics
IO 통합으로
SSD수명증가
데이터
효율화로
점유 용량감소
IO량 감소로 인한
성능향상
36.
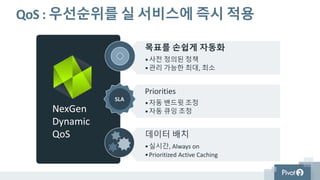
목표를 손쉽게 자동화
•사전정의된 정책
•관리 가능한 최대, 최소
Priorities
•자동 밴드윗 조정
•자동 큐잉 조정
데이터 배치
•실시간, Always on
•Prioritized Active Caching
QoS : 우선순위를 실 서비스에 즉시 적용
SLA
NexGen
Dynamic
QoS
37.
40K
30K
20K
10K
IOPS
0
40K
30K
20K
10K
IOPS
0
Service Level에 적용
•모든 데이터가 동일한
중요도로취급됨
• 서비스에부합하지 않는 성능
• Impacts business operations
별도의 스토리지
비효율적투자관리
• 업무요구에부합하는 성능
• 서비스레벨에합치
• Mission Critical 서비스는항상 보장됨
QoS 없는 스토리지 NexGen Storage QoS
! !
VM주문 DB 개발 DB
VM주문 DB 개발 DB
최고
Priority
높음
Priority
최저
Priority
38.
기정의된 QoS 정책
125,000IOPS
1000 MB/s
1 ms
75,000 IOPS
500 MB/s
3 ms
50,000 IOPS
250 MB/s
10 ms
25,000 IOPS
100 MB/s
20 ms
10,000 IOPS
50 MB/s
40 ms
100,000 IOPS
750 MB/s
5 ms
50,000 IOPS
375 MB/s
10 ms
20,000 IOPS
150 MB/s
25 ms
10,000 IOPS
75 MB/s
50 ms
2,000 IOPS
38 MB/s
100 ms
Hybrid 스토리지 All-Flash 스토리지
39.
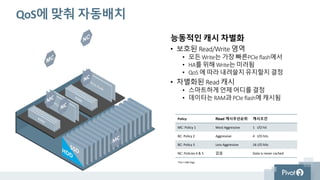
QoS에 맞춰 자동배치
능동적인캐시 차별화
• 보호된 Read/Write 영역
• 모든 Write는 가장 빠른PCIe flash에서
• HA를 위해 Write는 미러됨
• QoS 에 따라 내려쓸지유지할지결정
• 차별화된 Read 캐시
• 스마트하게 언제 어디를 결정
• 데이터는RAM과 PCIe flash에 캐시됨
Policy Read 캐시우선순위 캐시조건
MC: Policy 1 Most Aggressive 1 I/O hit
BC: Policy 2 Aggressive 4 I/O hits
BC: Policy 3 Less Aggressive 16 I/O hits
NC: Policies 4 & 5 없음 Data is never cached
*Per 1 MB Page
40.
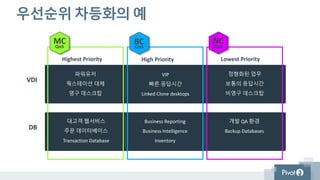
우선순위 차등화의 예
HighestPriority High Priority Lowest Priority
파워유저
웍스테이션 대체
영구 데스크탑
VIP
빠른 응답시간
Linked Clone desktops
정형화된 업무
보통의 응답시간
비영구 데스크탑
대고객 웹서비스
주문 데이터베이스
Transaction Database
Business Reporting
Business Intelligence
Inventory
개발 QA 환경
Backup Databases
VDI
DB
41.
Log Temp DBData
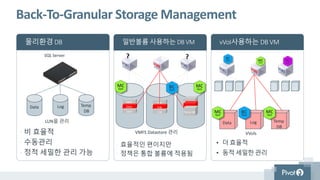
Back-To-GranularStorage Management
물리환경 DB 일반볼륨 사용하는 DB VM vVol사용하는 DB VM
VMFS Datastore 관리
• 더 효율적
• 동적 세밀한 관리
SQL Server
Log Temp DBData
Log Temp DBData
• 효율적인 편이지만
• 정책은 통합 볼륨에 적용됨
• 비 효율적
• 수동관리
• 정적 세밀한 관리 가능
VVols
Data Log Temp
DB
Data Log Temp
DB
LUN을 관리
? ?
42.
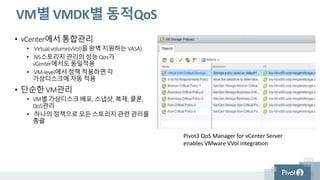
VM별 VMDK별 동적QoS
•vCenter에서 통합관리
• Virtual volume(vVol)을 완벽 지원하는 VASA)
• N5스토리지관리의 성능 Qos가
vCenter에서도동일적용
• VM-level에서 정책 적용하면각
가상디스크에자동 적용
• 단순한 VM관리
• VM별 가상디스크배포, 스냅샷, 복제, 클론,
QoS관리
• 하나의 정책으로모든 스토리지 관련 관리를
총괄
Pivot3 QoS Manager for vCenter Server
enables VMware VVol integration
43.
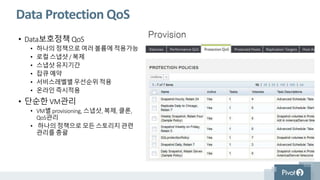
Data Protection QoS
•Data보호정책 QoS
• 하나의 정책으로 여러 볼륨에 적용가능
• 로컬 스냅샷 / 복제
• 스냅샷 유지기간
• 잡큐 예약
• 서비스레벨별우선순위 적용
• 온라인 즉시적용
• 단순한 VM관리
• VM별 provisioning, 스냅샷, 복제, 클론,
QoS관리
• 하나의 정책으로모든 스토리지 관련
관리를 총괄
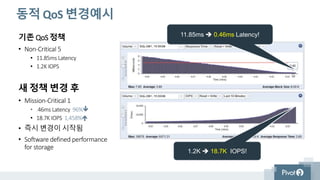
동적 QoS 변경예시
기존QoS 정책
• Non-Critical 5
• 11.85ms Latency
• 1.2K IOPS
새 정책 변경 후
• Mission-Critical 1
• .46ms Latency 96%
• 18.7K IOPS 1,458%
• 즉시 변경이 시작됨
• Software defined performance
for storage
11.85ms 0.46ms Latency!
1.2K 18.7K IOPS!
46.
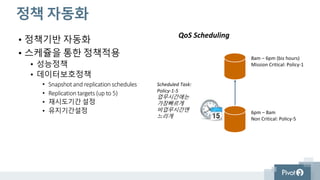
정책 자동화
• 정책기반자동화
• 스케쥴을 통한 정책적용
• 성능정책
• 데이터보호정책
• Snapshot and replication schedules
• Replication targets (up to 5)
• 재시도기간 설정
• 유지기간설정 6pm – 8am
Non Critical: Policy-5
8am – 6pm (biz hours)
Mission Critical: Policy-1
Scheduled Task:
Policy-1-5
업무시간에는
가장빠르게
비업무시간엔
느리게
QoS Scheduling
47.
HCI로의 확장
SLX =
HCI+ All flash storage + QoS
단일 플랫폼 운영
• HCI의 경제성, 표준화
• N5의 성능, 보장성
• 최고의 유연성
모든 IO 타입에 적용 가능한 인프라
• 서버통합
• VDI
• 미션 크리티컬 DB
• Archiving / Backup
• CCTV
48.
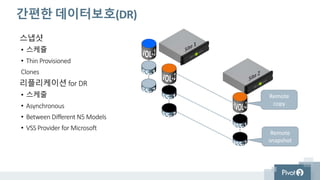
간편한 데이터보호(DR)
스냅샷
• 스케쥴
•Thin Provisioned
Clones
리플리케이션 for DR
• 스케줄
• Asynchronous
• Between Different N5 Models
• VSS Provider for Microsoft
Remote
copy
Remote
snapshot
고객만족 지원
Live Support
Expertise
•24x7x365 Availability
• 스토리지 전문가 +
가상화 전문가 지원
상시
모니터링
• 대응방안을 제시하는
알람 체계
• Phone-home Telemetry
포괄적
지원정책
• 단일 지원 접점
• 계약 기간 내 지원
비용상승 없음
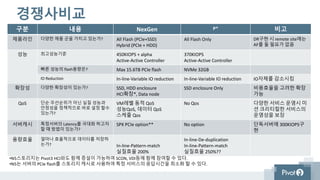
Support Offerings
• 7 day x 24 hour phone | Onsite parts
• 7 day x 24 hour phone | NBD parts
• 5 day x 9 hour phone support | NBD Parts
#7 What is Hyper-Convergence? At the most basic level
Combined storage and computing platform
Off The Shelf (OTS) Components, X86 Processors vs specialized ASICS
Delivered in a Appliance Model
Software Defined Storage – what makes this possible
X86
Lets dig a bit deeper on the X86 economics and ecosystem, because it’s one of the real drivers of HCI
As of 2014, from Gartner:
X86 servers represent 99% of the servers in terms of Units Shipped and >75% by $$$$, These % figures continue to increase year over year. This is result continual increase in capability and lower costs of X86 processors driven ever higher volumes.
Also due to competition, the Vendors have had to settle for lower margins. HP have 25% GM and Dell 23% verses IBM's >50% GM which is why they exited the X86 Server market by selling that business to Lenovo (12% GM)
HCI is bringing the same economies, same trends that have unfolded in the server world to the combined Storage & Compute environment
Caption: Modular / Scalable Architecture, Simplicity, Generalists (vs specialists), Lower TCO
Bringing the benefits that Google, Amazon, etc. have seen to the Enterprise Scale
When talking to customers that are not familiar with the concept of HC, you may need to elaborate a but further in the case where this particular definition is not 100% clear to them as they already buy servers today, which have CPU’s, Disks, Memory, and NIC’s all in a rack chassis. These could be considered as off-the-shelf since they can buy it from Dell/HP/Lenovo/whoever, and just like their fridge, it’s an appliance. "So what are you trying to tell me HC is? Isn’t that what’s in a server I am buying from Dell today?” Since the majority are users of some sort of virtual machine environment (Vmware/Hyper-V/KVM) they get that and we may be able to use that as a launching pad to describe HC as a combination of "VIRTUALIZED storage + VIRTUALIZED compute + VIRTUALIZED networking” that is put together as an appliance with the same familiar x86 technologies they currently work with. The mechanical boundaries of the appliance are transparent in a fully virtualized, or hyper-converged system. The finishing message that should be conveyed is that hyper-convergence is the brining together of all the independently virtualized resources of the data center into a simple appliance based deployment.
#25 ElastiCache has a variable cache based on the amount of reads or writes coming into ElastiCache…it is not fixed
#26 Our caching algorithms make adjustments to the flusher speeds based on IO type and IO rate. These algorithms keep our cache at an optimal state where the heavily utilized/active data remains in cache, and the cold data stages down to disk.
We have implemented cache differently than traditional storage arrays and is the main reason we get such great performance in our Hybrid arrays with SATA drives.
The speed of write cache flushing depends on many factors, obviously one of them will be IO type and IO loads. After flushing, write cache will transition to read cache (our unique implementation) and will stay as long as possible until we need to reclaim the cache for newer IOs.
#28 The 400GB MLC SSDs are used for Flash Cache. We use 25GB of capacity on each 400GB drive for Flash Cache, the remaining capacity on the drives is used for moving the Flash Cache around to extend write wear of the MLC SSD drives.
#32 IT에서 가장 어렵고도 복잡하지만 가장 변화하기 어려운 부분이 바로 스토리지
관련 어려움들을 차례로 나열해보면 비용, 관리시간, 성능보장, DR등이 우선순위로 모든기업들이 비슷한 고민을 안고 있음
#33 특히나 모든 사업기반들이 IT통합되면서 계산성능과 맞물려 응답시간에 대한요구 뿐만 아니라 용량에 대한 요구도 다양해지고 있으며
특히 데이터의 보호에 대한 것들까지 가세되면서 워크로드타입으로만 데이터를 분류하는 것은 이미 전시대적이라고 할수 있다.
예를들어 과거에는 DB는 빠른 스토리지에, 개발은 저가스토리지에, 가상화는 일반스토리지에 하는것이 어쩔수 없는 선택이지만
이제는 DB중에서도 더 빨라야하거나 개발중에서도 한시적으로 더 빠른 성능을 요구할수 도 있는 것이다.
특히 Business Intelligent 입장에서보면 많은양의 데이터를 포함하면서도 분석시에는 빠른 응답을 해낼수 있어야하기 때문에
과거와 같은 정적인 기술적 워크로드 타입으로만 분류하여 사용하는것은
비효율적이며, 빠른 비즈니스 변화요구에 충분히 대응하지 못할 뿐아니라
결국 비경제적 투자를 하게된다.
즉이제는 즉재적소에 성능, 용량을 보자할 수 있는 스토리지 전략이 필요하다.
#34 먼저 넥스젠은 그 누구보다 빠르다. 그이유는 다음장에
둘째 아무리 빠른 아우토반이 마련되어 있더라도 한꺼번에 몰리는 상황이면 응급차가 이동할수 없다.
미션크리티컬한 서비스는 성능과 안정성이 보장되어야한다.
셋째 높게 날면 세밀히 볼수 없고 낮게 날면 멀리 볼수 없다.
다시 말해 분류를 세밀히 하지않으면 관리는 쉬우나 각 업무의 특성에 최적화된 성능이나 민첩성을 제공하기 어렵다. 관리에드는 시간도 마찬가지다
마지막으로 어느조직이나 한두개의 특별히 빠른 성능을 요구하는 서비스가 있을수 있는데. 단지 이를 위해서 전체를 AF로 바꾸는것 또한 낭비다.
Add PCI scale
Show HDD and SSD attach
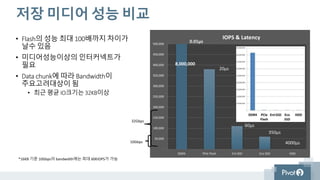
#35 큰범주로 메모리까지를 저장장치로 보았을때 (인메모리 DB가 쓰이는 이유) 최근 쓰이고 있는 DDR4 메모리는 8백만 IOPS에 달한다.
거기에 비해 일반 기업형 SSD는 십만 정도로 80배의 성능차이가 있다.
그리고 넥스젠이 사용하는 PCI플래쉬는 현재까지 나와있는 가장 빠른 낸드플래쉬로 38만IOPS이상의 성능을 나타낸다.
PC용 SSD대비 6배, 기업형 SSD에 대비해서도 3배이상 빠르다.
#37 NexGen data reduction technologies deliver performance, endurance and capacity benefits for our All-fash arrays.
#38 We believe that QoS will be a requirement for the next generation of all-flash arrays. NexGen’s dynamic QoS simplifies performance management and delivers more consistent application performance. Rather than make admins manually input performance targets, we’ve done the work, by creating five simple to assign policies. for them unlike other QoS offerings that force end users to react to a noisy neighbor and manually input minimums, maximums, and burst settings for every single volume in the system.
NexGen’s Dynamic Storage QoS has three distinct attributes. The first is that it allows customers to apply performance targets to Volumes and VMs. This manages min and max performance levels in terms of IOPS, TP and Latency.
Predefined policies control everything, including how data is prioritized, including intelligent BW throttling and queuing to ensure service levels are met.
Finally, since we’re a multi-tier architecture, real-time data placement is paramount. This is where features like prioritized active cache ensures that flash is prioritized for more critical workloads.
Emphasize dynamic QoS simplifies performance management and delivers more consistent application performance, unlike other QoS offerings that force end users to react to a noisy neighbor and manually input minimums, maximums, and burst settings for every single volume in the system.
Often times customers don’t realize how much performance to provision, NexGen’s patented QoS uses massive amounts of performance data collected from production environments to pre-define 5 simple policies that automate performance management. This is especially important for customers considering using Vmware vSphere 6 with virtual volumes (VVOLs). VVOLs can increase the number of objects in a data storage system by 30 times, there is no way users can scale by manually inputing minimums and maximums on every single VVOL.
PRIORITIES
Another shortcoming of other QoS engines is the ability to over-provision system performance. Just like thin provisioning in the capacity world, the ability to over provision is key to maximum utilization of resources. QoS engines with manual minimum, maximum, and burst settings leave users stranded when it comes to over provisioning as without a way to prioritize between the various performance targets during the times where the system is encountering contention (due to over provisioining), the system can’t make the right trade-offs and ensure mission critical apps get consistent performance.
PLACEMENT
There is a proliferation of new types of non-volatile media including several different types of flash. The only way to ensure customers achieve the most affordable all flash system while avoiding latency spikes and contention is to use multiple tiers of flash managed by a QoS engine. NexGen designed it’s architected all management capabilities around the concept of QoS in anticipation of using the best of all worlds from multiple media types and types yet to be discovered.
VVOL INTEGRATION
Our policies are integrated with Vmware’s Storage Based Policy engine (SPBM), that radically simplifies VM-level performance management. Changing performance is as simple as changing a selection on the drop down menu item – end users notice the change in seconds.
#40 Policy based QoS allows any one managing storage to easily assign priorities to a vm or volume. There are 5 preconfigured QoS policies.
You’re looking at the QoS policy for the NexGen n-1500 all flash array.
One of the our two existing hybrid policies is shown below so you can see the difference between QoS for multi-tier w/ HDD vs. multi-tier all-flash.
Keep in mind that each set of polices were designed. To align w/ the amount of flash in the system.
#42 Why does QoS matter in practice? Because customer data is not homogeneious.
They have different performance requirements and SLAs.
Take for example VDI. ….
#43 For SQL customers, this allows customers to attain the granular performance mgmt. that exists with stand-alone instances.
Policies can be assigned to VMFS, and now with VVLos support, wach instance gets granular performance management.
Our policies are integrated with Vmware’s Storage Based Policy engine (SPBM), that radically simplifies VM-level performance management. Changing performance is as simple as changing a selection on the drop down menu item – end users notice the change in seconds.
























![[오픈소스컨설팅]Virtualization kvm-rhev](https://cdn.slidesharecdn.com/ss_thumbnails/virtualization-kvm-rhev-140407012113-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[IBM 서버] POWER9](https://cdn.slidesharecdn.com/ss_thumbnails/11-181108055028-thumbnail.jpg?width=640&height=640&fit=bounds)
![2.[d2 오픈세미나]네이버클라우드 시스템 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/2-140905001236-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IBM 서버] 가장 강력한 보안을 자랑하는 서버시스템 Linuxone 을 소개합니다.](https://cdn.slidesharecdn.com/ss_thumbnails/1-181108050502-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenStack Days Korea 2016] Track2 - How to speed up OpenStack network with P...](https://cdn.slidesharecdn.com/ss_thumbnails/22kulcloud-160226172151-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenStack Days Korea 2016] Track3 - 방송제작용 UHD 스트로지 구성 및 테스트](https://cdn.slidesharecdn.com/ss_thumbnails/35kbs-160226173801-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IBM 김상훈] AI 최적화 플랫폼 IBM AC922 소개와 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/1-181029060038-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅] About Storage Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/dist-140126195610-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







![3.[d2 오픈세미나]분산시스템 개발 및 교훈 n base arc](https://cdn.slidesharecdn.com/ss_thumbnails/3-140905000012-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[142]편광을 활용한6 dof 전현기](https://cdn.slidesharecdn.com/ss_thumbnails/1426dof-161023161025-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2B5]nBase-ARC Redis Cluster](https://cdn.slidesharecdn.com/ss_thumbnails/2b5nbase-arcrediscluster-140930003743-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[IBM Technical NewsLetter - 통합 6호]](https://cdn.slidesharecdn.com/ss_thumbnails/tssnewsletter2018april-180423052520-thumbnail.jpg?width=640&height=640&fit=bounds)


