IT의 푸른 바람– New idea, New way.
당신의 머리 속을 스치는 생각...
데이터의 대 폭발
2
Source: Intel, What Happens In An Internet Minute?
3.
IT의 푸른 바람– New idea, New way.
어떤 생각?
Q.BigData가과연이슈인가요?
여러분의의견은어떠신지요?
Q.본교육과정을수강하는이유는?
Q.데이터분석가와데이터과학자는
다른가요?같은가요?
Q.본인이기대하는미래의모습은?
Q.현장에서바라는인재의모습은?
Q.실제현장과상상or기대하는것
과의차이는?
여러분 머리 속을 스치는 생각은...
4.
IT의 푸른 바람– New idea, New way.
오늘 여러분과 나눌 이야기는 …
Big Data, Hadoop 현주소 및 전망 + 𝜶
5.
IT의 푸른 바람– New idea, New way.
Contents
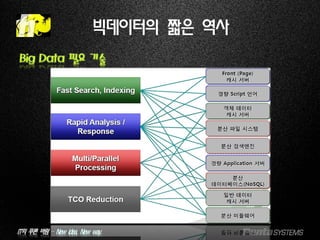
빅데이터의 짧은 역사
하둡의 더 짧은 역사
하둡2.0
마무리(사례, Q&A)
빅데이터,하둡의현주소및전망
6.
IT의 푸른 바람– New idea, New way.
들어가며 …
Google 리서치 책임자 피터 노빅(Peter Norvig)
“우리는당신들보다더훌륭한알고리즘을가지고있지않다.
단지더많은데이터를가지고있을뿐이다.”
(Wedon’thavebetteralgorithmsthanyou:wejusthavemoredata.)
구글은빅데이터창출자와빅데이터응용가유형의기업
7.
IT의 푸른 바람– New idea, New way.
Contents
빅데이터의 짧은 역사
하둡의 더 짧은 역사
하둡2.0
마무리(사례, Q&A)
빅데이터,하둡의현주소및전망
8.
IT의 푸른 바람– New idea, New way.
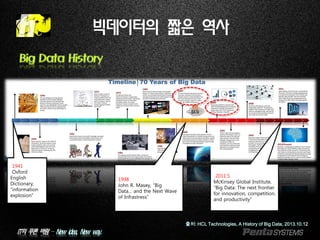
빅데이터의 짧은 역사
출처: HCL Technologies, A History of Big Data, 2013.10.12
1941
Oxford
English
Dictionary,
“information
explosion”
2011.5
McKinsey Global Institute,
“Big Data: The next frontier
for innovation, competition,
and productivity”
1998
John R. Masey, “Big
Data… and the Next Wave
of Infrastress”
Big Data History
9.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
Big Data 용어의 원조
–John R. Mashey(Chief Scientist at SGI), April 1998
출처: John R. Mashey, Big Data and the Next Wave of InfraStress,1998
10.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
Big Data 용어의 도화선
–McKinsey Global Institute, “Big
Data: The next frontier for innov-
ation, competition, and product-
ivity”보고서(2011)
• 빅데이타 속에서 누가 먼저 가치를 추
출해 내느냐에 따라 기업의 성패가 나
뉠 것이라고 언급
• 빅데이타가 새로운 유형의 기업 자산
으로 자리 잡을 것이라고 예측
출처: McKinsey Global Institute, “Big Data: The next frontier for innovation, competition, and productivity”, 2011
11.
IT의 푸른 바람– New idea, New way.
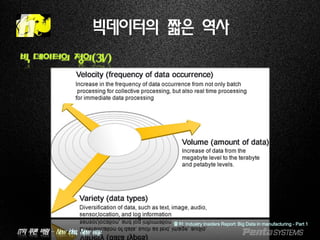
빅데이터의 짧은 역사
빅 데이터의 정의(3V)
출처: Industry Insiders Report: Big Data in manufacturing - Part 1
12.
IT의 푸른 바람– New idea, New way.
빅 데이터의 정의(4V)
빅데이터의 짧은 역사
출처: Gigaom,The Hadoop ecosystem: the (welcome) elephant in the room, 2013.5.5
13.
IT의 푸른 바람– New idea, New way.
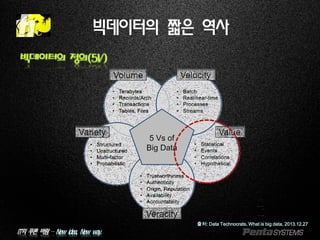
빅데이터의 짧은 역사
빅데이터의 정의(5V)
출처: Data Technocrats, What is big data, 2013.12.27
14.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
다양한 빅데이터의 정의
14
기관 빅데이터정의 시사점
McKinsey
(2011)
일반적인 데이터베이스 소프트웨어가 저장, 관리, 분
석할수있는범위를초과하는규모의데이터
데이터규모에초점(정량적측면강조)
IDC
(2011)
다양한 종류의 대규모 데이터로부터 저렴한 비용으
로가치를추출하고데이터의초고속수집,발굴,분석
을지원하도록고안된차세대기술및아키텍처
데이터 규모가 아닌 업무 수행에 초점, 특징으
로3V(Variety,Velocity,Volume)또는 4V(3V+Value
)
Wikipedia
기존데이터베이스관리도구의데이터수집ㆍ저장ㆍ
관리ㆍ분석의 역량을 넘어서는 대량의 정형 또는 비
정형데이터세트및이러한데이터로부터가치를추
출하고결과를분석하는기술
데이터규모및업무수행의관점에서통합된정
의
Gartner
기존 3V(Velocity, Volume, Variety)에 복잡성(Complexity)
추가
구조화되지않은데이터,데이터저장방식차이,
중복성 문제 등 데이터 관리 및 처리 복잡성 심
화로복잡성을특성으로추가
IBM
기존3V(Velocity,Volume,Variety)에데이터의진실성(V
eracity)추가
진실성이 확보된 데이터를 바탕으로 분석해야
한다는데이터품질측면의특성추가
최근동향
수많은정형데이터혹은비정형데이터를 수집하면,
분명한패턴이나오게되며,이를통해수집된데이터
를기반으로한예측분석
매출 증가, 비용 절감, 고객만족 증대라는 비즈
니스가치를창출할수있는패턴발견에집중
Source: 김동한, 빅 데이터의 핵심 플랫폼, 기업용 하둡 동향, 2013.2
15.
IT의 푸른 바람– New idea, New way.
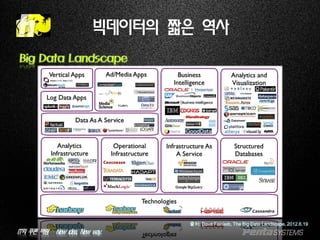
빅데이터의 짧은 역사
Big Data Landscape
출처: Dave Feinleib, The Big Data Landscape, 2012.6.19
16.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
Big Data Landscape(v2.0)
출처: Matt Turck & Shivon Zilis, The Big Data Landscape(version2.0),
17.
IT의 푸른 바람– New idea, New way.
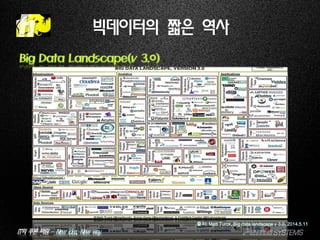
빅데이터의 짧은 역사
Big Data Landscape(v 3.0)
출처: Matt Turck, Big data landscape v 3.0, 2014.5.11
18.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
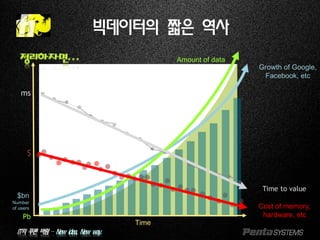
Growth of Google,
Facebook, etc
Cost of memory,
hardware, etc
Time
Pb
Amount of data
Time to value
$
$bn
Number
of users
ms
정리하자면…
19.
IT의 푸른 바람– New idea, New way.
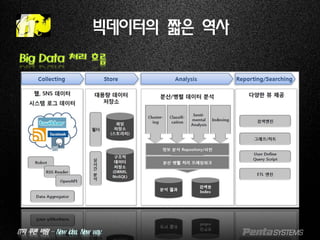
빅데이터의 짧은 역사
Big Data 처리 흐름
20.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
Big Data 처리의 어려움
21.
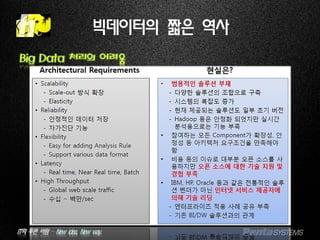
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
Big Data 요구사항
22.
IT의 푸른 바람– New idea, New way.
빅데이터의 짧은 역사
Big Data 필요 기술
23.
IT의 푸른 바람– New idea, New way.
Contents
빅데이터의 짧은 역사
하둡의 더 짧은 역사
하둡2.0
마무리(사례, Q&A)
빅데이터,하둡의현주소및전망
24.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
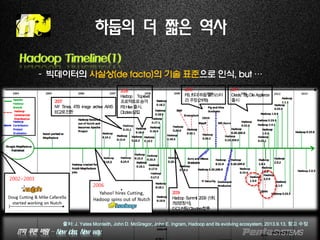
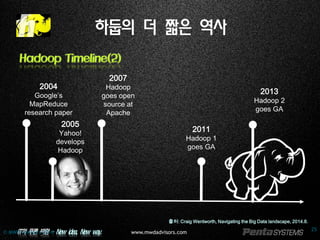
Hadoop Timeline(1)
–빅데이터의 사실상(de facto)의 기술 표준으로 인식, but …
출처: J. Yates Monteith, John D. McGregor, John E. Ingram, Hadoop and its evolving ecosystem, 2013.9.13, 참고 수정
2002~2003
2006
2008
Hadoop Top-level
프로젝트로승격
FBHive출시,
Clodera설립
2007
NY Times, 4TB image archive AWS
EC2로전환
2009
Hadoop Summit 2009 (1회,
750명참석),
더그커팅,Cloudera합류
2010
FB,최대하둡클러스터
라주장(21PB)
2011
Oracle, Big Dta Appliance
출시
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
분산 처리 기술이 왜 이슈인가?
– 클라우드컴퓨팅의확산
• 요구사항
– 공유된(Shared)인프라에서필요할때마다자원을제공받을수있는온디맨드(On
demand)형태로구성,쉽게구현할수있어야하고(Configurable),필요한시점에빠
르게 자원을 가져오는(Rapidly provisioned)것은 물론 최소한의 관리(Minimal
management)가가능한것이핵심
=인터넷기반+분산컴퓨팅환경+집중형컴퓨팅
• 클라우드인프라는비용효율적이어야한다는특성
– 일반적으로 오픈 소스 소프트웨어로 구축해 최대한 도입 비용(CAPEX)을 낮추는
것이핵심
– ‘BigData’의대두
• 빅 데이터처리기술=분석인프라+분석기술+표현기술
• 가장현실적인대안(Infrastructure)이하둡
27.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
하둡의 경쟁력은?
– 크리스토퍼비시글리아(ClouderaCSO/창업자)
• “... 데이터를 바라보는 관점에 변화가 있어야 한다. 대용량 데이터를 저장하
기 위해 10 TB의 컴퓨팅 리소스에 1천 달러를 투자하는데 정작 이를 처리하
는데32GB정도밖에사용하지않는다.이는전체인프라투자의0.3%수준...”
• 구글, 야후, 페이스북, 알리바바, 뉴욕타임즈, 폭스 등 이미 다양한 사업 분야
에서검증된기술
28.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
(참고) Hadoop 적용 확산
29.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
What is Hadoop?(1)
– Def.) A scalable fault-tolerant distributed system for data storage and processi
ng
– Itsscalability comesfromthemarriageof:
• HDFS:Self-Healing High-BandwidthClusteredStorage
• MapReduce:Fault-TolerantDistributedProcessing
– Operatesonstructuredandcomplexdata
– Alargeandactiveecosystem
• manydevelopersandadditionslikeHBase,Hive,Pig,…
– OpensourceundertheApacheLicense
출처: http://wiki.apache.org/hadoop/
30.
IT의 푸른 바람– New idea, New way.
What is Hadoop?(2)
– 아파치,오픈소스프로젝트(http://hadoop.apache.org) 중하나
• 아파치검색엔진프로젝트Nutch의서브프로젝트로시작(DougCutting,Mike
Cafarella)
– 구글클라우드플랫폼의오픈소스버전
• 구글분산파일시스템(GFS)과맵리듀스의오픈소스구현체(Java)
– 오픈소스기반의분산컴퓨팅플랫폼or오픈자바SW프레임워크
– 핵심은저장과처리(계산),가장큰특성은분산
– 야후
• 검색엔진, 데이터마이닝, 등 다양한 내부 서비스에 적용하면서 하둡의 성능
과안정성을지속적으로개선
• 현재약50,000여대서버에서사용,가장큰단일클러스터는4,000대규모
하둡의 더 짧은 역사
31.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
Hadoop의 Key Attributes
– Redundantandreliable(Scalable/Reliable)
• Doesn’tstoporloosedataevenashardwarefails
– Easytoprogram(MPP의대중화)
• Ourrocketscientistsuseitdirectly!
– Verypowerful(Efficient)
• Allowsthedevelopmentofbigdataalgorithms&tools
– Batchprocessingcentric
– Economical
32.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
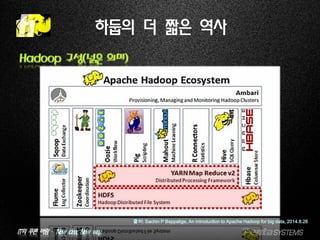
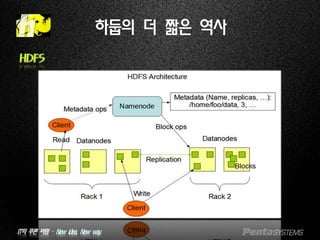
Hadoop 구성(넑은 의미)
출처: Sachin P Bappalige, An introduction to Apache Hadoop for big data, 2014.8.26
33.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
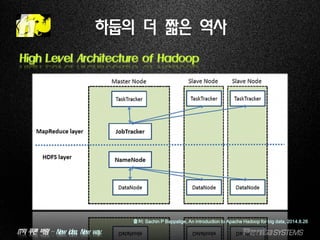
High Level Architecture of Hadoop
출처: Sachin P Bappalige, An introduction to Apache Hadoop for big data, 2014.8.26
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
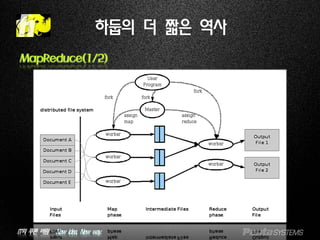
MapReduce(1/2)
36.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
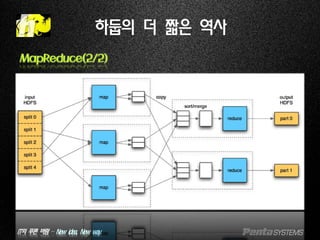
MapReduce(2/2)
37.
IT의 푸른 바람– New idea, New way.
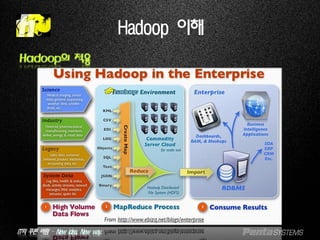
Hadoop 이해
Hadoop의 적용
38.
IT의 푸른 바람– New idea, New way.
Hadoop Positioning
– Distributions
– 3rd PartyMgmt.SW
– OperationalDatabases
– SQLonHadoop
– Frameworks/Languages
– AnalyticApplications/Platforms
– HadoopasaService(Apps./Analytics)
– HadoopasaService(Infra.)
– HadoopRepackaged
– CompetitivePlatforms
– HDFSAlternatives
하둡의 더 짧은 역사
출처: Gigaom,The Hadoop ecosystem: the (welcome) elephant in the room, 2013.5.5
39.
IT의 푸른 바람– New idea, New way.
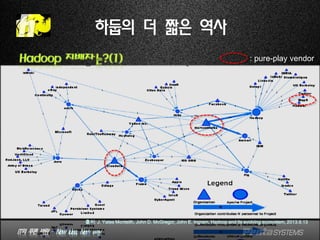
Hadoop 지배자는?(1)
하둡의 더 짧은 역사
출처: J. Yates Monteith, John D. McGregor, John E. Ingram, Hadoop and its evolving ecosystem, 2013.9.13
: pure-play vendor
40.
IT의 푸른 바람– New idea, New way.
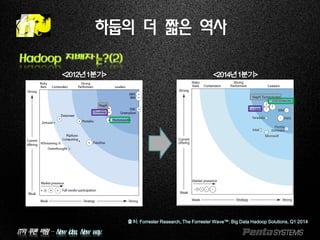
하둡의 더 짧은 역사
Hadoop 지배자는?(2)
출처: Forrester Research, The Forrester Wave™: Big Data Hadoop Solutions, Q1 2014
<2012년1분기> <2014년1분기>
41.
IT의 푸른 바람– New idea, New way.
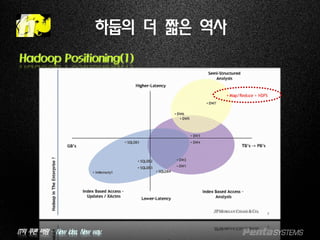
하둡의 더 짧은 역사
Hadoop Positioning(1)
42.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
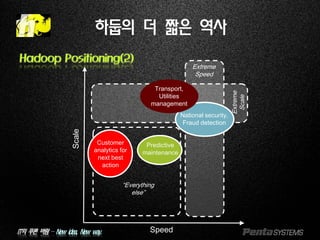
Hadoop Positioning(2)
Extreme
Scale
Extreme
Speed
“Everything
else”
National security,
Fraud detection
Transport,
Utilities
management
Customer
analytics for
next best
action
Predictive
maintenance
Speed
Scale
43.
IT의 푸른 바람– New idea, New way.
하둡의 더 짧은 역사
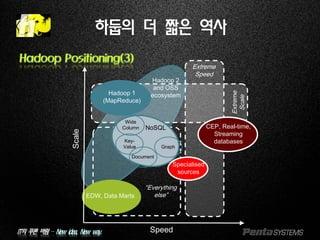
Hadoop Positioning(3)
CEP, Real-time,
Streaming
databases
Hadoop 1
(MapReduce)
EDW, Data Marts
NoSQL
Wide
Column
Key-
Value
Document
Graph
Specialised
sources
Hadoop 2
and OSS
ecosystem
Extreme
Scale
Extreme
Speed
“Everything
else”
Speed
Scale
44.
IT의 푸른 바람– New idea, New way.
Contents
빅데이터의 짧은 역사
하둡의 더 짧은 역사
하둡2.0
마무리(사례, Q&A)
빅데이터,하둡의현주소및전망
45.
IT의 푸른 바람– New idea, New way.
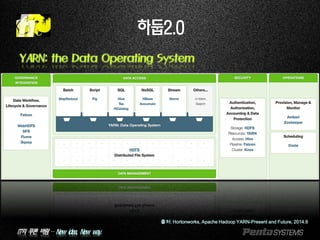
하둡2.0
YARN(Yet Another Resource Negotiator)
출처: Hortonworks, Hadoop Summit 2014, 2014.6
46.
IT의 푸른 바람– New idea, New way.
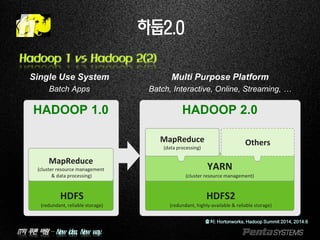
Hadoop 1 vs Hadoop 2(1)
하둡2.0
Limited up to 4,000 nodes per
cluster
O(# of tasks in a cluster)
JobTracker bottleneck -
resource management, job
scheduling and monitoring
Only has one namespace for
managing HDFS
Map and Reduce slots are static
Only job to run is MapReduce
Potentially up to 10,000 nodes per
cluster
O(cluster size)
Supports multiple namespace for
managing HDFS
Efficient cluster utilization (YARN)
MRv1 backward and forward
compatible
Any apps can integrate with
Hadoop
Beyond Java
47.
IT의 푸른 바람– New idea, New way.
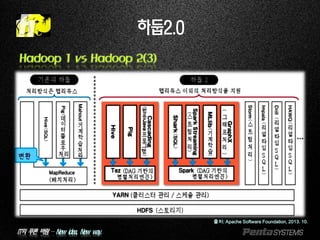
하둡2.0
Hadoop 1 vs Hadoop 2(2)
HADOOP 1.0
HDFS
(redundant, reliable storage)
MapReduce
(cluster resource management
& data processing)
HDFS2
(redundant, highly-available & reliable storage)
YARN
(cluster resource management)
MapReduce
(data processing)
Others
HADOOP 2.0
Single Use System
Batch Apps
Multi Purpose Platform
Batch, Interactive, Online, Streaming, …
출처: Hortonworks, Hadoop Summit 2014, 2014.6
48.
IT의 푸른 바람– New idea, New way.
하둡2.0
Hadoop 1 vs Hadoop 2(3)
출처: Apache Software Foundation, 2013. 10.
49.
IT의 푸른 바람– New idea, New way.
하둡2.0
YARN: the Data Operating System
출처: Hortonworks, Apache Hadoop YARN-Present and Future, 2014.6
50.
IT의 푸른 바람– New idea, New way.
Contents
빅데이터의 짧은 역사
하둡의 더 짧은 역사
하둡2.0
마무리(사례, Q&A)
빅데이터, 하둡의 현주소 및 전망
51.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
빅데이터의 자화상에 대해 표현하자면…
–“Big data is like teenage sex: everyone talks about it, nobody
really knows how to do it, everyone thinks everyone else is doing
it, so everyone claims they are doing it.”(작자 미상)
–“빅데이터의 현실은 아직 실체 없는 경험담과 성공사례 수집, 목적 없
는 기계학습 스터디 등 나침반 없는 망망대해에 있는 상황”(최대우 교
수)
–Conference, 세미나, Meetup 만 하다가 끝나겠네(김동한)
52.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
Big Data에 대한 기업의 인식(1)
52
Source: 네이버, 가우스전자, 2013.1
53.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
Big Data에 대한 기업의 인식(2)
53
Source: 네이버, 가우스전자, 2013.1
54.
IT의 푸른 바람– New idea, New way.
잘못된 사례-해외(구글 독감 예측)
빅데이터, 하둡의 현주소 및 전망
출처: Kate Crawford , Untangling algorithmic illusions from reality in big data, 2013.3
Volume,
Quality(Bias)
측면의 데이터
이슈
Timeliness
측면의 데이터
이슈
55.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
잘못된 사례-국내(6.4 지방 선거)
–11개 관심 선거구, 6개 적중
–Data의 한계, Social Data만이 빅데이터?
출처: 와이즈넛, 한국형 빅데이터 선거분석사이트 '초이스 화면, 2014.6
56.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
좋은 사례-해외(브라질 월드컵)
–SAP, ‘매치 인사이트’, 선수 움직임/유형 빅데이터로 실시간 분석
출처: http://blogs.wsj.com/cio/2014/07/10/germanys-12th-man-at-the-world-cup-big-data/
57.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
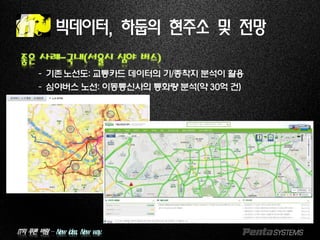
좋은 사례-국내(서율시 심야 버스)
–기존노선도: 교통카드 데이터의 기/종착지 분석이 활용
–심야버스 노선: 이동통신사의 통화량 분석(약 30억 건)
58.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
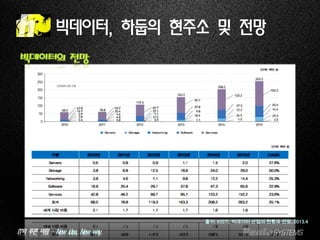
빅데이터의 전망
출처: KISTI, 빅데이터 산업의 현황과 전망, 2013.4
59.
IT의 푸른 바람– New idea, New way.
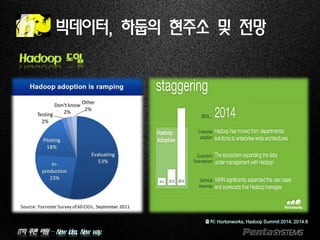
Hadoop 도입
빅데이터, 하둡의 현주소 및 전망
출처: Hortonworks, Hadoop Summit 2014, 2014.6
60.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
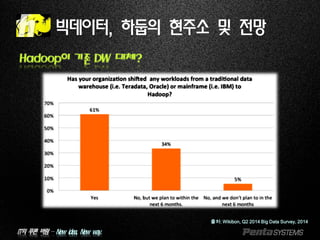
Hadoop이 기존 DW 대체?
출처: Wikibon, Q2 2014 Big Data Survey, 2014
61.
IT의 푸른 바람– New idea, New way.
빅데이터, 하둡의 현주소 및 전망
Hadoop 시장 전망(1)
출처: Wikibon, Hadoop-NoSQL Software And Services Market Forecast 2012-2017, 2013.9
62.
IT의 푸른 바람– New idea, New way.
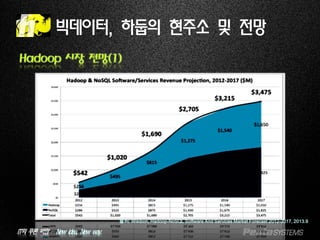
빅데이터, 하둡의 현주소 및 전망
Hadoop 시장 전망(2)
출처: Experfy Insights, Hadoop Market Size, Adoption and Growth Through 2020, 2014.6.22
63.
IT의 푸른 바람– New idea, New way.
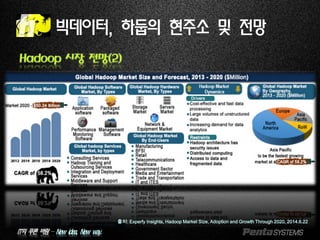
빅데이터, 하둡의 현주소 및 전망
하둡의 전망: 10 Reasons to Adopt Hadoop
1. Hadoopisrelativelyinexpensive
2. Hadoophasanactiveopensourcecommunity
3. Hadoopisbeingwidelyadoptedineveryindustry
4. Hadoopcaneasilyscaleoutasyourdatagrows
5. TraditionaltoolsareintegratingwithHadoop
6. Hadoopcanstoredatainanyformat
7. Hadoopisdesignedtoruncomplexanalytics
8. Hadoopcanprocessafulldataset
9. HardwareisbeingoptimizedforHadoop
10. Hadoopcanincreasinglyhandleflexibleworkloads
출처: By Dirk deRoos, Hadoop For Dummies, 2014.4
64.
IT의 푸른 바람– New idea, New way.
Contents
빅데이터의 짧은 역사
하둡의 더 짧은 역사
하둡2.0
마무리(사례, Q&A)
빅데이터,하둡의현주소및전망
65.
IT의 푸른 바람– New idea, New way.
마무리
오늘 이야기를 마치며 … (1)
출처: 전용준, 산업별 Big Data 사례, 이슈 및 발전 방향, 2014.8
66.
IT의 푸른 바람– New idea, New way.
마무리
오늘 이야기를 마치며 … (2)
출처: 전용준, 산업별 Big Data 사례, 이슈 및 발전 방향, 2014.8
67.
IT의 푸른 바람– New idea, New way.
오늘 이야기를 마치며 … (3)
마무리
68.
IT의 푸른 바람– New idea, New way.
오늘 이야기를 마치며 … (4): 빅 데이터 확산에 따른 도전과 기회
– 새로운 가치와 수익 창출원으로 기대를 모으고 있으나, ‘빅 브라더’에 대
한우려와전문인력부족등해결해야할많은도전과제도상존
– 데이터축적량이양적거대함을질적유용함으로전환할시기임박
– NewBM으로서Bigdata서비스발굴:BigData와플랫폼통합
– Big Data는 하나의 솔루션으로 해결할 수 없으며 요구사항, Data의 성격
등에따라다양한솔루션으로조합되어야함
– 오픈소스중심의소프트웨어스택을구축,운영이절실(기술력을갖추어
야함)
→ 빅 데이터의 핵심은 데이터의 비즈니스화(막대한 양의 1차 데이터가 아
닌가공된2차데이터가진정한의미의빅데이터)
마무리









































![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Mezzomedia] mobile 2015 상반기 분석 및 하반기 전망](https://cdn.slidesharecdn.com/ss_thumbnails/mezzomediamobile2015version1-150724062106-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





















































