02
인공지능이나 빅데이터 서비스를준비하고자 하는 기업이나 스타트업은 데이터, 기술 및 서버
인프라 등의 부족이라는 벽에 부딪쳐 쉽게 관련 분야에 뛰어들지 못하고 있습니다. 기업들의 이런
문제를 조금이라도 해결해주기 위하여 지난 2014년 과학기술정보통신부(구 미래창조과학부)는
정보통신연구기반구축사업의 일환으로 빅데이터 활용이 필요한 기업의 연구개발 지원을 위해
세종대학교 인공지능-빅데이터연구센터를 출범시켰습니다. 이는 해당 분야의 인력 양성이 되지
않았고, 관련 기술이 매우 빠르게 발전하고 있어, 학교에서 배출되는 인력이 모든 기업에 충분히
공급될 때까지는 향후 많은 시간이 소요될 것으로 예상되기 때문입니다. 이에 따라 우선 학계의
연구 역량을 기업에 직접 공급하여 인프라로 활용할 수 있도록 한 것이고, 4년 정도 운영한 결과
많은 기업들로부터 매우 시의적절한 것으로 호평을 받고 있습니다.
넘쳐나는 데이터 속에서 ‘쓸만한 정보’를 찾아내는 일은 결코 쉽지 않습니다. 데이터의 수집, 저장,
가공과 분석을 거쳐 기업 활동에 필요한 맞춤형 정보를 얻기까지는 전문적인 기술과 시간, 그리고
비용이 필요하기 때문입니다. 우리 센터는 이러한 현실적 문제를 갖고 있는 국내 중소기업과
스타트업에 맞춤형 ‘부설 인공지능-빅데이터 연구소’가 되어드리고 있습니다. 50여 명의 전문 인력은
기업이 구현하고자 하는 시스템 개발을 위해 지속적으로 노력하고 있습니다. 뿐만 아니라 인공
지능-빅데이터 기술 개발을 위한 ‘기업 부설 데이터센터’ 역할도 하고 있습니다. 그 외에 많은 기관과
MOU를 통한 협력체계 구축으로 관련 기업에의 간접적인 지원도 해드리고 있습니다.
본 사례집은 이러한 센터의 기업지원 활동을 통해 인공지능-빅데이터 관련 분야에서 비교적
성공한 비즈니스를 창출하고 있는 기업들의 사례를 담았습니다. 이로써 새로운 디지털 환경의
중심으로 자리 잡은 인공지능-빅데이터의 활용이 기업 비즈니스 환경에 어떻게 적용되는지에
대해 확인하고 향후 도약을 꿈꾸는 중소기업들이 이 분야의 비즈니스 판로를 개척하는 희망의
길잡이가 될 수 있을 것이라 생각합니다. 여기 있는 사례들이 향후 많은 기업들의 인공지능과
빅데이터의 기술 개발에 도움이 되기를 바랍니다.
인공지능-빅데이터연구센터 소개
ABRC-3.indd 2 2017-11-02 오전 1:31:08
3.
03
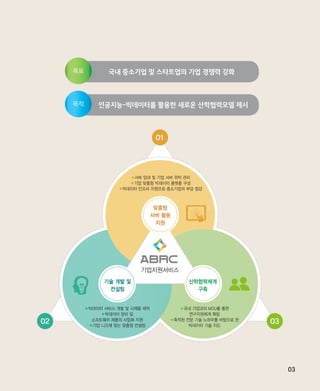
국내 중소기업 및스타트업의 기업 경쟁력 강화
인공지능-빅데이터를 활용한 새로운 산학협력모델 제시
●서버 임대 및 기업 서버 위탁 관리
●기업 맞춤형 빅데이터 플랫폼 구성
●빅데이터 인프라 지원으로 중소기업의 부담 절감
●빅데이터 서비스 개발 및 시제품 제작
●빅데이터 장비 및
소프트웨어 제품의 사업화 지원
●기업 니즈에 맞는 맞춤형 컨설팅
●국내 기업과의 MOU를 통한
연구지원체계 확립
●축적된 전문 기술 노하우를 바탕으로 한
빅데이터 기술 지도
맞춤형
서버 활용
지원
기술 개발 및
컨설팅
산학협력체계
구축
기업지원서비스
01
02 03
목표
목적
ABRC-3.indd 3 2017-11-02 오전 1:31:08
4.
04
장비지원 주요사례 공동기술개발주요사례
01 굿모닝아이텍(주) 06
클라우데라 솔루션 고도화 및 테스트
02 (주)에스씨플랫폼 07
기업 간 거래 데이터 분석 및 가치사슬 규명 엔진 개발
03 (주)비즈머스 08
wiseCloud 솔루션 테스트 및 고도화
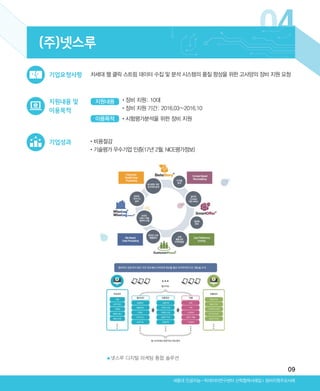
04 (주)넷스루 09
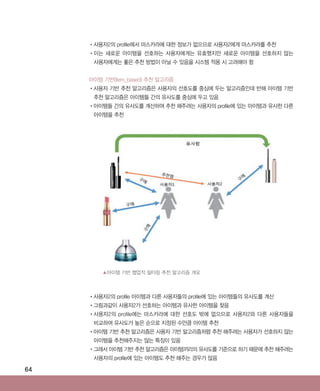
웹 클릭스트림 데이터 분석
05 (주)시엠아이코리아 10
빅데이터 분석
06 (주)알티베이스 11
기가코리아 과제 시스템 통합
01 (주)아우라 14
신체 성장 데이터 분석 시스템 및 예측 알고리즘 개발
02 (주)알티베이스 20
분산 환경 인메모리 기술 기반의 복합형
스트림 빅데이터 처리 기술개발
03 (주)홈스토리생활 27
사용자 로그 데이터 처리 및 분석 기술 및 ‘대리주부’앱의
인력 자동 매칭 추천 시스템 시제품 개발
04 (주)레드테이블 31
빅데이터를 이용한 비영어권 외래 관광객 대상 스마트관광
마케팅플랫폼 개발
05 (주)위세아이텍 40
머신러닝과 인공지능을 활용한 사고 다발생 이상 패턴 분류,
탐지 및 요양급여 부당청구 탐지 시스템 개발
06 플러스메이(주) 48
화장품 리뷰 시각화 분석 시스템 개발
07 (주)플렉싱크 54
관광 블로그 및 리뷰에 대한 감성분석 및 시각화 플랫폼 개발
08 (주)스타일켓 62
Libre 서비스의 사용자 맞춤형 추천 시스템 개발
09 (주) 애드잇 68
유휴공석과 손님을 이어주는 사용자 위치기반
O2O 서비스 다모 개발
10 (주) 열두시 74
통합 O2O 커머스 사용자 행동 로그 분석 기술 개발
ABRC-3.indd 4 2017-11-02 오전 1:31:09
5.
05
장 비 지원
주 요 사 례
PART1
세 종 대 인 공 지 능
빅 데 이 터 연 구 센 터
산 학 협 력 사 례 집
ABRC-3.indd 5 2017-11-02 오전 1:31:10
6.
06
▲클라우데라
•비용절감 및 매출증대 효과
•2016년도 일자리창출 유공 정부포상 고용노동부 장관표창 수상(16년 10월, 고용노동부 주관)
•2016 글로벌 상용 소프트웨어 명품대전 미래창조과학부장관상 수상(16년 5월, 공공부문발주자
협의회, 정부정보화협의회, 문화정보화협의회 주최, 한국상용SW협회, 한국PMO협회 주관)
지원내용 및
이용목적
빅데이터 플랫폼 소프트웨어 “클라우데라”와 실시간 데이터 분석용 데이터베이스
“파스트림”의 판매 촉진을 위한 성능 평가 및 고도화작업 진행을 위한 장비 지원 요청
기업요청사항
기업성과
지원내용
이용목적 •시험평가분석을 위한 장비 지원
•장비 지원: 15대
•장비 지원 기간: 2015.01∼현재
01 굿모닝아이텍(주)
▲파스트림 성능 비교
장비지원주요사례
ABRC-3.indd 6 2017-11-02 오전 1:31:10
7.
07
Ⅰ장비지원주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
▲위험전이 분석
•비용절감
•품목정보 기반의 가치사슬 분석을 통한 시장분석 솔루션의 2017년 상반기 시범 서비스 후
2017년 하반기 정식 서비스 제공
•매출추이 분석: 자사의 매출추이를 자사의 업종 전체 매출 추이와 실시간 비교 분석할 수 있도록
분석 서비스 제공
•업종 현황 분석: 자사 고객들의 업종 분포 및 해당 업종의 매출 추이를 실시간 분석함으로써
자사의 매출 전망을 분석할 수 있도록 분석 서비스 제공
•위험 전이 분석: 자사의 2차 고객에 대한 위험을 분석하여 해당 위험이 1차 고객을 거쳐 자사에
전이될 현황을 시각화 서비스로 제공
▲매출 추이 분석 ▲업종 현황 분석
지원내용 및
이용목적
기업거래데이터 기반 가치사슬 규명엔진 개발을 위한 전자세금계산서 데이터 실시간 수집 및 분석,
서비스 개발, 시범 서비스 제공을 위한 장비 지원 요청
기업요청사항
기업성과
지원내용
이용목적 •시험평가분석지원, 기술지도, 서비스 개발을 위한 장비 지원
•장비 지원: 16대
•장비 지원 기간: 2016.01∼현재
02(주)에스씨플랫폼
ABRC-3.indd 7 2017-11-02 오전 1:31:10
8.
08
03
•비용절감
•wiseCloud 솔루션 테스트:Private Cloud, Public Cloud, Hybrid Cloud 환경 구성, 관리, 사용을
통합 지원하는 오픈소스 기반 멀티 Cloud 관리 플랫폼
•고도 집약형 클라우드 장비 펜타아크(pentaARK) 개발 및 사업화: 서버, 스토리지 등 HW장비와
Hypervisor, wiseCLOUD를 통합한 Hyper convergence infrastructure
지원내용 및
이용목적
빅데이터 교육용 클라우드 플랫폼(EaaS, Education as a Service) 개발 관련 기술지원 및
wiseCloud 솔루션 테스트, 시스템 고도화, pentaARK 개발을 위한 장비 지원 요청
기업요청사항
기업성과
지원내용
이용목적 •시험평가분석지원, 시제품제작지원, 기술 지도를 위한 장비 지원
•장비 지원: 4대
•장비 지원 기간: 2017.01∼현재
(주)비즈머스
▲wiseCloud ▲pentaARK
ABRC-3.indd 8 2017-11-02 오전 1:31:10
9.
09
04
Ⅰ장비지원주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
•비용절감
•기술평가우수기업 인증(17년 2월, NICE평가정보)
지원내용 및
이용목적
차세대 웹 클릭 스트림 데이터 수집 및 분석 시스템의 품질 향상을 위한 고사양의 장비 지원 요청기업요청사항
기업성과
지원내용
이용목적 •시험평가분석을 위한 장비 지원
•장비 지원: 10대
•장비 지원 기간: 2016.03∼2016.10
▲넷스루 디지털 마케팅 통합 솔루션
(주)넷스루
ABRC-3.indd 9 2017-11-02 오전 1:31:10
10.
10
05
•비용절감
•오픈 소프트웨어 스파크와하둡을 기반으로 한 빅데이터 플랫폼 CMIS 솔루션 개발
기업성과
(주)시엠아이코리아
▲데이터인폼
지원내용 및
이용목적
빅데이터 분석 활용 서비스 개발 및 테스트를 위한 장비 지원 요청기업요청사항
지원내용
이용목적 •시험평가분석지원을 위한 장비 지원
•장비 지원: 10대
•장비 지원 기간: 2015.11∼2017.01
ABRC-3.indd 10 2017-11-02 오전 1:31:11
11.
11
06
Ⅰ장비지원주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
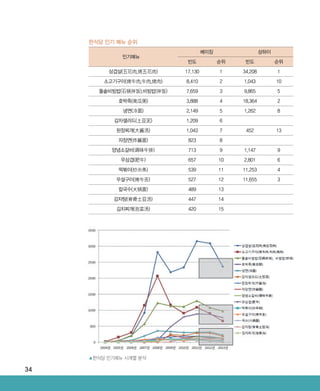
인공지능-빅데이터연구센터의장비를 활용하여 (주)알티베이스 컨소시움에서 개발한 복합형 스트림
데이터 실시간 분석 프레임워크의 테스트 성능을 향상시켰으며, 해당 기술은 여러 산업 전반에서
적용이 가능하도록 활용성을 높임
기업 장비지원 이용 목적
㈜알티베이스 서버 3대 •분산 인메모리기반 실시간 복합형 고속 스트림 처리
엔진전자부품연구원 서버 2대
와이즈넛 서버 1대 •복합형 스트림 데이터 수집
세종대학교 서버 1대
•GPU, In-memory 기반 스트림 데이터 시각화 가속
기술
•복합형 스트림 데이터를 분석하기 위한 시각적 분석
시스템(서비스)
모비젠, 위즈온텍 서버 1대 •서버 모니터링
성능평가 항목 정량적 성능 목표 성능평가 방법
서버당 스트림 데이터 처리 속도 Storm 성능 대비 100%
공인기관
시험성적서
GPU 분산처리 코어 활용 개수 3000코어 이상
분산환경 인메모리 지원 개수 2노드
기업성과
(주)알티베이스
▲테스트베드에서 구성된 복합형 고속 스트림 빅데이터 처리 플랫폼
지원내용 및
이용목적
빅데이터 서버를 이용하여 분산 환경 인메모리·GPU 기반 스트림 빅데이터 처리·분석 프레임
워크의 성능 평가를 위한 테스트 베드를 구성하기위한 장비 지원 요청
기업요청사항
ABRC-3.indd 11 2017-11-02 오전 1:31:11
12.
12
장비지원업체 리스트
업체명지원내용
1 CMIKorea 빅데이터 분석
2 CSAKorea 앱 수집 데이터 분석 및 시스템 고도화
3 가온미디어 웹 서비스 시험 및 검증
4 굿모닝아이텍 클라우데라 솔루션 고도화 및 테스트
5 넥스모션 IoT 플랫폼 빅데이터 플랫폼
6 넷스루 웹 클릭스트림 데이터 분석
7 디에스앤지시스템 서버 성능 테스트
8 레드테이블 레스토랑 리뷰 데이터 수집 및 분석 / 레스트랑 리뷰 데이터 분석 플랫폼 구축
9 리비젼컨설팅 자동차 수요 예측을 위한 수집 및 분석
10 모비젠 기가코리아 과제 시스템 통합
11 한국전자세제협회 기업 간 거래 데이터 수집 및 분석
12 비즈머스 wiseCloud 솔루션 테스트 및 고도화
13 비즈플러그 IoT 플랫폼 빅데이터 플랫폼
14 아몬드소프트 스마트 미러를 활용한 사용자 경험 플랫폼 구축
15 아임클라우드 IoT 플랫폼 빅데이터 플랫폼
16 알티베이스 기가코리아 과제 시스템 통합
17 애드잇 빅데이터 수집 및 활용 응용 프로그램 개발
18 에두수르 개발 중인 포털사이트 테스트 / 교육 SNS 데이터 수집 및 분석
19 에스씨플랫폼 기업 간 거래 데이터 분석 및 가치사슬 규명 엔진 개발
20 오뉴이노베이션 서버 성능 테스트
21 와이즈넛 기가코리아 과제 시스템 통합
22 이담에스티 서버 성능 테스트
23 이팝콘 자주와 앱 수집 데이터 분석 및 시스템 고도화
24 인텍앤컴퍼니 서버 성능 테스트
25 전자부품연구원 기가코리아 과제 시스템 통합
26 차후 기가코리아 과제 시스템 통합 / 사물인터넷 융합 모바일 서비스 개발
27 포에니코리아 딥 러닝 연구
28 플래누리 IoT 플랫폼 빅데이터 플랫폼
29 한다시스템 웹 개발 솔루션 테스트
30 이트론 서버 성능 테스트
31 두물머리 온라인 투자자문 서비스 불리오 테스트
32 아이오에이솔루션 테스트 자동화 서비스 개발
33 픽셀플레넷 방송 영상 데이터 수집 및 분석
ABRC-3.indd 12 2017-11-02 오전 1:31:11
13.
공동기술개발
주 요 사례
PART2
세 종 대 인 공 지 능
빅 데 이 터 연 구 센 터
산 학 협 력 사 례 집
ABRC-3.indd 13 2017-11-02 오전 1:31:12
14.
14
01 (주)아우라
공동기술개발 주요사례
기업의
사업추진
배경
•성장예측의 필요성: 성장기 자녀의 신체 성장 예측은 학생들과 부모들이 많이 관심을 갖는 분야로
이는 성장 관련 시장 규모의 증가로 이어짐
•성장 관련 시장 규모: 대한민국의 키 성장 시장은 2014년 기준 약 7600억 원 규모로 세부적으로
구분하면 한의원 3600억, 성장 클리닉 센터 1600억, 키 성장 기능식품 1500억, 호르몬 시장
900억 규모로 추산 (2015년 헤럴드 경제)
•과다한 검진 비용: 현재 성장 예측 방법은 클리닉 센터에서 손, 무릎 관절에 방사선을 이용한
진료 방법으로 최초 검진시 20~50만원의 비용이 소모됨
•비용으로 인한 정보 격차: 성장 관리를 위해 주기적으로 클리닉을 방문해야 하는 만큼 많은
비용이 발생하며 이는 소득 수준에 따른 정보 격차로 이어짐
•(주)아우라에서는 광명시 청소년을 대상으로 ‘스마트건강지킴이’라는 신체 성장 관리 서비스를
제공하고 있음
•스마트건강지킴이는 인바디 측정 기구를 이용하여 학생의 신체 정보를 수집한 다음, 학생의 성장
분포 현황을 모니터링 할 수 있음
•(주)아우라에서는 사업 확장을 위해 (1)개인 맞춤형 신체 성장 예측과, (2)학생들의 신체 성장
데이터를 심층적으로 분석할 수 있는 시각적 분석 시스템을 원함
•신체 성장 데이터는 아래와 같은 이유로 기존 예측 방법을 적용하는데 어려움
신체 성장 데이터 분석 시스템 및 예측 알고리즘 개발주제
지원배경
기존 서비스 개발 진행 내용
기존 기술의 한계점
데이터 특징 설명 영향
시계열 다변량 데이터 22개의 신체 구성요소로 구성
연산 시간 증가
(Curse of dimensionality)
불규칙적인 측정 기간 1년에 2~17번 측정(평균 6번) 낮은 예측 정확도
불규칙적인 측정 횟수 1~4년간 측정(평균 2년) 낮은 예측 정확도
불확실한 트렌드
전체 성장주기를 알 수 있는
데이터 없음
기존 예측 분석 접근 방법을
적용할 수 없음
청소년 신체 성장 데이터 특징
ABRC-3.indd 14 2017-11-02 오전 1:31:12
15.
15
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
기존 예측 기술에 따른 문제점
•2016.08 ~ 현재: 기술컨설팅 진행, 시제품 제작 지원
•2017.04.~2017.09: 성장 예측 알고리즘 개발에 관한 용역 과제 체결
센터의
지원 내용
•개인 맞춤형 신체 성장 예측 알고리즘 개발
•신체 성장 시각적 분석 시스템
•기존 예측 기술은 Top-down 방식으로, 데이터에서 추세 및 특징을 식별하여 여러 그룹으로
분류함, 새로운 데이터가 들어오면 유사한 그룹으로 분류한 뒤 그룹의 경향을 예측 결과로 도출함
•청소년 신체성장 예측에 위 방법을 적용하는데 다음과 같은 문제점이 있음
기업의 요청 사항
지원 기간
예측 기술 문제점
회귀분석
(선형 회귀, 로그 회귀)
•낮은 정확도
•개인별 성장패턴에 따른 예측 불가능
기계학습
(Decision tree, Neural network)
•Overfit 발생 가능
•분류모델 구현 불가능
▲최종 개발 목표도
•신체 성장 데이터는 7세~18세 사이의 21,445명의 학생을 대상으로 측정한 22개의 신체 요소와
학생 정보로 구성되어 있으며 자세한 내용은 아래 표와 같음
활용 데이터 종류
ABRC-3.indd 15 2017-11-02 오전 1:31:12
16.
16
연평균 키 성장량분포
•여학생은 1~5학년에 집중적인 성장 관리가 필요하며 이 시기를 놓치면 성장 정체기에 접어들
가능성이 매우 큼
•여학생의 약 70%는 6학년 이후 성장 정체기에 들어가며, 7학년 이후 전체의 90%로 확대되며,
전년도 대비 2cm 이하의 키 성장량을 보임
- 연평균 키 성장량이 4cm 이상인 그룹의 비율은 5학년 69.2%에서 6학년 31.8%로 37.4% 감소
- 여학생은 남학생보다 3년 빨리 성장 정체기에 접어듦
•남학생은 3~8학년에 집중적인 성장 관리가 필요하며 이 시기를 놓치면 성장 정체기에 접어들
가능성이 매우 큼
•남학생의 약 60%는 8학년 이후 성장 정체기에 들어가며, 9학년에는 86%로 확대됨
연평균 키 변화율(성장률)과 다른 지표 변화율과의 관계분석
•키 성장률과 비만과 관련된 지수(BMI, Body fat mass, Waist hip size)는 선형성을 찾기 어려움
•다음과 같은 지표는 3가지 패턴(증가, 유지, 감소)이 뚜렷하게 나타나지만, 각 패턴별로 특별한
특징은 발견되지 않음
분석 내용 (청소년 신체 성장 데이터를 분석한 내용 중 일부만 기술함)
신체 성장 데이터
Parameter
학생 정보 ID Gender Age Date
신체 구성
요소
키 BMI BMR 몸무게 골격근량
체지방량 체수분량 근육량 체지방량 단백질
미네랄 무기질 체지방률 복부지방률 목 둘레
가슴 둘레 복부 둘레 오른팔 둘레 왼팔 둘레 엉덩이 둘레
오른 허벅지 둘레 왼쪽 허벅지 둘레
▲성별, 학년 구분별 연평균 키 성장량 분포
ABRC-3.indd 16 2017-11-02 오전 1:31:12
17.
17
▲키 성장률과 BMI변화율과의 관계
▲성장 예측 알고리즘 모델
▲키 성장률과 Mineral mass 변화율과의 관계
▲키 성장률과 Percent body fat 변화율과의 관계
▲키 성장률과 Protein mass 변화율과의 관계
- Mineral mass
- Protein mass
- Skeletal muscle mass
•나머지 지표들은 양의 선형성이 뚜렷하게 나타남
개인 맞춤형 성장 예측 알고리즘은 2가지 모델을 이용함
•Bayesian inference model: 추론하고자 하는 대상의 사전확률P(A)과 likeihood P(B|A)를 이용
하여, 대상의 사후 확률P(A|B)을 추론하는 방법
•Distribution based model: 시간이 변하더라도 학생의 키(height) 분포는 유사하다는 가정 하에
Euclidean distance를 이용한 예측 방법
분석 기법
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 17 2017-11-02 오전 1:31:12
18.
18
센터의
지원 성과 개인맞춤형 신체 성장 예측 알고리즘 개발
•알고리즘은 시간 흐름에 따른 성장 가능한 키의 범위가 도출됨
•예측 결과의 불확실성을 최소화하기 위해 시간적 불확실성 요소를 계산함
신체성장 시각적 분석 시스템
•신체성장 시각적 분석 시스템 프로토타입은 아래 그림과 같음
•웹 기반 시스템으로 구현하였으며, 다음과 같은 내용을 분석 할 수 있음: 성장 추세 분석, 성장
예측, 성장 패턴 비교, 성장 분포 비교
지원 결과
▲신체 성장 예측 알고리즘 결과
▲신체성장 시각적 분석 시스템 프로토타입
ABRC-3.indd 18 2017-11-02 오전 1:31:12
19.
19
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
•(주)아우라의 스마트건강지킴이 솔루션은 현재 광명시 초·중·고교에서 서비스하고 있으며
학부모와 공공기관의 호평을 받고 있음
•성장 예측 관리 플랫폼으로 확대하여 2018년 전국 초·중·고교로 확대할 예정
기대효과 및 향후 발전방안
ABRC-3.indd 19 2017-11-02 오전 1:31:12
20.
20
02 (주)알티베이스
기업의
사업추진
배경
•정보의 홍수속에서 가치 있는 데이터를 찾기가 어려워지고 있으며 다양한 산업 분야에 걸친 방대한
양의 ‘연속성’을 같는 데이터 폭증은 실시간 스트림 데이터 분석에 대한 수요를 증대시키고 있음
•다양한 데이터 소스에서 이벤트 형태의 고속으로 발생하는 빅데이터를 실시간으로 관리하고 분석
하고자 하는 요구의 증가량에 비해 관련 국내 기술 수준이 낮은 상황
•이에 지속적으로 증가하는 데이터의 다양성, 규모, 속도를 지원하기 위한 실시간 복합형 고속
스트림 빅데이터 관리 및 분석 기술이 필요함
•국내 기술은 정형 스트림 처리 중심의 기술개발이 이루어지고 있으며 관련 기술 수준이 낮고,
반정형·비정형을 포함한 고속 스트림 빅데이터 분석 기술 수준도 낮음
•세종대학교는 인메모리 데이터베이스 기업 (주)알티베이스와 (주)와이즈넛, 전자부품연구원, 모비젠,
위즈온텍, (주)차후와 함께 자사의 보유 기술을 활용하여 복합형 고속 스트림 빅데이터 솔루션
요건을 충족하는 기술을 개발함
•(주)알티베이스는 2014년 정형 빅데이터 분석 플랫폼 및 디스크 기반 In-Memory cluster 인프라
핵심 기술을 개발했으며
•스트림 데이터 처리 플랫폼의 경우 2009년에 기반 기술
•2009년 스트림 데이터 처리 플랫폼을 개발했으며 경찰청 수배차량 검색 시스템 및 차적 조회
자동화 시스템을 서비스함
•(주)알티베이스는 스트림 데이터 처리 뿐 만 아니라 데이터 분석을 통한 정보 생산까지 이어지는
종합적인 스트림 데이터 처리·분석솔루션을 개발하고자 세종대학교와 다른 기관과 컨소시엄을
구성함
•초대용량이면서 특정 이벤트에서만 의미를 가지는 스트림 데이터 처리를 기존과 같이 DBMS에
데이터를 저장 후 판단하는 경우 현격한 성능 저하 및 관리 비효율의 문제가 야기됨
스트림 데이터 고속 시각화 및 시각화 기반 분석 기술
•Stand-alone 및 Server GPU를 활용한 시각화 가속 기술
•비정형(음향, 영상) 스트림 데이터 분석 기술 개발 및 시각적 분석 시스템에 적용
분산 환경 인메모리 기술 기반의 복합형 스트림 빅데이터 처리 기술개발주제
지원배경
기존 서비스 개발 진행 내용
기존 기술의 한계점
기업의 요청사항
ABRC-3.indd 20 2017-11-02 오전 1:31:12
21.
21
센터의
지원내용 •2015.07.01~ 현재:2015년에 컨소시엄을 구성하였으며 현재 복합형 스트림 빅데이터 처리기술
개발 과제 수행 중
•음향·영상·텍스트 등 모든 복합형 스트림 데이터
GPU를 활용한 시각화 가속 기술
•2노드 기반 시각화 서버 분산 처리 아키텍쳐 설계
•SLI를 활용한 Multi core GPU 분산 컴퓨팅 설계
•차트, 맵, CCTV, heatmap을 활용한 시각화 기법의 다양화
•Abnormality, entropy, SVM을 활용한 데이터 전처리 연산의 다양화
비정형(음향·영상) 스트림 데이터 분석 기술 개발
•영상: 스트림 데이터에서 도메인에 맞는 이상 정보를 확인하고 표현하는 기법을 적용했으며,
파이프 내 영상정보를 이용한 이물질, 균열 탐지기술로 확장함
•실시간 스트림 데이터 분석을 위한 분산 메모리 기반 아키텍처 설계
•지하 공간, 지진, 질병 분석을 위한 동적 스트림 데이터 시각적 분석 시스템 개발
지원기간
활용 데이터 종류
분석 내용
▲In-memory, GPU 기반 시각화 가속 기술 파이프라인
▲영상정보를 이용한 파이프라인 균열 탐지 기술 예
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 21 2017-11-02 오전 1:31:12
22.
22
•음향: 스트림 데이터에서적용 가능한 이상 탐지 모델을 구축했으며, 상수도의 음향센서 간의
변화를 통해 내부의 유수 여부를 감지할 수 있는 기술로 확장함
▲음향정보를 이용한 상수도 유수 탐지 기술 예
▲실시간 스트림 데이터 분석을 위한 분산 메모리 기반 아키텍처
실시간 스트림 데이터 분석을 위한 분산 메모리 기반 아키텍처 설계
•스트림 처리: 스트림 프로세서 또는 인메모리 서버에 저장된 스트림데이터는 사용자의 작업
요청에 의해 시각화 노드와 연결됨
•노드 분산: 제어노드에 의해 작업의 규모에 따라 MPI Controller를 통하여 각 시각화 노드에 작
업을 분할함
•CPU 분산: 시각화 노드에 분할되어 획득된 세부 작업은 Threading 및 분산 쿼리를 활용하여
CPU 병렬 처리 됨
•GPU 분산: 8개의 CPU로 분산된 단위작업은 Shader 및 CUDA Multi GPU computing을 통해
GPU 병렬처리 되어 단위 시간 내 작업 효율을 극대화함
ABRC-3.indd 22 2017-11-02 오전 1:31:12
23.
23
▲알려지지 않은 복합형스트림 데이터를 분석하기 위한 dynamic 시각적 분석 프레임워크
센터의
지원 성과 복합형 스트림 데이터를 분석하기 위한 dynamic 시각적 분석 프레임워크
•세종대학교는 dynamic 시각적 분석 프레임워크에 다음 3가지 시나리오를 적용함
- 싱크홀 탐지 및 피해현황 분석 (서울시 송파구의 상하수관 누수 탐지·분석)
- 지진 탐지 및 피해현황 분석 (경상북도 경주시 지진 탐지·피해현황 분석)
- 질병 탐지 및 확산 예측 분석 (독감 탐지 및 확산 경로 예측 분석)
지원 결과
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 23 2017-11-02 오전 1:31:12
24.
24
싱크홀 탐지 및피해 현황 분석 (서울시 송파구의 상하수관 누수 탐지·분석)
•상하수관 누수 가능성 탐지: 정형 데이터(센서), 비정형 데이터(트윗)
•상하수관 누수 확인: 정형 데이터(센서), 비정형 데이터(음향 센서, 영상 정보)
•상하수관 누수로 인한 피해 현황 파악: 비정형 데이터(트윗, 뉴스)
▲싱크홀 탐지 및 피해현황 분석 시스템
ABRC-3.indd 24 2017-11-02 오전 1:31:12
25.
25
질병 탐지 및확산 예측 분석 (독감 탐지 및 확산 경로 예측 분석)
•복합형 스트림 데이터와, static 데이터를 혼합하여 질병 위험도 분석 및 확산 예측 시각적 분석
프레임워크를 개발함
•질병 위험도 시각적 분석 시스템 (복합형 스트림 데이터 활용): 질병 유형에 따른 발병 현황 및
유행 정도를 지역 구분에 따라 종합적으로 분석 할 수 있음
•질병 확산 시각적 분석 시뮬레이션(인구·질병 DB 활용): 질병 특성에 따라 언제 어떠한 경로로
확산 할 수 있는지 시뮬레이션 할 수 있음
▲질병 탐지 및 확산 예측 분석 시스템
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 25 2017-11-02 오전 1:31:12
26.
26
지진 탐지 및피해현황 분석 (경상북도 경주시 지진 탐지·피해현황 분석)
•지진과 관련된 스트림 데이터를 활용한 시각적 분석 프레임워크를 개발함
•스트림 데이터는 텍스트(트윗, 뉴스), 센서 값(리히터 규모), 영상(CCTV)를 이용함
•2017년 1월 5일에 이슈화된 경주 지진 사례를 적용함
•시각적 분석 프레임워크를 통해 지진 발생 여부, 진앙지·지진 규모 파악, 각 도시별 지진파 도달
시기 파악, 각 도시별 피해 현황을 종합적으로 분석 할 수 있음
분산 환경 인 메모리 기반의 복합형 고속 스트림 빅데이터 처리 및 관리 기술과 실시간 시각화 분석
기술은 산업 전반에서 다양한 부가가치 창출 가능
•사물 인터넷 환경에서 발생한 다양한 비정형 및 반정형 데이터 분석
•공공서비스 분석을 위한 인프라로 활용 및 사고 감지, 재해 예방
•스마트 에너지, 지능형 교통 서비스, 사회 인프라 원격 관리 서비스 등 다양한 산업과의 융합을
통한 IoT 인프라로 활용
▲지진 탐지 및 피해현황 시각적 분석 시스템
기대효과 및 향후 발전방안
ABRC-3.indd 26 2017-11-02 오전 1:31:12
27.
27
▲(주)홈스토리생활 고객관리시스템 ▲전화상담리스트 관리 시스템
03
기업의
사업추진
배경
사용자 로그 데이터 처리 및 분석 기술 및 ‘대리주부’앱의 인력 자동 매칭 추천 시스템 시제품 개발주제
(주)홈스토리생활
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
(주)홈스토리생활은 가사, 산후서비스, 포장이사, 클리닝 등 가사 전반 서비스 제공업체로, 매니저
(가사도우미) 파견 서비스가 주력 사업
•2014년도 한해 30만 건의 거래(4시간 기준 120만 시간 서비스 진행)가 이루어졌고 이와 관련한
거래 정보 데이터를 축적하고 있음. 또한 매주 8천 가구를 방문하여 서비스 중
•그 외 총 15,000명의 등록 고객 정보, 약 3,000명의 매니저 인적 정보, 기본 인구통계학적 데이터,
2008년부터 고객 상담 내역을 저장하고 있음
매니저 배정 시스템 개발
•기존 고객관리시스템, 전화상담 리스트 관리시스템을 보유 하고 있지만, 고객의 서비스 요청에
대해 상담사의 수작업 형태의 정보 확인을 통한 업무 양식으로 인한 매니저 배정 업무 효율성 저하
•매니저들과의 개별 연락을 통해 일정 확인 후 배정을 진행함에 따라 신청 접수 후 매니저 최종
배정까지 최소 1일 이상의 시간이 소요됨
•고객 요구사항 반영을 위한 추가적인 데이터 축적 필요
- 고객의 단순 서비스 요청에 대하여 파견 가능한 매니저들에게 구두로 고객 요청 사항을 전달
함에 따라 업무의 비효율성, 서비스 신뢰도 저하 등의 문제 발생
기존 서비스 개발 진행 내용
추진의 문제 및 기업 요청사항
ABRC-3.indd 27 2017-11-02 오전 1:31:13
28.
28
•텍스트 기반으로 축적된상담 데이터 마이닝을 통한 매니저 관리 필요
- 유선상의 고객 요청 사항, 불만사항 등을 상담사가 텍스트로 작성하여 개별 관리하고 있으며,
서비스 품질 관리 개선에 데이터를 활용하지 못하고 있음
•모바일을 통한 온라인 서비스 확장으로 가사도우미의 오픈 마켓 공급 구조에 변화를 주고 있으며
다양한 고객 확보를 위한 방안 모색 중
•매니저 배정 필터링을 위한 데이터베이스 확장 필요
- 매니저 성향(꼼꼼함, 정리정돈, 반찬, 다림질, 평형대, 교체 및 클레임, 애완동물 가능여부,
원거리 가능 등)을 반영하여 매니저 배정 필요
- 추가로 서비스 가능 지역을 고려한 데이터베이스 확장
•매 중복 편성 최소화 및 클레임 발생 고객에 대한 매니저 재배치 가능성을 없애기 위한 방안 검토
▲향후 (주)홈스토리생활의 사업전략
센터의
지원내용 2015.03~2015.08
매니저 배정 시스템 프로토타입 V.0.1 개발
•고객의 서비스 요청 일자에 출장 가능한 매니저를 선정해 매니저 주소와 서비스 요청 주소지
간의 거리별 매니저 리스트를 작성하여 상담사가 확인할 수 있도록 한 서비스 시스템
자사의 가사도우미, 고객 정보, ‘대리주부’앱 로그 데이터
지원기간
개발 지원 내용
활용 데이터 종류
국내 최초 기업형 가사서비스 사업 시작
전국 망 운영 유일한 업체
오프라인 경쟁력 확보
6년간의 운영 노하우
Mobile (ON Line)
OFF LINE
(기존 ‘홈스토리’)
(신규 ‘대리주부’)
매니저 약 3000명
지사 및 직영 센터 40개, 이사청소 100개 지사
주요 타겟 40-50대
정형화, 프리미엄 서비스
‘직업소개업’ 기반
On Demand 위주(즉시성)
1:1 매칭 구조
기존 공급망+오픈마켓 공급구조
주요 타겟 30-40대
즉시성, 확장성 및 Casual서비스
‘직업정보 제공업’ 기반
ABRC-3.indd 28 2017-11-02 오전 1:31:13
29.
29
▲매니저 배정 시스템프로토타입 V.0.1
▲매니저 배정 시스템 프로토타입 V.0.2
매니저 배정 필터링을 위한 데이터베이스 설계를 바탕으로 매니저 배정 시스템 프로토타입 V.0.2
개발 및 소스 코드 제공
•고객의 특정 매니저에 대한 클레임 이력 관리 가능
•서비스 요청 고객에 대한 클레임 이력이 있는 매니저 배제
•매니저들의 평점 관리 가능
•서비스 완료 후 고객들의 서비스 품질에 대한 feedback 수치화
•평점에 따라 매니저 배정 우선순위 확인 가능
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 29 2017-11-02 오전 1:31:13
30.
30
센터의
지원 성과 •구인및 구직자 매칭 시스템에 기반한‘대리주부’앱을 출시하여 2015년 9월 한국투자파트너스와
네오플럭스로부터 35억 원의 공동투자 유치
•앱 어워드 코리아 2015 올해의 앱’생활서비스 분야 가사 생활서비스 부문 대상 수상(미래창조
과학부, 문화체육관광부, 정보통신산업진흥원, 한국콘텐츠진흥원 후원)
•센터와 협업하여 서비스 고도화 진행 중이며 마케팅 효율성 증대를 위해 로그 데이터 분석
시스템 개발 중
지원 결과
성과 홍보
사례
ABRC-3.indd 30 2017-11-02 오전 1:31:13
31.
31
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
04
기업의
사업추진
배경
빅데이터를 이용한 비영어권 외래 관광객 대상 스마트관광 마케팅플랫폼 개발주제
(주)레드테이블
외래 관광객의 스마트기기 활용 증가 추세에 적합한 모바일 앱 부족
•스마트관광이란 웹 또는 앱 형태의 다양한 정보가 관광객에게 모바일기기를 통해 제공되는 실시간
맞춤형 관광 서비스
•관광객을 위한 모바일 앱은 국내 관광객 위주의 서비스에 편중돼 있으며 지원언어도 주로 영어,
일본어에 그치고 있었으며 관광 정보 검색, 길 찾기, 상황인식 등이 전체 기능의 81.77%를 차지,
외래 관광객의 주 활동인 쇼핑, 음식, 미식탐방, 관광을 위한 서비스 내용은 부족한 상황
•이용매체 분석 결과 관광객들이 정보 탐색 시 가장 많이 이용하는 매체로 웹사이트(71.3%)의
비율이 가장 높았으며, 그 다음이 SNS(14.9%), 모바일앱(8.6%), 메신저(3.6%)순으로 한국 관광
정보탐색을 위한 모바일 앱 이용 여부는 국내 관광객(29.8%)보다 외래 관광객(40.8%)에서 더
높은 것으로 나타남
•스마트기기 보급 및 확산과 개별관광객 비중 증가에 따라 외래 관광객의 스마트기기 활용을 통한
정보습득 비중이 높아졌다고 할 수 있음(한국관광문화연구원, 외래 관광객 실태조사 결과보고서,
2012)
•외래 관광객이 모바일앱을 사용하는 이유로 휴대성(68.4%), 편리성(59.2%), 다양한 정보 획득
(46.7%), 정보공유의 용이성(11.2%), 가격 할인 등의 혜택(5.9%), 정보등록의 용이성(0.7%)
순으로 나타남
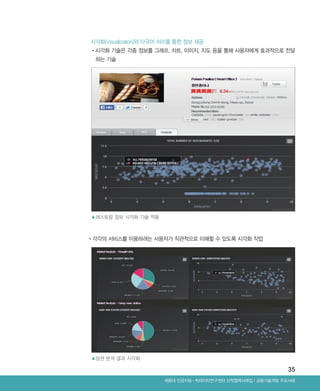
비영어권 외래 관광객의 스마트 관광을 위한 마케팅 플랫폼 필요
•관광 시 쇼핑, 외식에 대한 정보, 프로모션 앱에 대한 니즈가 커지고 있으며, 국내 관광객들은
교통, 즐길 거리, 숙박, 관광기념품, 음식, 쇼핑 순인데 반해 외래 관광객은 숙박, 음식, 교통, 즐길
거리, 쇼핑, 관광기념품 순으로 나타나 이에 적합한 맞춤형 서비스 개발 필요함
•관광문화가 발달한 프랑스의 경우 현지인의 의견을 수렴하는 모바일 앱인 ‘Accueil France’를
개발해 관광객과 현지인이 관광지의 음식점 및 숙박 시설을 이용하고 난 후의 평가와 후기를
작성하는 쌍방향 공유기능을 제공하고. 독일은 현지인 설문조사를 바탕으로 관광명소 100곳을
외래 관광객에게 소개하고 있음
•내국인과 비영어권 외래 관광객의 빅데이터를 수집 분석하여 원하는 레스토랑, 쇼핑, 관광에
대한 정보제공과 편리한 여행을 위한 할인, 쿠폰 등 부가 서비스도 제공하고자 함
지원배경_서비스 개발의 필요성
기업의 요청사항
ABRC-3.indd 31 2017-11-02 오전 1:31:13
32.
32
센터의
지원내용 2014.05~2015.08
지원기간
•비영어권 빅데이터마이닝: 국가별(중국, 일본, 동남아시아, 한국 등), 외식/호텔/관광 분야 컨텐츠
활용(중국 dianping.com, 일본 gnavi.co.jp, 동남아시아 openrice.com, 글로벌 tripadvisor.com 등)
•비영어권 빅데이터 분석: 고객 행동/감성 분석, 맞춤형 정보제공, 시각화, 다국어처리
- 국가별 맞춤형 정보제공 기술: 비영어권 빅데이터 수집, 데이터 정제
- 국가별 관광객 행태 분석 기술: 피플랭킹, 감성분석
•마케팅 플랫폼 구축: 외래 관광객을 타겟으로 하는 기업의 광고, 세일즈, 컨설팅 플랫폼
- 시각화와 다국어 처리를 통한 정보제공 기술 : 랭킹, 속성분석, Visualization
- 마케팅 프로모션 : 광고, 세일즈, 컨설팅, 웹 개발, 앱 개발
분석 내용 및 분석 기법
온라인 리뷰 데이터(텍스트 데이터)
활용 데이터 종류
센터의
지원 성과 텍스트 분석(Text Analyzer) : 감성 분석(Sentiment Analyzer)
•감성 분석이란 인터넷 사용자가 리뷰 사이트에 등록한 의견을 바탕으로 사용자의 텍스트로부터
사용자의 감정을 자동으로 분석하는 기술
•사용자 개인의 의견을 분석하는 오피니언 마이닝 연구는 주로 인터넷 블로그, 카페, 커뮤니티
등에 게재된 다른 사용자의 의견을 분석 대상으로 함
•본 기술에서는 지도 학습(supervised learning)을 통한 한국어 오피니언의 긍정 부정 여부를
분류하도록 하였으며 주요 기술은 문서의 가중치 산출과 기계학습 기법임
•주제 기반 문서 분류에서 TFIDF 가중치 산출 기법보다 높은 성과를 보이는 Information
Gain(IG), Mutual Information(MI), CHI 기법 등을 사용하여 오피니언 기반 긍정/부정 분류의
적합도와 성능을 향상
•긍정, 부정 문서 분류에는 오피니언의 통합적인 긍정, 부정 이 외에 오피니언 내의 특징별 점수를
산정하는 기술을 도입하여 오피니언 상에서 특징(상품에서는 기능) 단어가 어떤 것인지 알아냄
•분류의 정확성을 높이기 위한 또 다른 방법으로 감성 표현에 대한 패턴 매칭 방식에 대한 개발도
병행 했으며 ‘concordance’프로그램을 활용하여 분야별 코퍼스로부터 평가적 패턴을 발견하고
수집하여 데이터베이스에 저장한 뒤, 평판 문서로부터 동일한 패턴을 발견해내어 분류 정확성을
높임
지원 결과
ABRC-3.indd 32 2017-11-02 오전 1:31:13
33.
33
텍스트 분석(Text Analyzer):속성별 분석(Attribute Analyzer)
•온라인 리뷰는 리뷰어의 의견을 포함한 문장과 의견을 포함하지 않은 문장으로 나눌 수 있고 이
중 의견을 포함한 문장은 의견 대상과 의견 대상을 표현하는 서술어로 구성됨
•리뷰 분석을 위해서는 도메인에 따른 의견 대상의 속성이나 특징 분석이 필수적
•리뷰 속성에 대한 의견 또는 감정 분석을 위해서는 리뷰로부터 속성을 추출해야 함
•속성은 어휘 형태소의 품사 분류 중 명사로만 구성되어 있기 때문에 속성 추출은 리뷰 내의 명사
들과 속성 사전을 비교하여 일치하는 명사를 추출하는 방식으로 이루어짐. 따라서 속성 추출을
위해서는 먼저 속성 사전 구축이 선행되어야 함
•속성 사전을 통해 속성별로 감정 분석을 할 수 있어 보다 더 정교한 의견 마이닝이 가능하게 함
•레스토랑의 속성 어휘 사전 구축을 위해 먼저 래퍼 기반 래퍼 기반 웹 크롤러를 이용해 레스토랑
리뷰 문서를 각각 수집
•수집한 문서들을 대상으로 형태소 분석을 하는데 속성 어휘는 명사로만 이뤄지기 때문에 다른
성분은 제거하고 명사만 추출함
•일반 문서와 레스토랑 리뷰 분석 결과 중 상위 N개의 명사 빈도수를 비교하여 레스토랑 리뷰의
명사 Set에서 일반 문서의 명사 Set을 제외하여 레스토랑 속성 사전 후보 작성
•수작업으로 결과를 보정하고 레스토랑 속성 계층을 정의해 사전 작성 완료
▲레스토랑 속성 어휘 사전 구축을 위한 알고리즘
▲속성 사전구축 흐름도
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
Step1 래퍼 기반 웹 크롤러를 이용해 온라인 뉴스 문서와 특정 도메인 리뷰 문서 수집
Step2 형태소 분석
Step3 형태소 분석 결과 중 명사만 추출
Step4 추출된 명사의 빈도수 측정
Step5 일반 문서와 특정도메인 리뷰 분석 결과 중 상위 N개의 명사 빈도수 비교
Step6 특정 도메인 리뷰의 명사 Set에서 일반 문서의 명사 Set을 제외
Step7 수작업으로 도메인별 속성 계층 정의
ABRC-3.indd 33 2017-11-02 오전 1:31:13
35
▲레스토랑 정보 시각화기술 적용
▲상권 분석 결과 시각화
시각화(Visualization)와 다국어 처리를 통한 정보 제공
•시각화 기술은 각종 정보를 그래프, 차트, 이미지, 지도 등을 통해 사용자에게 효과적으로 전달
하는 기술
•각각의 서비스를 이용하려는 사용자가 직관적으로 이해할 수 있도록 시각화 작업
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 35 2017-11-02 오전 1:31:13
36.
36
▲업종 분석 시각화
▲감성분석시각화
•사용자가 보고자 하는 랭킹정보, 통계 정보, 레스토랑 관련 정보 등을 사용자 편의를 위해 파이
차트, 히스토그램, 음성합성 등이 포함된 멀티미디어 프리젠테이션 기법 등을 통한 디스플레이
•특정 레스토랑에 대한 만족도와 인기도 추이 그래프는 막대그래프와 꺾은선그래프를 결합한
그래프로 시간에 따라 해당 레스토랑의 평판과 인기도의 변화를 한 눈에 확인
•지역별 인기도와 메뉴별 인기도는 파이차트로 표현
•지역별 인기도를 통해 소비자의 관심 지역을 알 수 있고 간접적으로 좋은 상권을 유추할 수 있게 함
•메뉴별 인기도 그래프를 통해 특정 지역에서 가장 인기 있는 메뉴 또는 특정 매장에서 가장 인기
있는 메뉴 확인
•지역별, 메뉴별, 테마별 레스토랑 랭킹을 파이차트, 히스토그램 등으로 설명
•만족도: 매장, 메뉴에 대한 구매자의 만족도를 시계열 그래프로 처리
ABRC-3.indd 36 2017-11-02 오전 1:31:13
37.
37
▲인기도 시각화
•인기도: 지역,메뉴, 매장별 소비자의 관심의 정도를 파이차트로 시각화
개발 포인트
기술 주요 개발 내용
국가별 맞춤형
정보 제공
•웹 크롤러 개발(Web Crawler)을 통해 비영어권 외래 관광객의 고객 리뷰
정보를 분석하여 국가별 고객 의견 분류 및 DB 구축
•감성분석으로 수집된 데이터의 국가별 선호 아이템을 분석하여 정보 제공
시각화와 다국어
처리를 통한
정보 제공
•People 랭킹 기술(People Ranking)을 도입하여 랭킹의 신뢰도를 높이고,
인기 매장 정보를 언어에 상관없이 전달하기 위해 랭킹 형태로 제공
•시각화 기술 개발(Visualization)을 통해 직관적인 데이터 전달
•속성별 분석(Attribute Analyzer)으로 복잡한 번역 과정을 거치지 않고 리뷰
에서 많이 언급되는 표현들을 제공하고, 크라우드 소싱 번역 결과를 제공
국가별 관광객
행태 분석
•웹 크롤링으로 국가별 고객 의견 분류와 브랜드 개성 분석
(Brand Personality)
•People 랭킹 기술(People Ranking)과 감성분석(Sentiment Analyzer)을
통해 국가별 선호 아이템 분석
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 37 2017-11-02 오전 1:31:13
38.
38
•빅데이터 분석 기술기반 비영어권 외래 관광객을 위한 마케팅플랫폼 구축을 통해 기업과 방한
외래 관광객을 연결함으로써 고객 만족과 관광 수입 증대 효과 기대
•구매의사결정 이론에 따라 다양한 needs를 욕구, 정보탐색, 비교, 구매, 평가로 이어지게 하여
기업의 입장에서는 고객의 욕구에 맞는 적절한 마케팅 전략의 수립이 가능케 함
•비영어권 고객의 소비성향을 분석한 결과와 이를 다국어로 제공하는 서비스를 통해 한국에 대한
다양한 정보를 제공받고 이를 비교, 구매할 수 있게 되어 고객만족도 향상
•비영어권 외래 관광객은 최근 괄목할만한 방한 빈도를 가지고 있는 그룹이지만 관광시설, 숙박
업체, 외식업체 등에 대한 다국어 서비스가 부족한 편으로 본 서비스를 통해 한국 방문 전과 방문
중 다국어로 관광정보를 제공받는 통로로 활용될 것으로 기대
•비영어권 관광객을 타겟으로 수립된 통합 마케팅 전략을 마케팅 플랫폼을 통해 즉시 수행하고
그 결과를 feed-back 받을 수 있어, 데이터 기반 전략과 전술의 수정이 가능하여 관광객 만족도
향상과 수입 증대
•각 국가별 해당 브랜드에 대한 이미지와 만족도를 측정함으로써 향후 해외 진출시 현지 소비자
대상의 마케팅 전략 수립의 기초자료로 활용함
•2015년 7월 외식산업에 빅데이터 분석을 접목한 기술로 동문파트너즈, 엔젤투자, 중기청 RD
지원금 등을 통해 총 11억 원 규모의 투자 유치
기대효과 및 향후 발전방안
성과 홍보
사례
ABRC-3.indd 38 2017-11-02 오전 1:31:13
40
05 (주)위세아이텍
기업의
사업추진
배경
보험 급여부당청구건 증가와 이에 대한 조사의 한계
•병원, 의원과 약국 등의 요양기관의 부당청구1)
금액이 해마다 증가하고 있음
•자동차 보험을 악용해 작은 접촉사고에도 병원에 입원을 감행하는 운전자들과 위장 환자들을
무분별하게 수용하는 관행 또한 계속되고 있음
•요양기관들의 부당청구는 공모, 인력 편법 운영 등으로 은밀하게 이루어져 적발하기 쉽지 않아
사회적 문제로 심화됨
•부당청구는 국가 재정을 축내는 범죄행위지만, 조사 인력의 한계와 조사에 대한 거부감 등으로
인한 의료현장의 반발로 현지조사2)
가 어려운 상황
머신러닝과 인공지능을 활용한 부당청구건 조사 필요
•부당청구 데이터에서 패턴을 판별하는 기존의 룰 기반 방법은 방대한 양의 데이터에 대한 분석과
룰 도출을 위한 수작업이 필요
•룰 기반 부당청구 탐지 방식은 새로운 부당청구 패턴의 등장에 빠르게 대응하지 못하는 한계점을
가지고 있음
•머신러닝과 인공지능 기술을 통해 데이터에 대한 빠른 분석과 학습이 가능하고, 이를 통해
기존에 발견하지 못했던 새로운 부당청구 패턴을 추출할 수 있음
머신러닝과 인공지능을 활용한 사고 다발생 이상 패턴 분류, 탐지 및 요양급여 부당청구 탐지
시스템 개발
주제
지원배경_서비스 개발의 필요성
기업의 요청사항
센터의
지원내용 2016.10~현재
사고 다발생 데이터, 보험사 송부 이미지 데이터, 요양급여 청구 데이터
지원기간
활용 데이터 종류
1) 환자를 진료하지 않고도 진료했다거나 약을 처방하는 등 거짓으로 요양 급여를 청구하는 것
2) 병원 등 요양기관이 환자를 진료하고 적법한 급여를 청구했는지 직접 기관에 방문해 조사함
ABRC-3.indd 40 2017-11-02 오전 1:31:13
41.
41
•사고 다발생 환자탐지 모형: 사고 다발생 이상 패턴을 학습하고 분류 탐지를 통해 환자를
조기에 예측하는 탐지 모형
•사고 다발생 환자 세그먼트 분류: 기관과 환자의 데이터를 클러스터링 알고리즘을 통해 군집의
통계량을 분석하고 프로파일 정의
•사고 이미지 분류: 보험사에서 송부한 이미지 데이터를 대상으로 사고 이미지와 사고 외 이미지를
유사도 기반으로 분류
•부당청구 패턴분류:
- 머신러닝 알고리즘 중 비 지도 학습 알고리즘을 사용해 클러스터링 진행
- 추출된 군집으로부터 부당 청구 건에 대한 새로운 패턴 추출
•부당청구 패턴 판별:
- 분류된 부당청구 데이터를 통해 분류모델을 훈련시키고, 이를 사용한 신규 요양급여 청구건에
대한 유형을 분류
- 부당청구 기관 분류 기계학습 모델 구성 및 성능 측정
•부당청구 탐지 모형:
- 부당청구 현지조사 결과 데이터에서 부당청구 패턴을 학습하고, 학습된 탐지모형을 통해 신규
청구건의 부당여부를 예측, 분류
- 부당청구 기관 탐지 기계학습 모델 구성 및 성능 측정
분석 내용 및 분석 기법
센터의
지원 성과 주요 분석방법
•아웃라이어: 특정 데이터 변수의 분포에서 비정상적으로 벗어난 값으로 통계분석 및 클러스터링,
인접성 기반 분석, 고차원 아웃라이어 분석 등에 활용되는 개념
•4분위수를 이용한 분석:4분위수3)
를 사용하여 데이터 집합의 범위와 중심 위치를 신속하게 평
가할 수 있음
•시각화를 이용한 분석: 히스토그램 및 Scatter차트4)
를 이용해 아웃라이어를 제거하고 데이터의
분포를 맞출 때 사용
•K-means 클러스터링5)
: 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작해 클러
스터에서 의미 없는 값을 측정해 아웃라이어로 선택하는 방법
•6)
K 최근접 이웃 알고리즘(k-nearest neighbor): 아웃라이어 탐지 시 아웃라이어에 관한 대표
적 데이터를 지정해 학습을 진행하여 데이터 분석
지원 결과
3) 사분위수는 측정값을 낮은 순에서 높은 순으로 정렬한 후 4등분 했을 때 각 등위에 해당하는 값
4) 데이터를 점 그래프로 나타낸 차트
5) 데이터를 K개의 클러스터로 묶는 알고리즘
6) 기존 데이터 중 가장 유사한 K개의 데이터를 이용해 새로운 데이터를 예측하는 방법
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 41 2017-11-02 오전 1:31:14
42.
42
유사도 기반 이미지검색
•Lucene의 이미지 검색 라이브러리인 LIRE(Lucene Image REtrieval)7)
를 이용하여 유사 이미지
검색 수행
•유사 이미지를 검색하는 방법은 웹 서버에 저장되어 있는 사진들을 LIRE 라이브러리 중 하나인
CEDD(Color and Edge Directivity Descriptor)8)
를 이용할 수 있음. 이를 이용하여 이미지의 특징
을 추출하고 미리 색인하여 파일 형태로 저장함
사고 이미지 분류 결과 데모
•보험사가 제공한 이미지 데이터를 사고 이미지와 사고 외 이미지로 유사도 기반하여 분류하고
분류 이미지 간의 유사도를 수치화 하여 유사 정확도의 평가가 가능함
•향후 사고 이미지에서 차량의 유형(영업영, 소형, 대형), 사고의 중증도(접촉사고, 경미, 중태),
사고유형(대인, 차량) 등의 이미지 속성을 추출하여 정형화된 데이터로 변환하여 과다청구
가능성의 예측에 변수로 사용 가능
•선택한 이미지와 동일한 이미지도 색인이 되어있기 때문에, 유사도가 1인 이미지를 제외한
이미지가 최종적으로 출력됨
▲특징점 추출의 원리
7) Image에서 몇 가지 descriptor를 추출한 다음 Lucene에 각 descriptor를 하나의 필드로 해서 indexing 및 retrieval하는
자바기반의 라이브러리
8) 이미지 블록으로부터 HSV 색 공간에서 색 히스토그램을 추출하여 컬러 유닛을 계산하고, YIQ 색 공간에서 광도를 추출
하여 텍스쳐 유닛을 계산하여 양자화하는 과정으로 이루어짐
ABRC-3.indd 42 2017-11-02 오전 1:31:14
43.
43
신규 부당청구 패턴분류, 판별 및 탐지 모형 개발
•요양급여 부당청구와 관련된 세 가지 분류·탐지 모형을 구성 후 타당성 평가
▲사고 이미지 분류 결과 데모
▲분류·탐지 모형 개발 프로세스
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 43 2017-11-02 오전 1:31:14
44.
44
신규 부당청구 패턴분류 모형 개발
•요양급여 청구 데이터를 학습하여 숨겨진 패턴을 분류하고 분류된 패턴에서 알려지지 않은
새로운 유형을 정의
•머신러닝 알고리즘을 이용하여 신규 부당청구 패턴의 효율적 개발 가능성 평가
•청구 데이터에 대한 비지도 학습을 통해 신규 부당청구 패턴 분류
신규 부당청구 패턴 판별 모형 개발
•새롭게 분류된 패턴 유형을 학습하고, 학습된 판별 모형을 통해 신규 청구건에 대해 해당하는
패턴 유형 판별
•새롭게 발견된 부당청구 패턴을 판별 모형화 하여 패턴의 검증 및 시범운영을 위한 방법 제공
•신규 부당청구 패턴 분류를 위한9)
클러스터링(군집화) 알고리즘: K-means, SOM, EM,
Canopy
•군집화는 이미 정해진 정답이 없는 비지도 학습에 의한 분류 기법으로 군집내의 데이터는 동질
집단으로 구성되고 군집간의 데이터는 서로 다른 이질집단으로 구분
•청구명세서 데이터를 유사도를 기준으로 K개의 청구패턴 유형으로 분류 후 패턴의 업무적
유용성 입증
•안과 전체 1개월 청구명세서 데이터를 대상으로 클러스터링을 진행하여 5, 7, 10개의 패턴
그룹으로 분류하여 실제 부당 건을 모집단에 포함시켜 분류 결과 분석 및 검증 진행
•라식, 라섹 기조사 결과 데이터를 대상으로 클러스터링을 적용하여 3, 5, 10개의 패턴그룹으로
분류하고 패턴그룹의 검증을 위해 실제조사 결과 정상건과 부당건을 대조군으로 분석
•라식, 라섹 기조사결과 부당으로 적발된 데이터를 대상으로 5, 8, 10개의 부당청구 패턴그룹으로
분류 후 실제 적발된 부당청구건의 변수의 통계량을 분석하여 프로파일링을 수행하고 유의한
부당패턴 도출
▲청구 데이터의 비지도 학습을 통한 신규 부당청구 패턴 분류모형 구성
9) 복잡한 데이터를 유사한 항목끼리 그룹지어 집합으로 묶음
ABRC-3.indd 44 2017-11-02 오전 1:31:14
45.
45
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
부당청구 탐지 모형 개발
•부당청구 조사결과 데이터에서 부당청구 패턴을 학습하고, 학습된 탐지모형을 통해 신규 청구건의
부당여부 탐지
•기존 룰기반 탐지 시스템 대비 모형의 탐지 정확도를 비교하여 인공지능 모형 기반 부당청구
탐지의 타당성을 평가
•기계학습 알고리즘 (10)
Decision Tree, 11)
Random Forest, Support Vector Machine12)
) 사용
•분류된 청구데이터 패턴을 분류모형으로 지도학습하여 패턴 분류모형으로 구성하고 의사결정
트리(decision tree) 알고리즘을 사용하여 의사결정트리 그래프와 if() then 형태의 rule을 분류
기준으로 설명
•학습된 청구 패턴분류 모형을 이용하여 1개월분(13만건) 미조사 신규 청구건에 대해 청구패턴을
분류하여 부당패턴 판별
▲신규 부당청구 패턴 판별모형의 구성
▲현지조사결과 데이터의 지도학습을 통한 부당청구 탐지모형의 구성
10) 분류 클래스와 변수들의 관계를 규칙으로 도출하고 트리의 형태로 분기하는 가장 기본적인 분류 알고리즘
11) 다수의 decision tree들이 앙상블 모델을 구성하여 각각의 예측결과를 하나의 결과 변수로 평균화하는 알고리즘
12) 데이터의 분포공간에서 가장 큰 폭의 경계를 구분하여 데이터가 속하는 분류를 판단하는 비확률적 알고리즘
ABRC-3.indd 45 2017-11-02 오전 1:31:14
46.
46
•알고리즘(Decision Tree, RandomForest, Support Vector Machine, Neural Network13)
,
Elastic Net14)
, Deep Learning15)
) 사용
•부당청구 탐지모형의 후보 알고리즘간 성능 평가 지표는 accuracy, precision, recall을 사용하며,
현지 조사 업무에서는 부당에 대한 recall의 향상에 가중치를 부여함
•전체 85,000건의 조사결과 중에서 부당 적발건은 1%에 해당하는 데이터 불균형이 존재하므로
under sampling을 통해 데이터 불균형 해소
•부당 청구 탐지모형의 후보 알고리즘간 성능을 평가한 결과 40% under sampling에 의한
random forest 알고리즘 적용이 가장 우수함
▲탐지모형의 알고리즘 부당 recall 비교
딥러닝을 이용한 부당청구 탐지모형의 구성과 탐지결과
•새롭게 분류된 패턴 유형을 학습하고, 학습된 판별 모형을 통해 신규 청구건에 대해 해당하는
패턴 유형 판별
•새롭게 발견된 부당청구 패턴을 판별 모형화 하여 패턴의 검증 및 시범운영을 위한 방법 제공
13) 인간 두뇌의 뉴런과 시냅스에 의한 정보처리, 추론을 모방해 복잡한 패턴을 인식하는 인공신경망 알고리즘
14) 회귀분석의 예측오류를 개선하기 위해 패널티 부여를 통해 예측력을 향상시킨 패널라이즈드 회귀모형
15) 다층구조의 neural network를 기반으로 변수의 패턴이 결과에 미치는 영향을 가중치로 조절해 학습하는 알고리즘
ABRC-3.indd 46 2017-11-02 오전 1:31:14
47.
47
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
•딥러닝 알고리즘은 데이터의 양과 hidden layer의 구조에 따라 성능의 차이가 크게 달라지기
때문에 다양한 layer 구조로 성능 최적화 시도
•분석 결과 random forest의 탐지 성능이 가장 우수하며 딥러닝의 경우 충분한 데이터와 모델
최적화로 성능 향상이 가능함
•수작업 중심의 부당패턴탐지 과정을 기계에 의한 자동화가 가능하도록 구현하였을 뿐 아니라
기계학습, 딥러닝 알고리즘을 통한 이상치 탐지 기술을 사용한 FDS 고도화로 부당패턴에 대한
기술적 탐지력을 향상시킴
•이상치 탐지 기술을 이용한 금융사기 방지, 청구내역 패턴 사전 판별 등의 과학적 접근을 통한
부당청구 조기 대응으로 세금 누수와 편법공모 등의 사회병리 해결
▲딥러닝을 이용한 부당청구 탐지모형
개발 포인트
기대효과 및 향후 발전방안
기술 주요 개발 내용
사고 다발생 환자
세그먼트 프로파일 정의
•머신러닝 비지도 학습을 통한 사고 다발생 환자 군집화 결과 제공
•사고 다발생 환자 군집의 특성을 분석하는 프로파일링 결과 제공
유사도 기반
이미지 검색
•이미지 데이터를 사고 이미지와 사고 외 이미지로 유사도 기반 분류한
결과 제공
•LIRe를 사용한 이미지 유사도 기반 분류 가능성을 프로토 타이핑한
결과 제공
부당청구 패턴분류 및
판별모형 개발
•머신러닝 비지도 학습을 통한 부당청구 패턴 분석 및 도출 결과 제공
•머신러닝 알고리즘과 딥러닝 알고리즘을 통한 부당청구 판별 모형과
판별 결과 제공
ABRC-3.indd 47 2017-11-02 오전 1:31:14
48.
48
06 플러스메이(주)
기업의
사업추진
배경
뷰티서비스산업 시장규모의성장
년도 (2016년)
기준
(2017년)
개발 종료후 1년
(2018년)
개발 종료후 3년
세계 시장 규모 중국시장기준 33조 40조 내외 50조 이상
한국 시장 규모
뷰티서비스
5조 내외
7조5천 내외 10조 내외
화장품 리뷰 시각화 분석 시스템 개발
※참고: 파이낸셜뉴스 (2016.2.4.) http://www.fnnews.com/news/201602041814450920
기사자료에 의하면 국내 뷰티전체 19조 뷰티서비스 규모는 7조원으로 추산
주제
지원배경_서비스 개발의 필요성
•2011년 통계청 기준 뷰티서비스산업의 매출액은 4조 9,710억원으로, 헤어미용의 경우 3조
9,846억원(80.16%)이며 피부미용은 6,900억원(13.88%), 네일 등 기타 미용업은 2,964억원
(5.96%)을 각각 차지하고 있음
•뷰티 산업 중 화장품산업의 시장규모는 6조 5,898억 원으로, 현재 추세를 고려했을 때 향후
뷰티서비스산업의 시장 규모는 2017년 약 7조 5천억 원으로 성장할 것으로 추산
▲뷰티서비스산업 시장규모 및 뷰티서비스 분류별 매출액(자료: 통계청(2012)
ABRC-3.indd 48 2017-11-02 오전 1:31:14
49.
49
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
폭발적으로 증가하는 화장품 정보를 파악하는데 겪는 어려움
•사용자들은 더욱 쉽게 다양한 정보를 얻을 수 있게 되었지만, 반면 과다한 정보로 인해 어떻게
자신에게 가치 있고 적합한 정보를 찾아 낼 것인가의 문제에 부딪힘
•사용자는 자신의 선호에 부합하는 정보를 찾는데 시간과 비용을 투자해야 하고 찾은 정보가
적절하지 않을 경우에는 시간과 비용의 낭비를 초래하게 됨
•미국 온라인 도서 구매 사이트 Amazon, 미국 온라인 DVD 대여 사이트 Netflix, 국내 영화 추천
사이트 Watcha 등에서 모두 추천 엔진을 통한 서비스를 사용자들에게 맞춤 제공하고 있음
•K-Beauty가 주목받으며 유통을 확장하고 있는 상황에서 거대한 뷰티 아이템의 정보들로
사용자들이 찾아봐야 할 콘텐츠와 정보의 양이 기하급수적으로 증가함
•국내외 사용자들에게 유용한 정보와 콘텐츠를 선별해 제공하는 시스템의 필요성이 커짐
제품 정보를 효과적으로 제공할 서비스 필요
•Naver, SNS(Social Network Service) 데이터 분석을 통한 뷰티 큐레이션(Curation) 기술로
사용자에게 다양한 뷰티 아이템에 대한 정보를 선별해 제공할 필요성 인지
•국내 대표 포털 사이트 제공 데이터를 통해 제품 정보 추출, 이를 기반으로 신뢰도 높은 서비스를
진행 가능
•리뷰 텍스트 감정어 추출과 다양한 기계학습 알고리즘을 적용해 제품 정보 파악, 시스템 성능 개선
•정보를 효과적이고 흥미롭게 제공할 시각화(Visualization) 기반 텍스트 제공 서비스 필요
기업의 요청사항
2016.02~2016.10
지원기간
•Beauty 정보와 관련된 리뷰 데이터(리뷰 제목, 본문, 태그, URL, 리뷰 이미지 등), 뉴스, 블로그
등의 정보를 수집하는 것을 목표로 함
•기본 데이터베이스는 네이버 쇼핑과 같은 전문 사이트로부터 사용자 연령대별, 평점별 화장품
선호도에 관한 리뷰 데이터를 수집
활용 데이터 종류
•컨텐츠 수집 시스템 (Contents Crawl System): 웹 크롤러 (Web Crawler)
•텍스트 분석 시스템 (Text Analyzer): 감성분석(Sentiment Analyzer)
•네트워크 시각화(Network Visualization) 시스템: Word2Vec
분석 내용 및 분석 기법
센터의
지원내용
ABRC-3.indd 49 2017-11-02 오전 1:31:14
50.
50
센터의
지원 성과
지원 결과
▲화장품리뷰 수집 및 분석 시스템 전체 흐름도
▲rating과 리뷰 불일치의 예
컨텐츠 수집 시스템(Contents Crawl System): 웹 크롤러(Web Crawler)
•래퍼 기반 크롤러를 사용해 온라인 화장품 리뷰를 수집 및 저장
•온라인 쇼핑 사이트에서 각종 화장품 브랜드를 나열한 웹 페이지 내 화장품 브랜드 url들을
웹페이지의 구조 정보를 이용해 자동 추출
•1차 수집한 리뷰는 전처리 과정을 거쳐 유의미한 단어로 추출 후 형태소 분석을 통해 유의미한
명사와 형용사 정제
•가공된 데이터들은 시각화 모듈을 거쳐 사용자에게 정보 제공
텍스트 분석 시스템(Text Analyzer): 감성분석(Sentiment Analyzer)
•화장품 리뷰에는 화장품에 대한 rating이 포함되어 있는데 이는 화장품에 대한 사용자의 만족도를
표시함
•사용자 특징 중 긍정 리뷰에 rating을 낮게 주거나 부정적 리뷰에 높은 rating을 주는 등 rating과
실제 내용상의 평가가 다른 경우가 발생해 리뷰를 내용 기준으로 분류해야 함
★
완전 감사감사요br잘 쓸게용~~♡♡♡br서비스로 여러가지 상품을 주셨네요^^
완전 감사감사요 잘 쓸게용~~♡♡♡♡ /div
★★★★★
건성피부이라 겨울철이면 당기고 건조해서 에센스를 주문하면서
메이커 제품이고 구매자가 많길래 했더니 넘 묽어서 실망했습니다. /div
ABRC-3.indd 50 2017-11-02 오전 1:31:14
51.
51
▲교차검증 예
네트워크 시각화(NetworkVisualization) 시스템: Word2Vec
•시각화는 각종 정보를 그래프, 차트, 이미지, 지도 등을 통해 전달하는 기술로 서비스 이용자의
직관적 이해력을 높일 수 있는 정보전달 핵심 기술
•사용자가 보고자 하는 랭킹정보, 통계 정보, 레스토랑 관련 정보 등을 사용자의 편의를 위해
파이차트, 히스토그램, 음성합성 등이 포함된 멀티미디어 프리젠테이션 기법 등으로 보여주는
기술 개발
•Word2vec기법을 사용해 구한 유사도는 단어의 스펠링과는 상관없이 단어의 의미에 따라서 계산 됨
•Word2vec에서 유사도를 계산 하는데는 구하고자하는 두 단어를 벡터화 하여 각 벡터 사이의
코사인 값을 구하는 Cosine similarity알고리즘 사용
•계산해 얻은 유사도를 직접 사용해 Network graph를 그림
•Network graph는 단어들 사이의 거리가 가까울수록 유사도가 높다는 의미
•Word cloud, Network graph, Piechart로 구성된 Dashboard를 사용자에게 제공
•성능 측정을 위해 k-fold cross validation으로 데이터 셋을 구성
•분류를 위해 기계학습을 사용했으며 Naive Bayes, Support Vector Machine, Decision Tree,
Random Forest 기법을 테스트적용 한 후 그 중 가장 적합한 성능의 Random Forest를 분류기로
사용함
•10-fold cross validation으로 실험한 결과 평균적 95.6%의 정확도를 얻음
•긍정/부정 리뷰를 분류한 결과 긍정적인 리뷰는 94.2%이고 부정적인 리뷰는 5.8%라는 결과 도출
•리뷰 데이터에서 나타나는 각 단어의 빈도수를 계산하여 word cloud로 도식화
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 51 2017-11-02 오전 1:31:14
52.
52
▲분석 결과 대시보드
개발포인트
기술 주요 개발 내용
컨텐츠 수집
시스템
•웹 크롤러(Web Crawler) 개발을 통해 국내 포털의 데이터를 수집해 제품에
대한 상세 DB 구축
•전문 사이트로부터 사용자의 연령, 평점, 선호도에 대한 상세 데이터 수집
후 분석하는 기술 제공
텍스트 분석
시스템
•한국어 텍스트 분석을 통해 제품 키워드와 감정어를 추출하는 감성분석
기술 제공
•기계학습 알고리즘을 적용해 제품의 정보를 파악할 수 있는 기술 제공
네트워크 시각화
(Network Visualization)
시스템
•키워드의 빈도를 시각화해 사용자가 제품의 특성을 한 눈에 파악할 수 있도록
돕는 시각화 서비스 제공
•제품 키워드들 간의 관계를 살펴볼 수 있는 네트워크 그래프 시각화를 통해
사용자의 제품 정보에 대한 빠른 이해를 도움
기술적 측면
•뉴스, 웹, SNS등 데이터 수집을 위한 Crawler 개발
•정형 데이터를 활용한 통계적 분석(statistic analysis) 기술, 알고리즘 연구 강화
•Text Mining을 위한 비정형 데이터 전처리(Preprocessing) 기술 개발과 감정 분류기를 통한
Opinion Mining 기술 연구 강화
기대효과 및 향후 발전방안
ABRC-3.indd 52 2017-11-02 오전 1:31:14
53.
53
산업적 측면
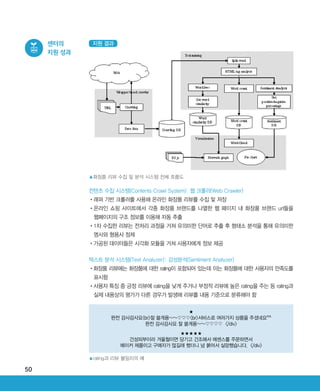
•Text Mining을사용한 제품 리뷰 텍스트 분석, Term Frequency 측정 통한 특징 값 추출,
Topic, Trend 파악 등 빅데이터 분석 기술을 타겟 마케팅 활용의 영역 확장
•국내 IT 중소기업과 산학 협력을 통한 콘텐츠 경쟁력 강화에 기여
•외국인 관광객 대상 K-Beauty 활성화에 기여
•상품 트렌드 분석을 통한 소비자의 선호도 이용, 상품 재고 관리 최적화 가능
•중소 브랜드의 진입 장벽을 낮추어 소비자 노출 기회를 증대시킴으로써 중소기업 활성화에 기여
사회적 측면
•국내 대표 포털이 보유하고 있는 정형 및 비정형 데이터를 통해 신뢰도 높은 소비자들의 성향
파악 가능
•서비스, 상품 구성에 소비자 경향 반영함으로써 고객 만족도 향상
•K-Beauty를 중심으로 한 뷰티 산업 활성화를 시작으로 국내 관광객 유치 활성화 기대
•Text Mining과 다양한 기계학습 알고리즘을 접목한 추천시스템 성능 향상
•텍스트 정보를 효과적으로 제공하기 위한 Word Cloud 등의 Visualization 기술 개발로 사용자
중심의 서비스 제공
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 53 2017-11-02 오전 1:31:14
54.
54
07 (주)플렉싱크
관광 블로그및 리뷰에 대한 감성분석 및 시각화 플랫폼 개발주제
기업의
사업추진
배경
제주도의 관광객 유치 확대를 위한 지속적인 노력 필요
•세계 관광시장의 규모는 지속적으로 확대되고 있으며 각국의 관광산업 육성 경쟁이 심화되는
추세
•중국경제 성장과 소득 증가로 중국인의 해외관광이 늘고 있고 회당 소비규모가 커 세계 관광업계의
핵심고객으로 부상중인 상황
•한국의 대표적 관광지인 제주를 방문한 중국인 관광객은 외국인 관광객중 높은 비율을 차지함
•방한 일본인 관광시장이 약세에 접어듬에 따라 중국인 관광시장이 제주관광의 주요 변수로 작용
지원배경_서비스 개발의 필요성
제주 방문 중국인 고객 분석 플랫폼의 필요성 대두
•제주도를 찾는 중국인 관광객 수가 한류의 영향을 받아 급격히 늘어났지만 근래는 한국 여행에
대한 중국인 관광객의 열정도 식어가는 추세를 보이고 있음
•관광산업의 트렌드 변화에 지속적으로 대응책을 마련하고 제주의 주요 시장인 중국인 관광객의
요구 변화에 주목하여 관광행태와 욕구를 주도할 수 있는 관광정책 및 상품을 개발하여 관광
시장에서의 경쟁우위를 높이고자 함
•여행지에 대한 정보를 찾을 때 많은 데이터를 한눈에 파악하기 어려운 문제를 해결하고 각
지역에 관한 관광 리뷰 블로그와 리뷰를 수집해 분석하고 사용자에게 시각화 서비스가 필요함
기업의 요청사항
2015.10~현재
지원기간
•관광 리뷰 데이터 (텍스트)
•관광 블로그 데이터 (텍스트)
활용 데이터 종류
•데이터 수집 및 전처리
•속성별 사용자 의견 분석: 속성 사전 구축, 속성 분류, 감성 분석, 빈도수 분석
•데이터 시각화: 시계열 그래프, 방사형 그래프, wordcloud, 네트워크 그래프
분석 내용 및 분석 기법
센터의
지원내용
ABRC-3.indd 54 2017-11-02 오전 1:31:14
55.
55
센터의
지원 성과 데이터수집 및 전처리
•Ctrip, Mafengwo, TripAdvisor, Tuniu라는 네 개의 사이트에서 관광 리뷰와 블로그를 수집하며,
그 중 관광 리뷰는 Ctrip과 TripAdvisor, 관광 블로그는 Ctrip, Mafengwo, Tuniu 세 개의 사이트에서
수집
•웹사이트에서 데이터를 수집할 때는 웹사이트 소스코드를 읽어 데이터를 추출하여 수집하는데,
Python에서는 urllib이라는 패키지를 사용하여 웹사이트 소스코드를 불러옴
•html태그안의 데이터를 추출하기 위해 BeautifulSoup이라는 패키지를 사용해 원하는 태그 추출
•“Chinese data”라는 텍스트 데이터를 수집하기 위해 “class1”이라는 class이름을 가지고 있는
div태그를 탐색, 그 안에 있는 a태그를 탐색하고 텍스트 데이터 추출
최종 분석 결과 (개발 완성내용)
▲웹사이트 소스코드
수집한 데이터 양
데이터 유형 사이트 지역 데이터 건수
리뷰
Ctrip
제주도 22,387
서울 138,873
오사카 71,518
TripAdvisor 1,129
블로그
Ctrip
제주도 2,337
서울 2,771
오사카 1,644
Mafengwo 697
Tuniu 268
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 55 2017-11-02 오전 1:31:14
56.
56
•THULAC(THU Lexical Analyzerfor Chinese)라는 중국어 전용 형태소 분석기는 중국어 단어
품사를 표기하는데 92.9%라는 높은 정확도를 가짐
•감성 분석에는 형태소 분석기를 사용하지 않고 문장에서 불필요한 단어만 제거
•형태소 분석기를 사용해 명사와 형용사를 추출하여 빈도수를 측정하고 단어 간 상관관계를 계산
속성별 사용자 의견 분석: 속성 사전 구축, 속성 분류, 감성 분석, 빈도수 분석
•사전 검색을 위하여 우선 명사만 포함된 사전이 필요한데, 한 번에 완성도가 높은 사전을 구축
하기 어려움
•인위적으로 각 속성에 해당하는 명사를 인터넷에서 검색하여 1차 속성 사전 작성 후 16)
인터넷
사전에서 동의어와 상관단어를 수집해 2차로 구성된 속성사전 완성
•확장한 사전에는 불필요한 단어들이 많이 포함되어 있어 인위적으로 제거 작업 돌입
•속성사전을 이용하여 수집한 블로그와 리뷰에 대한 속성검색 진행
16) Baidu 사전에서는 상관단어를 수집하고, Youdao 사전에서는 동의어를 수집해 사전 구성
▲Baidu사전
▲속성 카테고리 분류 흐름도
시작
데이터 읽기
형태소 분석기
명사와 형용사를 추출사전 읽기
명사를 추출
끝
해당 사전 카테고리로 분류
◀◀◀
◀
◀
◀◀
◀◀◀◀
‘가격’
사전인가?
네
아니요
아니요 사전에 포함된
단어인가?
네
ABRC-3.indd 56 2017-11-02 오전 1:31:14
57.
57
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
•사용한 속성 카테고리는 모두 8가지가 있는데 그 중 ‘가격’ 속성은 유일하게 명사와 형용사를
다 사용하여 분류하는 속성
•중국어에서 가격에 관한 명사는 많지 않은 반면 ‘가격’을 묘사할 때만 사용하는 형용사가 존재
하므로 가격 속성 카테고리를 분류할 때는 형용사와 명사를 모두 사용
•속성 사전에서 추출한 명사 및 형용사와 비교하여 해당 속성 사전에 같은 단어가 있으면 해당
사전 카테고리로 분류
•리뷰는 한 곳의 관광지, 숙박시설, 음식점에 대한 평가지만 블로그는 복수의 관광지, 숙박시설,
음식점에 대한 평가이기 때문에 속성 검색 진행 전 ‘숙박업소음식점’, ‘관광지레저’ 두 개
유형의 데이터로 분류하는 과정 선행
•두 개 유형의 데이터에 속하는 가게나 관광지명이 공동으로 포함되어 있는 단어를 제주관광공사
공식 홈페이지에서 수집
•감성분석은 감성사전을 사용하지 않고 부정의 의미를 가진 문구와 긍정의 의미를 가진 문구로
만들어진 데이터 셋으로 분석
•랜덤 포레스트(Random Forest) 머신러닝 알고리즘을 사용
•각 문구들의 벡터 값을 구하는 과정이 필요한데 이런 벡터 값을 구하기 위해 문서단어행렬
(Document term Matrix)을 사용해 82%로 성능 향상
속성 사전 이름과 데이터 양
블로그 내용 분류용 단어 사전
유형 속성 카테고리 단어 수
공통
예의와 친절 320개
지역특색 306개
접근성 296개
숙박업소 음식점
가격 27개
분위기 62개
관광지 레저
오락성(흥미) 44개
풍경과 볼거리 351개
체험성 43개
유형 단어 개수
관광지 레저
산, 화산, 동굴, 계속, 폭포, 휴양림, 유산,
수목원, 관, 승마장, 생태, 지질, 골프 등
78개
숙박업소 음식점
호텔, 리조트, 펜션, 게스트하우스, 모텔,
여인숙, 감자탕, 돼지, 고기, 식당, 국 등
83개
ABRC-3.indd 57 2017-11-02 오전 1:31:15
58.
58
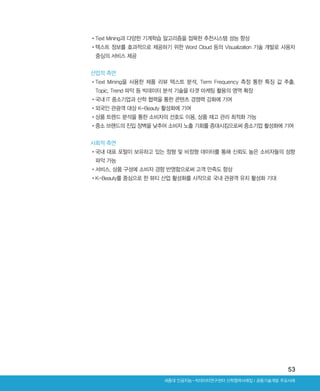
•단어 빈도수를 통하여문장에서 어떤 단어들이 많이 언급되는지 파악해 리뷰 내용 유추 가능
•단어 빈도수를 계산할 때는 형태소 분석기를 통하여 명사와 형용사만 추출하였으며 시각화에
Wordcloud 사용
데이터 시각화: 시계열 그래프, 방사형 그래프, wordcloud, 네트워크 그래프
•중국어 관광 리뷰의 개수를 월별로 보여주는 시계열 그래프
▲블로그에 대한 시계열 그래프
ABRC-3.indd 58 2017-11-02 오전 1:31:15
59.
59
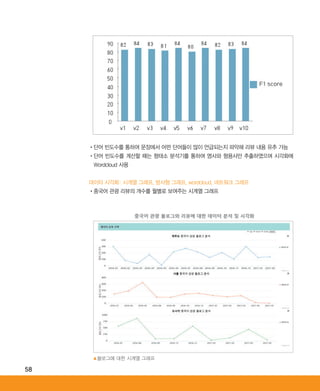
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
•방사형 그래프는 선택한 지역과 날짜에 근거하여 각 속성 카테고리에 속하는 데이터의 감성분석
결과를 보여줌
•Wordcloud는 단어 빈도수에 근거한 시각화 자료로 활용
•단어 간 상관관계를 python의 gensim이라는 라이브러리에 속하는 Word2vec 알고리즘을 사용
하여 계산하여 네트워크 그래프 생성
▲감성분석을 시각화한 방사형 그래프
▲속성 선택 시 보여주는 Wordcloud
ABRC-3.indd 59 2017-11-02 오전 1:31:15
60.
60
▲속성 선택 시보여주는 네트워크 그래프
개발 포인트
기술 주요 개발 내용
중국어 데이터
수집
•중국 관광객을 대상으로 특화된 리뷰와 블로그 데이터 수집
•중국인 관광객의 리뷰와 블로그를 네 개 사이트 (Ctrip, Mafengwo,
TripAdvisor, Tuniu)에서 광범위하게 수집해 텍스트 데이터 분석을 위한
데이터베이스 구축
텍스트 속성 분석
•중국어 기반 관광관련 속성 사전을 구축하고 분류하는 기술 제공
•텍스트 감성 분석을 통해 관광 리뷰와 블로그 글에 대한 분류 정보 제공
•텍스트로부터 키워드를 추출하고 빈도수를 분석함으로써 사용자에게
양질의 정보를 제공하는 분석 결과 도출
시각화 서비스
•시계열 그래프, 방사형 그래프, wordcloud, 네트워크 그래프
•다양한 형태의 그래프를 통해 텍스트로부터 추출한 정보를 효과적으로
전달하는 시각화 기술 제공
•사용자들이 관광지에 대한 정보를 빠르게 이해하고 파악할 수 있도록
돕는 서비스 개발
명사
긍정
부정
높다
싸다
크다
편리하다
괜찮다
비싸다
번거롭다
번화하다
화려하다
화려하다
쉽다
대중교통
인기많다
유명하다
청결하다
좋다
자동차
지방
위치도로
택시
버스
구역
차량
교통
기차지리
중앙시하시장
일반적으로
ABRC-3.indd 60 2017-11-02 오전 1:31:15
61.
61
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
기대효과 및 향후 발전방안
•빅데이터 분석 기술을 기반으로 구축한 중국인 관광객용 마케팅플랫폼을 통해 고객 만족과 관광
수입 증대 효과 기대
•구매의사결정 이론에 따라 다양한 needs를 욕구, 정보탐색, 비교, 구매, 평가로 구분해 기업이
고객의 욕구를 통합, 분석할 수 있게 되어 관광정보제공과 추천 마케팅 서비스의 질을 향상시킴
•중국인 관광객 분석 플랫폼을 통해 결과를 피드백 받음으로써 데이터에 기반한 정확도 높은
전략과 정책 결정이 가능하여 관광객 만족도 향상과 수입 증대 예상
ABRC-3.indd 61 2017-11-02 오전 1:31:15
62.
62
08 (주)스타일켓
Libre 서비스의사용자 맞춤형 추천 시스템 개발주제
기업의
사업추진
배경
SNS 인플루언서의 영향력 증가에 비해 부족한 마케팅 플랫폼
•SNS의 인플루언서에 대한 대중의 접근이 쉬워짐에 따라 등장 제품에 대한 대중의 관심또한 함께
증가하고 있음
•인플루언서 마케팅은 쇼핑몰과 중소의류업체의 성공에 필수 요소로 주목받고 있음
•많은 인플루언서들이 쇼핑몰 창업에 도전하지만 쇼핑몰 제작, 운영, 배송, 마케팅, 고객 관리 등에
많은 장애가 있음
•콘텐츠와 수익을 동시에 창출하고 싶은 인플루언서와 SNS를 즐기면서 편리하게 쇼핑하고 싶은
고객, 인플루언서를 활용한 상품 홍보와 판매를 목표로 하는 브랜드간의 거리를 좁히는 인플루
언서 기반 마켓 플랫폼이 필요
지원배경_서비스 개발의 필요성
인플루언서 콘텐츠 기반의 정보제공 서비스 개발
•SNS가 대중적인 커뮤니케이션 매체로 자리잡음에 따라 다양한 성향의 소비욕구를 지닌 이용자들이
편리하게 이용할 수 있는 서비스 개발이 요구됨
•SNS의 높은 대중 접근성을 활용해 해당 콘텐츠에 관련도가 높은 인플루언서의 콘텐츠를 커머스
플랫폼과 연결하여 해당 콘텐츠에 노출된 상품을 소비자들이 쉽게 구매할 수 있는 플랫폼을
제공하여 SNS를 상호 호환적인 마케팅 채널로 활용할 서비스 필요
•다양한 인플루언서와 제품들 중에서 사용자에게 적합한 인플루언서와 제품을 선별해 정보를
제공하는 추천 시스템이 필요
기업의 요청사항
2016.07~2016.10
지원기간
•사용자의 로그 데이터: 좋아요 태그, 스크랩, 링크공유, 웹페이지 그림 확대, 브라우징 시간
활용 데이터 종류
센터의
지원내용
•협업 필터링(Collaborative Filtering)
•사용자 기반(User_based) 추천 알고리즘
분석 내용 및 분석 기법
ABRC-3.indd 62 2017-11-02 오전 1:31:15
63.
63
•아이템 기반(Item_based) 추천알고리즘
•내용 기반(Content_based) 추천 알고리즘
센터의
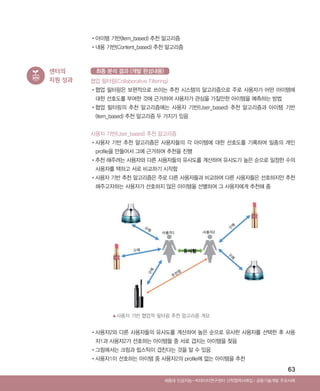
지원 성과 협업 필터링(Collaborative Filtering)
•협업 필터링은 보편적으로 쓰이는 추천 시스템의 알고리즘으로 주로 사용자가 어떤 아이템에
대한 선호도를 부여한 것에 근거하여 사용자가 관심을 가질만한 아이템을 예측하는 방법
•협업 필터링의 추천 알고리즘에는 사용자 기반(User_based) 추천 알고리즘과 아이템 기반
(Item_based) 추천 알고리즘 두 가지가 있음
사용자 기반(User_based) 추천 알고리즘
•사용자 기반 추천 알고리즘은 사용자들의 각 아이템에 대한 선호도를 기록하여 일종의 개인
profile을 만들어서 그에 근거하여 추천을 진행
•추천 해주려는 사용자와 다른 사용자들의 유사도를 계산하여 유사도가 높은 순으로 일정한 수의
사용자를 택하고 서로 비교하기 시작함
•사용자 기반 추천 알고리즘은 주로 다른 사용자들과 비교하여 다른 사용자들은 선호하지만 추천
해주고자하는 사용자가 선호하지 않은 아이템을 선별하여 그 사용자에게 추천해 줌
•사용자2와 다른 사용자들의 유사도를 계산하여 높은 순으로 유사한 사용자를 선택한 후 사용
자1과 사용자2가 선호하는 아이템들 중 서로 겹치는 아이템을 찾음
•그림에서는 크림과 립스틱이 겹친다는 것을 알 수 있음
•사용자1이 선호하는 아이템 중 사용자2의 profile에 없는 아이템을 추천
최종 분석 결과 (개발 완성내용)
▲사용자 기반 협업적 필터링 추천 알고리즘 개요
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 63 2017-11-02 오전 1:31:15
64.
64
•사용자2의 profile에서 마스카라에대한 정보가 없으므로 사용자2에게 마스카라를 추천
•이는 새로운 아이템을 선호하는 사용자에게는 유효했지만 새로운 아이템을 선호하지 않는
사용자에게는 좋은 추천 방법이 아닐 수 있음을 시스템 적용 시 고려해야 함
아이템 기반(Item_based) 추천 알고리즘
•사용자 기반 추천 알고리즘은 사용자의 선호도를 중심에 두는 알고리즘인데 반해 아이템 기반
추천 알고리즘은 아이템들 간의 유사도를 중심에 두고 있음
•아이템들 간의 유사도를 계산하여 추천 해주려는 사용자의 profile에 있는 아이템과 유사한 다른
아이템을 추천
•사용자2의 profile 아이템과 다른 사용자들의 profile에 있는 아이템들의 유사도를 계산
•그림과같이 사용자2가 선호하는 아이템과 유사한 아이템을 찾음
•사용자2의 profile에는 마스카라에 대한 선호도 밖에 없으므로 사용자2와 다른 사용자들을
비교하여 유사도가 높은 순으로 지정된 수만큼 아이템 추천
•아이템 기반 추천 알고리즘은 사용자 기반 알고리즘처럼 추천 해주려는 사용자가 선호하지 않는
아이템을 추천해주지는 않는 특징이 있음
•그래서 아이템 기반 추천 알고리즘은 아이템끼리의 유사도를 기준으로 하기 때문에 추천 해주려는
사용자의 profile에 있는 아이템도 추천 해주는 경우가 많음
▲아이템 기반 협업적 필터링 추천 알고리즘 개요
ABRC-3.indd 64 2017-11-02 오전 1:31:15
65.
65
내용 기반(Content_based) 추천알고리즘
•내용기반(content_based) 추천 알고리즘은 아이템의 속성에 기반 한 접근 방법으로 예를 들어
특정 작가의 책을 좋아하는 사용자가 해당 작가의 책을 추천하는 것은 작가라는 속성에 기반한
내용기반 추천방식
•효율적인 내용 기반 추천시스템을 만들기 위해서는 많은 속성들이 필요하나, 특정 영역에 국한된
도메인 지식은 다른 아이템에서는 사용할 수 없음 (예, 도서추천 시스템을 위해서는 페이지 수,
저자, 출판사 등 의미있는 속성을 결정짓게 되는데 다른 아이템에 적용하기에는 힘든 개념)
Python 추천 프레임워크 Crab 사용
•Crab은 Python에서 추천 시스템을 구현하는 프레임워크로 사용자 기반 사용자 기반(User_
based) 추천 알고리즘
•{user id:{item id:preference, item id2: preference, ...}, user id2: {...}, ...}
•추천 알고리즘에 사용할 데이터는 사용자 ID와 아이템 ID 그리고 사용자의 아이템 선호 수준을
표현하는 숫자(preference)로 구성
•보통의 추천 알고리즘은 코사인유사도(cosine similarity)로 사용자들의 유사도를 계산하는데 이
코드에서는 유클리디안 거리(Euclidean distance)17)
로 사용자들의 유사도를 계산
•Crab에는 유클리디안 거리 알고리즘뿐만 아니라 거리를 계산할 수 있는 여러 알고리즘을 구현
•코사인 거리(cosine distance)18)
, 피어슨 상관관계(pearson correlation)19)
, 자카드 계수(jaccard
coefficient)20)
, 스피어만 계수(spearman coefficient)21)
등 알고리즘들이 구현
▲사용자들 간의 거리 계산 결과
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
17) 다차원 공간에서 두 점 간의 거리를 구하는 알고리즘
18) 두 점의 벡터 사이 각의 코사인 값으로 두 점의 벡터가 같은 방향을 가지고 있는가를 구하는 알고리즘
19) 두 변수의 선형관계 측정을 통한 상관관계 분석 알고리즘
20) 유사성계수. 두 데이터 집합의 교집합의 크기를 합집합의 크기로 나눈 것
21) 상관관계를 분석하고자 하는 두 연속형 변수의 분포가 심각하게 정규분포를 벗어나거나 또는 두 변수가 순위척도 자료
일 때 사용하는 값
euclidean_distance cosine_distances pearson_correlation jaccard_coefficient manhattan_distances spearman_coefficient
20 25 20
23 4 23
29 99 29
25 29 25
57 92 57
92 77 92
99 79 99
77 46 77
79 20 79
9 43 9
61 57 61
46 61 46
68 71 68
60 21 60
50 58 50
97 9 97
84 97 84
71 53 71
63 46 63
27 23 27
15 50 15
81 81 81
58 83 58
6 15 6
47 84 47
53 40 53
83 48 83
18 87 18
66 4 66
87 18 87
100 100 100
ABRC-3.indd 65 2017-11-02 오전 1:31:15
66.
66
•그림에서의 결과에 근거하여사용자 기반 추천 알고리즘은 자카드 계수, 맨해턴 거리와 스피어만
계수 알고리즘이 적합하지 않는다는 것을 추측할 수 있음
아이템 기반(Item_based) 추천 알고리즘
•아이템 기반 알고리즘은 item_strategies라는 라이브러리를 불러 들여 아이템끼리의 최단 거리를
계산
•아이템 기반 추천 알고리즘에도 각 거리를 계산 하는 측정법을 적용시켜서 결과를 비교
•6개 측정법 중에서 네 개의 측정법이 아이템 기반 추천 알고리즘에서 사용 가능
▲아이템들 간의 거리 계산 결과
개발 포인트
기술 주요 개발 내용
고객 맞춤형 정보
제공
•협업 필터링, 사용자 기반 추천, 아이템 기반 추천 등 데이터에 적합한
알고리즘을 사용한 추천 시스템 제공
euclidean_distance cosine_distances pearson_correlation jaccard_coefficient manhattan_distances spearman_coefficient
20.0 23.0 83.0 4.0
29.0 20.0 77.0 19.0
23.0 29.0 60.0 87.0
50.0 27.0 9.0 83.0
84.0 50.0 29.0 21.0
47.0 9.0 36.0 43.0
57.0 60.0 25.0 4.0
60.0 57.0 99.0 81.0
27.0 100.0 47.0 77.0
97.0 25.0 18.0 71.0
25.0 15.0 100.0 46.0
36.0 97.0 68.0 33.0
92.0 53.0 41.0 99.0
9.0 84.0 97.0 53.0
61.0 99.0 13.0 100.0
46.0 61.0 33.0 46.0
15.0 13.0 53.0 18.0
68.0 47.0 79.0 13.0
33.0 58.0 87.0 79.0
13.0 48.0 4.0 58.0
87.0 18.0 46.0 15.0
58.0 92.0 23.0 97.0
100.0 36.0 15.0 47.0
71.0 79.0 92.0 92.0
79.0 77.0 63.0 36.0
83.0 87.0 27.0 48.0
66.0 71.0 71.0 41.0
53.0 46.0 21.0 50.0
6.0 83.0 84.0 27.0
77.0 6.0 81.0 9.0
18.0 43.0 66.0 57.0
ABRC-3.indd 66 2017-11-02 오전 1:31:15
67.
67
기대효과 및 향후발전방안
•빅데이터를 분석, 소비자의 개인취향에 맞는 상품 추천
•SNS 사용자가 능동적으로 콘텐츠 확산에 기여할 수 있는 새로운 쇼핑환경 제시
•사용자의 취향 및 암시적 데이터를 추천서비스에 사용함으로써 타겟팅의 다양화와 질적 향상을
기대
•중소의류업체의 매출 상승과 SNS 매체의 확장성을 고려한 컨텐츠 분석 서비스 개발로 글로벌
시장을 향한 거래 플랫폼으로 성장 기회 부여
•2016년 12월 시스템 개발력을 높게 평가받아 센트럴투자파트너스, 씰컴퍼니, 비전크리에이터
로부터 7억 5천만 원 규모 투자유치
2017.03.31.일자 브릿지경제 (21면)성과 홍보
사례
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 67 2017-11-02 오전 1:31:15
68.
68
09 (주) 애드잇
골목상권활성화를 위한 업체와 고객의 매칭 플랫폼 필요
•객 유치에 어려움을 겪는 소규모 영세 자영업체와 자신이 원하는 재화와 서비스를 찾는데 어려움을
겪는 고객의 니즈를 상호 충족시킬 수 있는 서비스 틈새시장 공략
•고객이 힘들게 빈자리를 찾아 돌아다니지 않아도 조건에 맞는 상점을 추천하고 지도를 안내하는 위치
기반 실시간 자리매칭 서비스 기획
•사용자(고객)와 가맹점(상점)간의 데이터를 바탕으로 가장 적합한 업체 추천 및 쿠폰 등 사후 프로모션
만족도 극대화를 위한 부가 마케팅 서비스 추가 개발
기업의 요청사항
유휴공석과 손님을 이어주는 사용자 위치기반 O2O 서비스 다모 개발주제
기업의
사업추진
배경
대기업의 골목상권 침해로 인한 자영업 위기
•대형 유통 체인이 위치한 대로변이 아닌 한적한 뒷골목에 위치한 도소매업, 음식점업, 서비스
등의 소규모 영세 상권은 최근 거대 유통기업의 골목상권 진출로 설 자리를 잃어가고 있는 추세
•골목상권의 위축은 자영업자 개인뿐만 아니라 지역경제의 위기로 이어져 상권 양극화와 불균형을
조장하는 사회적 문제로 대두됨
•어려움을 겪고 있는 자영업자를 돕기 위한 보호 정책과 활성화 사업이 추진되고 있는 상황
지원배경_서비스 개발의 필요성
ABRC-3.indd 68 2017-11-02 오전 1:31:15
69.
69
2015.08~ 현재
지원기간
•사용자 중심의위치 기반 데이터, 가맹점 정보 관련 분류 데이터, 향후 자동추천 서비스 개발을
위한 고객 패턴 데이터(방문기록, 빈도, 예약정보, 리뷰 등), 딜 관리를 위한 통계데이터
활용 데이터 종류
센터의
지원내용
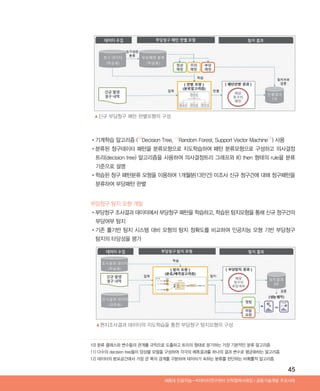
실시간 역경매 플랫폼 구축
•고객의 위치와 패턴을 기반으로 실시간 골목상권 사업체와 고객을 매칭 하는 기술 개발
•사업자가 구매조건 및 혜택을 상황에 따라 직접 제시하여 입찰하는 시스템
•인원수, 원하는 메뉴, 위치, 시간 등을 사용자가 직접 설정하면 여기에 맞춰서 사업자가 입찰
•ex) 시간별: 비오는 날, 장사 안 되는 날, 추석 명절 등
•서비스별: 쿠폰, 할인, 서비스 메뉴 등
•LBS + 실시간 정보 매칭 시스템
- 사업자의 위치뿐만 아니라 사용자의 위치가 함께 제공되며 변경이 아니라 실제도보거리 맵을
사용함으로써 사용자 편의성 제공
분석 내용 및 분석 기법
개발 모듈 기능 완성도
사용자 로그 기반
경매 시스템
딜 요청, 태그관계, 쿠폰관계,
가맹점 딜 제안 번호 생성, 제안, 상태 코드 생성
100%
경매 관리 모듈
딜 요청, 태그관계, 쿠폰관계,
가맹점 딜 제안 번호 생성, 제안, 상태 코드 생성
100%
경매 참여 모듈
딜 제안, 딜 제안 참여,
딜 제안-쿠폰 관계 테이블
100%
결과 알림 모듈
딜 완료, 푸시 API 키, 수신 계정번호 생성,
등록 계정번호 생성, 수정 계정번호 생성
90%
Deal Rules
Engine(규칙엔진)
요구 사항 및 매칭 알고리즘 적용,
경매 캠페인 수행
100%
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
ABRC-3.indd 69 2017-11-02 오전 1:31:15
70.
70
개발 모듈 기능완성도
유저 요구
DB 관리 모듈
유저 요청 데이터의 저장, 관리,
사용자 동작 로그 테이블, 태그 모듈
100%
사용자 니즈 로그
분석 모듈
사용자 동작코드, 사용자 에이전트, IP, 위치 100%
사업주 관리 모듈
사업주의 가입, 정보수정, 탈퇴 및 관련 정보 관리,
상위 카테고리 테이블, 메뉴관계테이블, 태그 모듈
100%
사업주 대응 사항
관리 모듈
사업주의 대응 데이터의 저장, 관리,
상위 카테고리 테이블, 위치정보, 메뉴
100%
위치 관계 모듈 도보맵 적용, 위치측위 분석, Geo-fencing 100%
상권 네트워크 위치측위 분석 및 Geo-fencing을 통한 network 구축 100%
태그 모듈 태그 테이블, 태그 관계테이블 100%
유저 관리 모듈 유저의 가입, 정보수정, 탈퇴 및 관련 정보 관리 테이블 100%
사업주 관리 모듈
사업주의 가입, 정보수정, 탈퇴 및 관련 정보 관리,
상위 카테고리 테이블, 메뉴관계테이블, 태그 테이블
100%
콘텐츠 매칭 모듈
사업자와 사용자 콘텐츠 DB, DB 서버,
콘텐츠 매칭 알고리즘, 매칭 정보 수신
100%
데이터 클린징 모듈 업체 및 사용자 자동 필터링 및 매칭 모듈 80%
추천 엔진 기반 모듈 검색엔진, 웹크롤러, 검색데이터저장소 80%
ABRC-3.indd 70 2017-11-02 오전 1:31:16
71.
71
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
센터의
지원 성과
최종 분석 결과 (개발 완성내용)
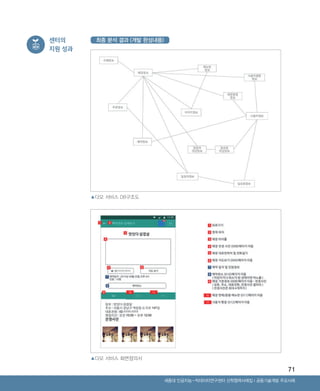
▲다모 서비스 DB구조도
▲다모 서비스 화면정의서
ABRC-3.indd 71 2017-11-02 오전 1:31:16
72.
72
▲다모 서비스 딜진행 화면
▲다모 서비스 화면(개발 완료)
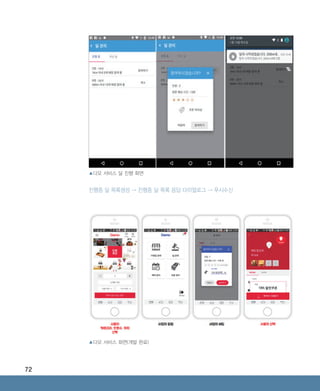
진행중 딜 목록생성 → 진행중 딜 목록 응답 다이얼로그 → 푸시수신
ABRC-3.indd 72 2017-11-02 오전 1:31:16
73.
73
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
개발 포인트
기대효과 및 향후 발전방안
•2차 장소로 이동할 때 빈자리가 있는 근거리의 가게를 실시간으로 연결해 주는 서비스
•빈자리를 찾아 다니지 않고 쉽고 간편하게 예약할 수 있음
•업소 입장에서는 빈자리를 줄여 매출을 높일 수 있음
•2차 장소로 이동할 때 빈자리가 있는 근거리의 가게를 실시간으로 연결해 주는 서비스
•빈자리를 찾아 다니지 않고 쉽고 간편하게 예약할 수 있음
•업소 입장에서는 빈자리를 줄여 매출을 높일 수 있음
•본 앱을 통해 제공되는 업소 정보, 빈자리 알림, 이용 후기 등 모든 정보에 대한 신뢰성을 높이기
위한 다각도의 노력이 필요
•O2O 서비스 앱은 기본적으로 이용자가 많아야지만 효과가 나타나기 때문에 이용 활성화를 위한
노력이 필요함
•술자리/회식 등의 모임에서는 가볍고, 손쉬운 결정을 원하기 때문에 앱 UI 구성을 쉽게 해야 함
•‘2차 모임’에만 한정하지 말고, 카테고리를 ‘1차 모임’, ‘2차 모임’으로 나눠서 서비스를 구성하는
것이 필요함
•‘다모(Damo)’ 단독 서비스가 아닌 ‘맛집 앱/소셜커머스/검색서비스’ 등과 연계해서 운용 되는
것이 더 효과적일 것으로 보임
ABRC-3.indd 73 2017-11-02 오전 1:31:16
74.
74
10 (주) 열두시
•비콘22)
상용화와함께 온라인과 오프라인을 아우르는 통합 O2O 커머스 플랫폼 활성화를 위한 데이
터 분석 방법론 개발 요청
•사용자의 서비스 이용량을 증대시키기 위해 이탈 원인과 재방문 요인을 그동안 수집한 사용자
로그 데이터를 기반으로 분석
•모바일 쿠폰의 속성에 기반 한 이탈 방지를 위해 실행할 수 있는 액션 플랜 도출
기업의 요청사항
통합 O2O 커머스 사용자 행동 로그 분석 기술 개발주제
기업의
사업추진
배경
결제, 쿠폰, 멤버십 혜택 등을 제공하는 모바일 지갑 앱 서비스 브랜드 “YAP”개발 및 서비스 제공
•모바일 및 IT기기 결제서비스가 보편화 되면서 사용자 위치를 중심으로 쿠폰, 멤버십 포인트,
결제 등 모바일 커머스와 관련 된 것을 하나로 통합한 서비스 필요성 인식
•소형화하고 간소화된 시장 기술의 변화 추세에 따라 ‘원스톱’서비스를 선호하는 소비자 경향성을
개발 단계에 반영함
지원배경_서비스 개발의 필요성
▲‘YAP’ 앱 서비스
22) beacon, 블루투스를 이용한 차세대 근거리 통신 기술
ABRC-3.indd 74 2017-11-02 오전 1:31:16
75.
75
YAP’서비스에 대한 데이터분석 활용
•기업에 필요한 마케팅 측면의 데이터 분석 및 활용 니즈 분석
•서비스의 특징 분석, 사용자 니즈 분석 진행
•사용자의 정적/동적 정보에 관해 수집하고 있는 데이터 특징 분석 및 활용
•대용량 데이터에 기반한 모델 수립 및 사용 가능한 알고리즘 개발
•사용자가 생성하는 비정형 데이터 처리 활용 기술 개발
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터 산학협력사례집
▲분석 프로세스
2014.08~2015.02
지원기간
•모바일 앱의 상황인지 서비스의 데이터 기반 마케팅 기술 개발을 위한 정형, 비정형 데이터,
사용자 식별 정보, 접속 로그
활용 데이터 종류
센터의
지원내용
분석 프로세스
전체 분석 작업은 다음과 같은 6단계를 거쳐 이루어졌으며, 특히 Business/Data Understanding에
많은 시간을 할애하여 진행
분석 내용 및 분석 기법
ABRC-3.indd 75 2017-11-02 오전 1:31:16
76.
76
서비스 페이지와 접속로그 관계 분석
•서비스의 각 메뉴별로 발생 가능한 사용자 행위 분석
•각 페이지별/메뉴별 식별자(Page_ID) 존재 유무
•사용자 식별 방법 및 접속 시간 저장 방법 분석
사용자의 의도와 행위를 파악하기 위한 접속 로그 설계
•사용자 행위별 중요도 측정
•해당 행위를 통해 사용자의 preference 추출 가능 여부 평가
•해당 로그 기록 시 서버부하 및 용량 측정
•로그 중 파일에 남겨둘 것과 DB 테이블에 저장할 항목 구분
•raw 데이터로 남겨줄 것과 한 번 이상의 계산/처리를 통해 저장될 데이터 구분
•로그를 통해 기록되는 데이터와 사용자가 직접 입력하도록 유도하는 데이터 구분
•일반 사용자가 아닌 사업자 고객의 데이터 수집 및 저장
•내부에서 수집되는 데이터와 외부에서 수집할 데이터 구분
사용자 행위 모델링
•B2C 서비스에서 사용자의 행위를 분석 및 예측하기 위한 모델링
•Experience는 사용자가 서비스를 이용하면서 겪은 감정/느낌/만족도 등임
•Action 또는 Behavior는 사용자가 서비스에 입력하는 모든 활용을 의미
•모델링을 통해 다음의 사용자 경험 과정이 이루어짐을 확인
- 서비스 이용 중 겪은 경험(원인)으로 인해 다른 행위(결과)를 유발시킴
- 서비스 이용 중 사용자의 행위가 다른 행위를 파생시킴
- 서비스 이용 중 사용자의 행위로 인해 어떤 경험을 겪게 됨
- 사용자의 경험이 또 다른 경험을 파생하는 경우는 흔하지 않음
•사용자의 경험과 행위는 서로간에 복잡하게 영향을 주는 ‘Map’의 형태로 구성될 수 있으며,
최종 목적은 목표변수에 어떤 변수가 영향을 많이 미치는가를 찾는 것임
▲사용자의 경험과 행위 분석
ABRC-3.indd 76 2017-11-02 오전 1:31:16
77.
77
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
•쿠폰의 사용량에 영향을 미치는 변수와 조건을 분석하기 위해, 쿠폰 사용횟수를 목표변수로
설정하고 Decision Tree(CHAID)를 이용해 추가 분석
•O2O 서비스 이용자의 사용자 경험 프로세스 모델링: 쿠폰 서비스의 사용자 경험은 3번의
‘부정적 행동’을 거쳐 이탈로 연결되며, 쿠폰 사용 후 만족을 느낀 경우에만 재이용으로 연결됨
•쿠폰의 속성별 이용 행태 차이 분석:편의점에서의 쿠폰 사용량이 압도적으로 많음을 확인하였으며
그 다음으로 양식, 일식, 패밀리 레스토랑에서의 사용량이 많다는 것을 파악
▲쿠폰 서비스 사용자 경험 분석
센터의
지원 성과
최종 분석 결과 (개발 완성내용)
▲쿠폰 사용 분야별 분석
ABRC-3.indd 77 2017-11-02 오전 1:31:16
78.
78
•‘카페’의 경우에는 지역에따라 차이를 보였는데, 가로수길, 강남역, 건대, 세종대 등에서 사용량이
많았으며, 부산지역과 동대문 지역에서는 사용량이 적음
•할인 혜택/지역에 따라 이용 행태 차이 분석:가로수길, 강남역, 건대, 세종대 지역에서는 ‘비율
할인’ 혜택을 주는 쿠폰이 많이 사용되었으며, 타 지역에서는 ‘1+1’혜택을 주는 쿠폰이 많이 사용
되었음을 확인
▲지역별 쿠폰 사용량 분석
Actionable Insight를 도출하기 위한 데이터 분석에는 Biz와 Data에 대한 통합적 이해가 선행
되어야 하며 이를 위해 탐색적 데이터 분석 과정이 요구됨
•탐색적 분석의 중요성
- 최초에 고객이 제시한 문제 이외에, 해당 문제의 원인이 되는 다른 문제가 발견되는 경우가 많음
- 주어진 데이터를 다양하게 가공하고 시각화 하면서, 전에는 보지 못한 ‘현상’을 보여주고
이해시키는 과정이 중요함
•Actionable Insight 제공의 필요성
- 모든 분석의 최종 목적은 고객이 실행할 수 있는 Action으로 이어져야 함을 전제로 진행함
- 분석을 시작하기 전 ‘제어’ 가능한 변수가 무엇인지 파악하고, 결론에 따라 어떤 Action이
가능한지 미리 예상하면 시행착오를 줄일 수 있음
개발 포인트
ABRC-3.indd 78 2017-11-02 오전 1:31:16
79.
79
Ⅰ공동기술개발 주요사례세종대 인공지능-빅데이터연구센터산학협력사례집
•자체적 데이터 분석 시스템 개발을 통해 020시장을 주도함으로써 B2C 웹/모바일 서비스를
운영하고 있는 많은 중소기업, 스타트업에 새로운 비즈니스 창출의 선행적 모델을 제시
•합법적으로 확보된 사용자의 동적, 정적 행위데이터를 활용한 과학적인 마케팅 정책 수립으로
마케팅 비용을 절감하고 서비스 경쟁력을 향상시킴
•데이터 기반의 맞춤형 고객 서비스로 1인 미디어 시대의 고객 경험 만족도 제고
•위치정보 인식 O2O 서비스의 장점을 활용해 앱 사용자의 프로파일을 기반으로 한맞춤형 정보
서비스 고도화로 서비스 채널 확장 및 해외 진출 가능성 부여
기대효과 및 향후 발전방안
ABRC-3.indd 79 2017-11-02 오전 1:31:16
80.
세종대학교 인공지능-빅데이터연구센터(AI-BIG DATARESEARCH CENTER)
05006 서울특별시 광진구 능동로 209 세종대학교 학술정보원 7층
TEL 02-3408-4468
abrc.or.kr
ABRC-3.indd 80 2017-11-02 오전 1:31:16










































































































![[코세나, kosena] 산업부문별 인공지능 활용제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/aiproposalguide-180803133304-thumbnail.jpg?width=640&height=640&fit=bounds)




![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)








![[2018 Bigdata win-win conference] 4](https://cdn.slidesharecdn.com/ss_thumbnails/4-181127005320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 5](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference5-181126075632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 3](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference3-181126075308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 2](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference2-181126075214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win win conference] 1](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference1-181126075052-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 온라인 고객 리뷰 빅데이터 신뢰도,방향성 분석 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/7-180918045439-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 대용량 거래데이터 분석을 위한 서버인프라 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/6-180918045307-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 머신러닝 기반 군 전력장비 수리부속/장비수요 예측시스템](https://cdn.slidesharecdn.com/ss_thumbnails/5-180918045000-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] LSTM기반 가스 배관 안전도 예측 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/4-180918044844-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 워드벡터를 활용한 관광지 리뷰 분석시스템](https://cdn.slidesharecdn.com/ss_thumbnails/3-180918044635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 데이터 전처리 기법 및 도구](https://cdn.slidesharecdn.com/ss_thumbnails/2-180918044401-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 국내 인공지능-빅데이터 산업의 문제점 및 해결방안](https://cdn.slidesharecdn.com/ss_thumbnails/1-180918043612-thumbnail.jpg?width=640&height=640&fit=bounds)




