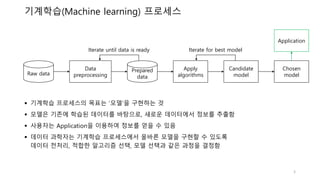
기계학습(Machine learning) 프로세스
Rawdata
Data
preprocessing
Prepared
data
Apply
algorithms
Candidate
model
Chosen
model
Application
Iterate until data is ready Iterate for best model
기계학습 프로세스의 목표는 ‘모델’을 구현하는 것
모델은 기존에 학습된 데이터를 바탕으로, 새로운 데이터에서 정보를 추출함
사용자는 Application을 이용하여 정보를 얻을 수 있음
데이터 과학자는 기계학습 프로세스에서 올바른 모델을 구현할 수 있도록
데이터 전처리, 적합한 알고리즘 선택, 모델 선택과 같은 과정을 결정함
3
4.
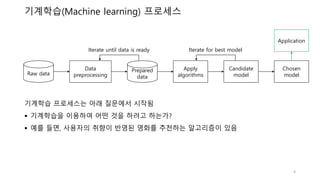
기계학습(Machine learning) 프로세스
Rawdata
Data
preprocessing
Prepared
data
Apply
algorithms
Candidate
model
Chosen
model
Application
Iterate until data is ready Iterate for best model
기계학습 프로세스는 아래 질문에서 시작됨
기계학습을 이용하여 어떤 것을 하려고 하는가?
예를 들면, 사용자의 취향이 반영된 영화를 추천하는 알고리즘이 있음
4
5.
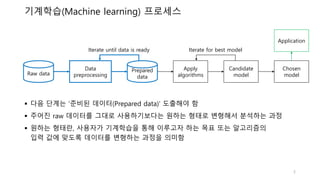
기계학습(Machine learning) 프로세스
Rawdata
Data
preprocessing
Prepared
data
Apply
algorithms
Candidate
model
Chosen
model
Application
Iterate until data is ready Iterate for best model
다음 단계는 ‘준비된 데이터(Prepared data)’ 도출해야 함
주어진 raw 데이터를 그대로 사용하기보다는 원하는 형태로 변형해서 분석하는 과정
원하는 형태란, 사용자가 기계학습을 통해 이루고자 하는 목표 또는 알고리즘의
입력 값에 맞도록 데이터를 변형하는 과정을 의미함
5
6.
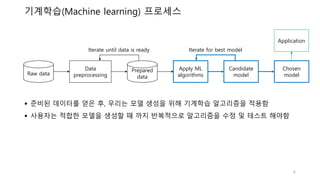
기계학습(Machine learning) 프로세스
Rawdata
Data
preprocessing
Prepared
data
Apply ML
algorithms
Candidate
model
Chosen
model
Application
Iterate until data is ready Iterate for best model
준비된 데이터를 얻은 후, 우리는 모델 생성을 위해 기계학습 알고리즘을 적용함
사용자는 적합한 모델을 생성할 때 까지 반복적으로 알고리즘을 수정 및 테스트 해야함
6
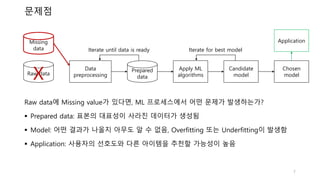
어떻게 해야 하는가?
Data
preprocessing
Prepared
data
ApplyML
algorithms
Candidate
model
Chosen
model
Application
Iterate for best model
Missing
data
Complete
data
Imputation
Missing data를 complete data로 추정할 수 있도록
적절한 imputation(대체) 모델을 이용해야 함
8
9.
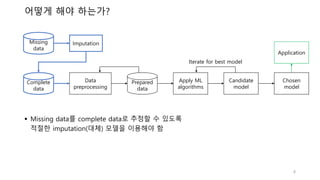
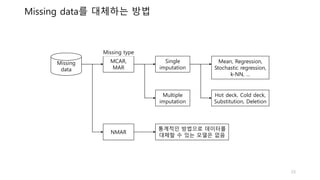
Imputation (대체)
Imputation이란,누락된 데이터를 대체 값으로 대체하는 프로세스
Missing data 특징에 따라 적합한 imputation 모델을 선택해야 함
Missing
data
Complete
data
Imputation
• Listwise deletion
• Single imputation
- Hot-deck
- Cold-deck
- Mean substation
- Interpolation
• Multiple imputation
• Model based approach
• ….
Missing data의
특징 분석
적절한 imputation
모델 선택
9
10.
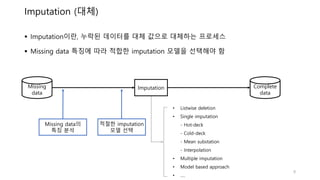
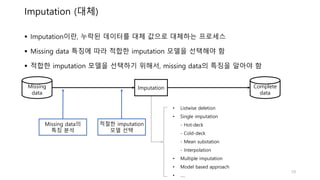
Imputation (대체)
Missing
data
Complete
data
Imputation
• Listwisedeletion
• Single imputation
- Hot-deck
- Cold-deck
- Mean substation
- Interpolation
• Multiple imputation
• Model based approach
• ….
Imputation이란, 누락된 데이터를 대체 값으로 대체하는 프로세스
Missing data 특징에 따라 적합한 imputation 모델을 선택해야 함
적합한 imputation 모델을 선택하기 위해서, missing data의 특징을 알아야 함
Missing data의
특징 분석
적절한 imputation
모델 선택
10
Missing data란?
Missingdata는 관찰된 변수에 대한 데이터 값이 저장되지 않은 경우 의미함1
누락된 데이터는 어떠한 이유로 기록되지 않고, 데이터 세트에 없는 데이터를 의미함
12
1. Graham, John W. "Missing data analysis: Making it work in the real world." Annual review of psychology 60 (2009): 549-576.
13.
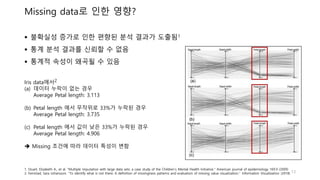
불확실성 증가로인한 편향된 분석 결과가 도출됨1
통계 분석 결과를 신뢰할 수 없음
통계적 속성이 왜곡될 수 있음
Missing data로 인한 영향?
Iris data에서2
(a) 데이터 누락이 없는 경우
Average Petal length: 3.113
(b) Petal length 에서 무작위로 33%가 누락된 경우
Average Petal length: 3.735
(c) Petal length 에서 값이 낮은 33%가 누락된 경우
Average Petal length: 4.906
Missing 조건에 따라 데이터 특성이 변함
13
1. Stuart, Elizabeth A., et al. "Multiple imputation with large data sets: a case study of the Children's Mental Health Initiative." American journal of epidemiology 169.9 (2009)
2. Fernstad, Sara Johansson. "To identify what is not there: A definition of missingness patterns and evaluation of missing value visualization." Information Visualization (2018)
14.
Summary
Missing value를처리하는 최적의 해법은 알려져 있지 않음
Missing으로 인해 정보 손실이 발생하는 경우, 손실된 데이터는 모집단의 특성을 대표하지
못하므로 분석 결과의 신뢰도와 통계적 검정력이 낮아짐
Missing value를 처리하는 방법에 따라 분석결과에 미치는 영향이 긍정적일수도, 부정적일
수도 있음
그럼에도 불구하고 Missing value로 인한 정보 손실이 분석 결과에 미치는 영향을 고려하면,
Missing value를 적절하게 처리하는 것이 중요함
그러므로 분석가는 Missing data의 특징을 분석하여 적절한 대체방법을 찾아야 함
Missing data를 imputation하기 위해 알아야 할 정보
• 데이터에서 missing이 발생한 원인
• 전체 데이터에서 missing이 차지하는 비율
• Missing type
14
15.
왜 missing이 발생하는가?
설문 조사: 응답자가 설문에 참여는 하였으나 일부 질문에 응답하지 않는 경우
임상 실험: 실험자가 실험 중간에 특별한 이유로 실험에 제외되는 경우
데이터 결합: 잘못된 결합 조건으로 데이터가 잘못 결합되는 경우
데이터 수집: 데이터 수집 조건에서 특정한 문제가 발생해서 데이터가 누락된 경우
이 외에도 데이터 누락이 발생할 수 있는 원인은 매우 다양함
15
16.
Missing type
Missingtype에 따라 missing value를 처리할 수 있는 방법이 다름
Missing type은 크게 3가지로 구분할 수 있음1
• MCAR (Missing Completely at random): 완전히 무작위로 누락
• MAR (Missing at random) 무작위 누락
• NMAR (Not missing at random): 무작위로 누락되지 않음
16
1. Little, Roderick JA, and Donald B. Rubin. Statistical analysis with missing data. Vol. 333. John Wiley & Sons, 2014.
17.
Missing type의 특징을설명하기 전에
𝑌𝑖,𝑗: i번째 환자의 j번째 관측치
𝑌𝑖,𝑜𝑏𝑠: i번째 환자의 관측된 반응 값들로 이루어진 데이터
𝑌𝑖,𝑚𝑖𝑠𝑠: i번째 환자의 관측되지 않아 missing이 발생한 데이터
임상시험에 참여하는 환자 i가 6개월동안 매월 병원을 방문하여 특정 수치를 측정하는 경우,
환자 i의 1, 2, 3월 관측치는 각각 100, 105, 110
𝑌𝑖,1 = 100, 𝑌𝑖,2 = 105, 𝑌𝑖,3 = 110 → 𝑌𝑖,𝑜𝑏𝑠 = (100,105,110)
환자 i가 4월부터 임상시험 참여를 중단하기로 한 경우, 4~6월 관측치는 missing이 발생함
𝑌𝑖,4 = 𝑁𝐴, 𝑌𝑖,5 = 𝑁𝐴, 𝑌𝑖,6 = 𝑁𝐴 → 𝑌𝑖,𝑚𝑖𝑠𝑠 = (𝑁𝐴, 𝑁𝐴, 𝑁𝐴)
𝑟𝑖:환자 i의 데이터에서 결측이 발생여부를 확인하는 기호 (1=결측, 0=관측)
𝑟𝑖 = (0,0,0,1,1,1)
17
출처: 신약개발에 필요한 의학통계학-임상시험 통계분석, 저자: 연세대학교 강승호 교수
18.
MCAR (Missing completelyat random)
𝑟𝑖가 𝑌𝑖,𝑜𝑏𝑠와 𝑌𝑖,𝑚𝑖𝑠𝑠와 독립인 경우, i번째 환자 관측 값의 missing pattern은 MCAR라고 부름
Missing이 발생한 여부가 관측 값 𝑌𝑖,𝑗에 의존하지 않는다는 뜻
예를 들어
• 1월부터 6월까지 체중 감소 임상실험에 참가하는 환자가 있음
• 환자는 1월부터 3월까지 병원에서 체중을 측정함
• 환자는 4월에 고향에 갔다 오느라 병원에서 체중을 측정하지 못함
• 그러나 환자는 5월과 6월에 병원에서 체중을 측정함
• 이와 같은 경우 4월에 발생한 missing value는 𝑌𝑖,𝑜𝑏𝑠와 𝑌𝑖,𝑚𝑖𝑠𝑠에 관계가 없기 때문에 MCAR이라고 볼 수 있음
18
출처: 신약개발에 필요한 의학통계학-임상시험 통계분석, 저자: 연세대학교 강승호 교수
19.
MAR (Missing atrandom)
𝑟𝑖가 𝑌𝑖,𝑜𝑏𝑠에 의존하나, 𝑌𝑖,𝑚𝑖𝑠𝑠에 독립적이지 않는 경우, i번째 환자 관측 값의 missing pattern은
MAR라고 부름
Missing이 발생한 여부가 관측 값 𝑌𝑖,𝑜𝑏𝑠 에만 관련이 되어 있는 경우
예를 들어
• 1월부터 6월까지 체중 감소 임상실험에 참가하는 환자가 있음
• 환자는 임상실험을 통해 체중을 줄일 수 있을 것이라 희망함
• 두 달이 지나도 체중은 감소하지 않았고, 환자는 낙담하여 3월에 병원을 방문하지 않음
• 하지만 환자는 다시 임상실험에 참여하겠다는 결심을 굳혀 나머지 기간동안 임상 실험에 참여함
• 이 경우, 3월에 발생한 missing value는 처음 두 달 동안 관측 한 값 𝑌𝑖,𝑜𝑏𝑠에는 의존하지만, 𝑌𝑖,𝑚𝑖𝑠𝑠와는 관계가
없기 때문에 MAR이라고 볼 수 있음
19
출처: 신약개발에 필요한 의학통계학-임상시험 통계분석, 저자: 연세대학교 강승호 교수
20.
MNAR (Missing notat random)
𝑟𝑖가 𝑌𝑖,𝑜𝑏𝑠과 𝑌𝑖,𝑚𝑖𝑠𝑠에 의존하는 경우, i번째 환자 관측 값의 missing pattern은 MNAR라고 부름
Missing이 발생한 여부가 관측 값 𝑌𝑖,𝑜𝑏𝑠 과 결측 값 𝑌𝑖,𝑚𝑖𝑠𝑠 모두 관련이 되어 있는 경우
예를 들어
• 1월부터 6월까지 체중 감소 임상실험에 참가하는 환자가 있음
• 1월부터 3월까지 환자의 체중은 감소함
• 4월에 환자는 병원에 방문하기 전에 집에서 체중을 측정해보니 1월에 측정한 체중으로 돌아옴
• 환자는 낙담하여 4월에 병원에 방문하지 않음
• 이 경우 4월에 발생한 missing value는 1~3월 관측한 값 𝑌𝑖,𝑜𝑏𝑠 뿐만 아니라 우리가 관측하지 못한 𝑌𝑖,𝑚𝑖𝑠𝑠에도
의존했기 때문에 MNAR이라고 볼 수 있음
20
출처: 신약개발에 필요한 의학통계학-임상시험 통계분석, 저자: 연세대학교 강승호 교수
21.
Missing type을 쉽게정리하자면
Missing type은 Missing이 발생하게 된 원인을 탐색하는 과정
Missing data의 Missing type은 3가지로 분류 할 수 있음
• MCAR(완전히 임의 누락), MAR(무작위 누락), MNAR(임의로 누락되지 않음)
Missing type는 Missing이 발생여부가 관측된 값 또는 결측된 값과 연관여부에 따라 결정
• MCAR: Missing이 발생한 여부는 관측 값, 결측 값과 관계가 없음
• MAR: Missing이 발생한 여부는 관측 값에만 관련 되어 있는 경우
• MNAR: Missing이 발생한 여부는 관측 값, 결측 값과 관계가 있는 경우
21
Missing data를 대체하는방법
MCAR,
MAR
NMAR
Missing
data
Single
imputation
Multiple
imputation
통계적인 방법으로 데이터를
대체할 수 있는 모델은 없음
Mean, Regression,
Stochastic regression,
k-NN, …
Hot deck, Cold deck,
Substitution, Deletion
Missing type
23
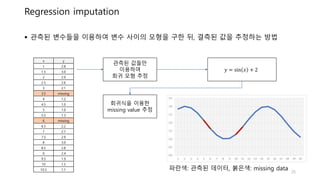
Regression imputation
관측된변수들을 이용하여 변수 사이의 모형을 구한 뒤, 결측된 값을 추정하는 방법
x y
1 2.8
1.5 3.0
2 2.9
2.5 2.6
3 2.1
3.5 missing
4 1.2
4.5 1.0
5 1.0
5.5 1.3
6 missing
6.5 2.2
7 2.7
7.5 2.9
8 3.0
8.5 2.8
9 2.4
9.5 1.9
10 1.5
10.5 1.1
관측된 값들만
이용하여
회귀 모형 추정
𝑦 = sin 𝑥 + 2
회귀식을 이용한
missing value 추정
파란색: 관측된 데이터, 붉은색: missing data 25
26.
Regression imputation –R code
26
R-code
Source: Templ, Matthias, and Peter Filzmoser. "Visualization of missing values using the R-package VIM." Reserach report cs-2008-1, Department of Statistics and
Probability Therory, Vienna University of Technology (2008).
27.
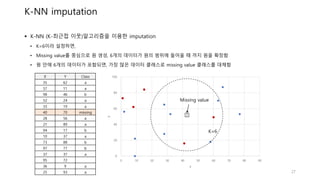
K-NN imputation
K-NN(K-최근접 이웃)알고리즘을 이용한 imputation
• K=6이라 설정하면,
• Missing value를 중심으로 원 생성, 6개의 데이터가 원의 범위에 들어올 때 까지 원을 확장함
• 원 안에 6개의 데이터가 포함되면, 가장 많은 데이터 클래스로 missing value 클래스를 대체함
X Y Class
35 62 a
57 11 a
98 46 b
52 24 a
33 19 a
40 70 missing
28 56 a
21 89 a
94 17 b
10 37 a
73 88 b
97 77 b
37 37 a
95 72
36 9 a
25 93 a
0
20
40
60
80
100
0 10 20 30 40 50 60 70 80 90
y
x
?
Missing value
K=6
27
28.
K-NN imputation –R code
28
R-code
Source: Templ, Matthias, and Peter Filzmoser. "Visualization of missing values using the R-package VIM." Reserach report cs-2008-1, Department of Statistics and
Probability Therory, Vienna University of Technology (2008).
29.
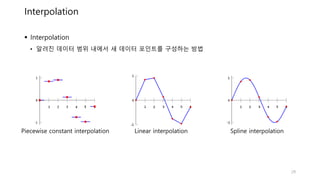
Interpolation
Interpolation
• 알려진데이터 범위 내에서 새 데이터 포인트를 구성하는 방법
Piecewise constant interpolation Linear interpolation Spline interpolation
29
30.
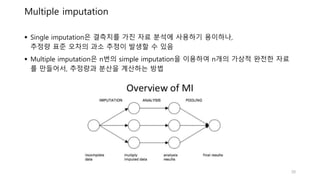
Multiple imputation
Singleimputation은 결측치를 가진 자료 분석에 사용하기 용이하나,
추정량 표준 오차의 과소 추정이 발생할 수 있음
Multiple imputation은 n번의 simple imputation을 이용하여 n개의 가상적 완전한 자료
를 만들어서, 추정량과 분산을 계산하는 방법
30
31.
Multiple imputation –R code
31
R-code
Source: Templ, Matthias, and Peter Filzmoser. "Visualization of missing values using the R-package VIM." Reserach report cs-2008-1, Department of Statistics and
Probability Therory, Vienna University of Technology (2008).
32.
Multiple imputation
1. Singleimputation 방법을 n 번 반복하여 n 개의 완전한 데이터 생성
2. n 개의 완전한 데이터에서 추정한 missing value의 값과 분산 계산
3. Rubin’s rule을 이용하여 n개의 완전한 데이터에서 missing value 값과 분산을 계산함
···
Incomplete data Complete data
누락된 값
추정한 값
변수 추정
Rubin’s rule
𝑄: 데이터셋 별로 구한 추정치
𝑇: 추정치의 표준오차
W: 대체 내 분산(within-imputation variance)
B: 대체 간 분산(Between-imputation variance)
32
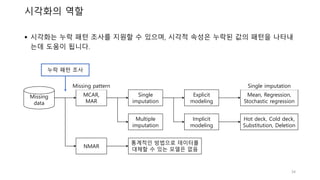
시각화는 누락패턴 조사를 지원할 수 있으며, 시각적 속성은 누락된 값의 패턴을 나타내
는데 도움이 됩니다.
시각화의 역할
MCAR,
MAR
NMAR
Missing
data
Single
imputation
Multiple
imputation
통계적인 방법으로 데이터를
대체할 수 있는 모델은 없음
Explicit
modeling
Implicit
modeling
Mean, Regression,
Stochastic regression
Hot deck, Cold deck,
Substitution, Deletion
Single imputationMissing pattern
누락 패턴 조사
34
35.
Missing pattern을 분석하는데도움되는 tool/package
Tool
• Tableau: Interactive data exploration software
R Package
• VIM: Visualization and imputation of missing values
• Amelia2: Bootstrap EM imputation
35
VIM(Visualization and imputationof missing values) package
누락된 값을 시각화 하고, imputation 모델을 적용할 수 있는 R package
주요 기능
Visualization
• Marginplot
• Matrixplot
• Histogram
Imputation model
• kNN
• Hotdeck
• Regression
37
38.
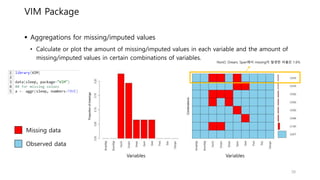
VIM Package
Aggregationsfor missing/imputed values
• Calculate or plot the amount of missing/imputed values in each variable and the amount of
missing/imputed values in certain combinations of variables.
Variables Variables
NonD, Dream, Span에서 missing이 발생한 비율은 1.6%
Missing data
Observed data
38
39.
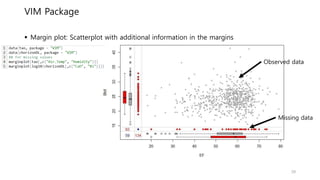
VIM Package
Marginplot: Scatterplot with additional information in the margins
Missing data
Observed data
39
40.
VIM Package
Matrixplot
• In a matrix plot, all cells of a data matrix are
visualized by rectangles.
• Available data is coded according to a
continuous color scheme.
• Missing values can easily be distinguished by
using a color such as red/orange.
40
41.
Visualization technique ofmissing data
Song, Hayeong, and Danielle Albers Szafir. "Where's My Data? Evaluating Visualizations with Missing Data." IEEE transactions on visualization and computer graphics (2018).
41
42.
관련 내용문의
• 장윤 (jangy@sejong.edu)
• 연한별 (hbyeon109@gmail.com)
42
































![[파인트리오픈클래스] 엑셀을 활용한 데이터 분석과 이해](https://cdn.slidesharecdn.com/ss_thumbnails/selection1-170223035345-thumbnail.jpg?width=640&height=640&fit=bounds)

![[도서 리뷰] 헤드 퍼스트 데이터 분석 ( Head First Data Analysis )](https://cdn.slidesharecdn.com/ss_thumbnails/headfirstdataanalysis-181125114351-thumbnail.jpg?width=640&height=640&fit=bounds)






![[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2018joeunparksweat-180820041651-thumbnail.jpg?width=640&height=640&fit=bounds)


![[팝콘 시즌1] 최보경 : 실무자를 위한 인과추론 활용 - Best Practices](https://cdn.slidesharecdn.com/ss_thumbnails/papconcausalinferencebestpractices-220221141200-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PAP] 실무자를 위한 인과추론 활용 : Best Practices](https://cdn.slidesharecdn.com/ss_thumbnails/papcon1-220218051343-thumbnail.jpg?width=640&height=640&fit=bounds)








![[2018 Bigdata win-win conference] 5](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference5-181126075632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 3](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference3-181126075308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 2](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference2-181126075214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win win conference] 1](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference1-181126075052-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 온라인 고객 리뷰 빅데이터 신뢰도,방향성 분석 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/7-180918045439-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 대용량 거래데이터 분석을 위한 서버인프라 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/6-180918045307-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 머신러닝 기반 군 전력장비 수리부속/장비수요 예측시스템](https://cdn.slidesharecdn.com/ss_thumbnails/5-180918045000-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] LSTM기반 가스 배관 안전도 예측 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/4-180918044844-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 워드벡터를 활용한 관광지 리뷰 분석시스템](https://cdn.slidesharecdn.com/ss_thumbnails/3-180918044635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 데이터 전처리 기법 및 도구](https://cdn.slidesharecdn.com/ss_thumbnails/2-180918044401-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 국내 인공지능-빅데이터 산업의 문제점 및 해결방안](https://cdn.slidesharecdn.com/ss_thumbnails/1-180918043612-thumbnail.jpg?width=640&height=640&fit=bounds)






![인공지능-빅데이터연구센터[ABRC] 산학협력사례집](https://cdn.slidesharecdn.com/ss_thumbnails/random-171113042049-thumbnail.jpg?width=640&height=640&fit=bounds)

