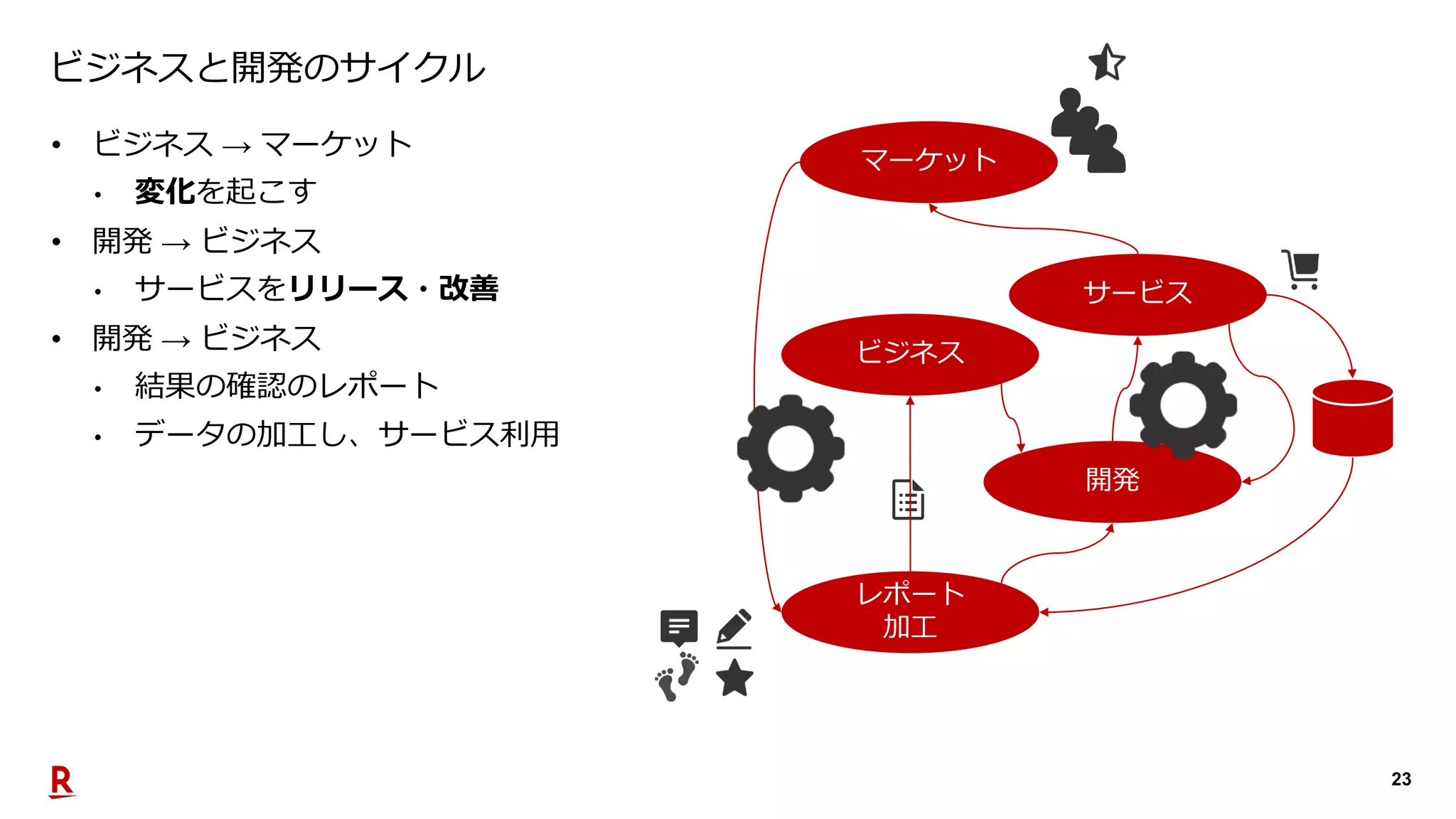
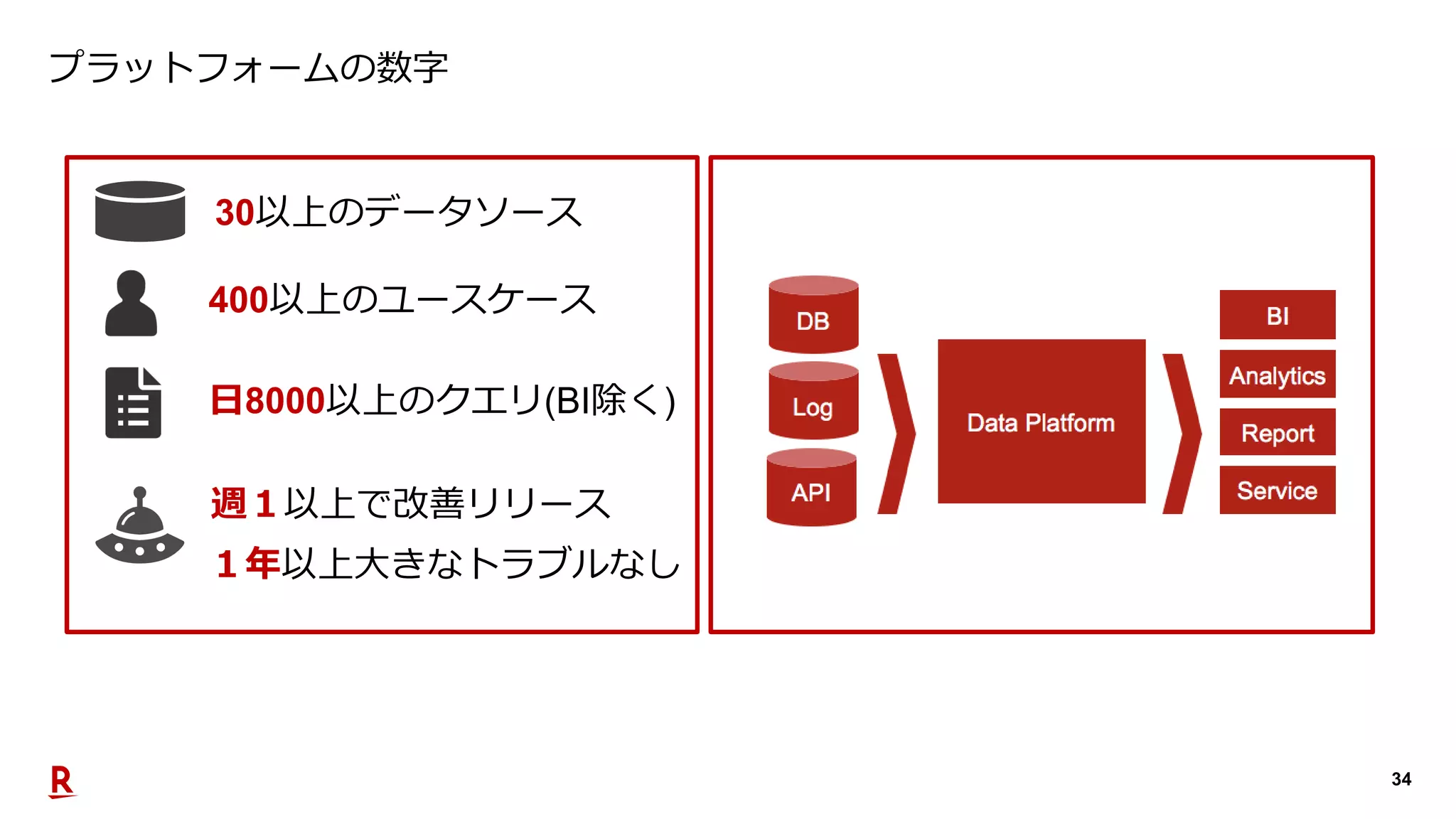
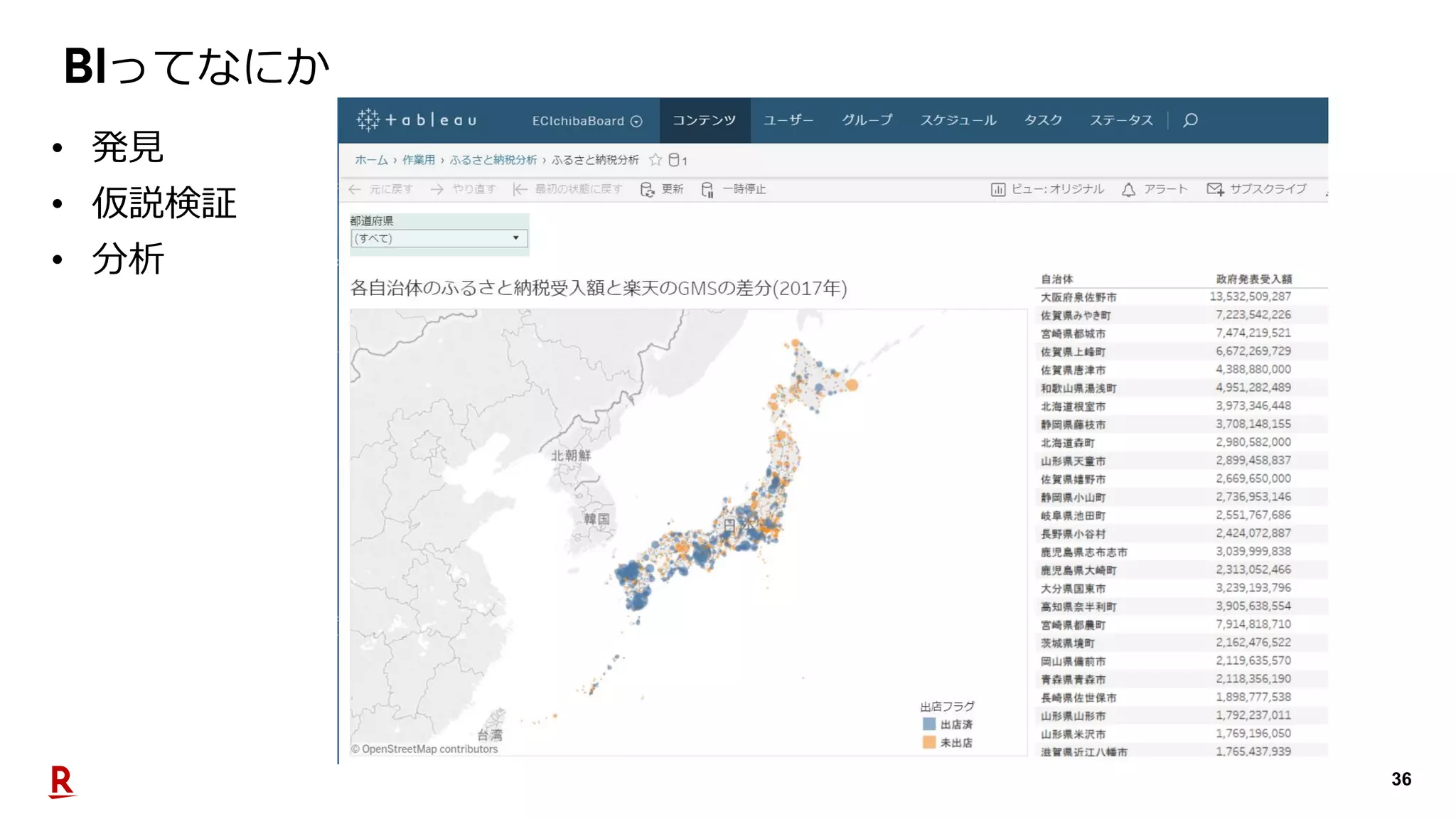
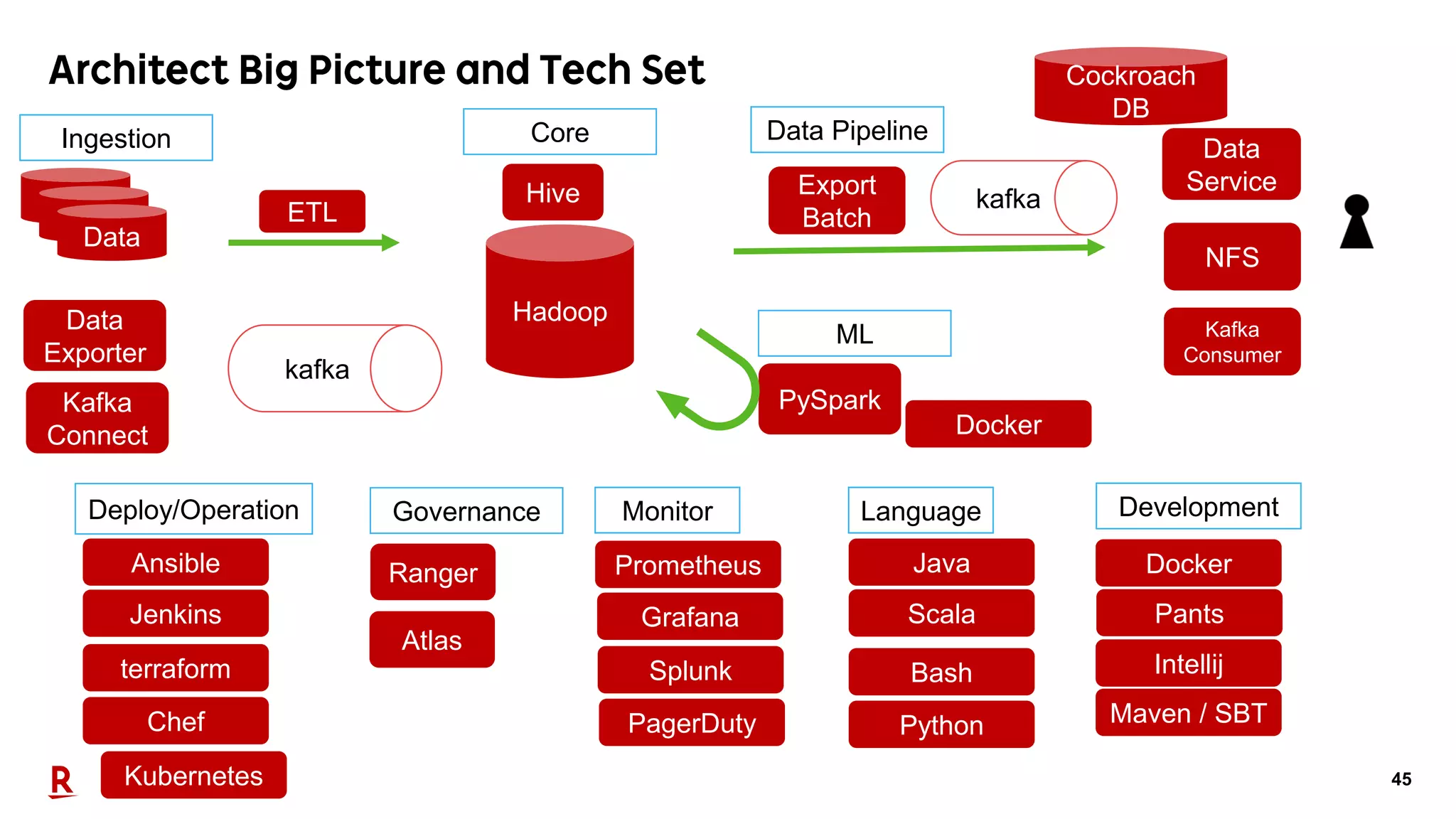
2019年10月23日、TechPlayイベント@福岡。楽天市場で利用するデータプラットフォームがユーザに価値を届けるためにどのような活動をしているのか。登壇者:渡邉 大祐(Assistant Manager, Data Utilization Team, Commerce Company)