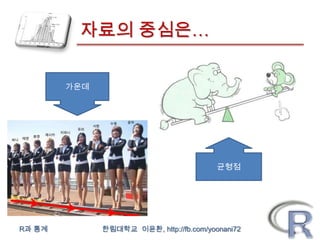
자료의 중심은…
가운데
균형점
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
5.
(산술) 평균
• 자료들의무게 중심
• 이해를 위한 헛소리.
– 각 자료들은 1만큼의 측정 비용을 갖는다.
• 가중 평균의 경우 모두 1이 아닌 측정비용을 갖는다.
– 모든 자료들의 측정값을 합한다.
• 얼마나 측정되었는지 확인
– 합해진 측정값을 총 측정비용으로 나눈다.
• 단위 측정 비용(여기서는 1)당 얼마만큼 측정될지 기대함.
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
6.
(산술) 평균 –R로 구하기
168 174 171 165 177
• 자료 입력
> h = c(168, 174, 171, 165, 177)
• 전체 지불 비용 : 자료 h의 원소의 갯수
> length(h)
[1] 5
• 전체 측정값 구하기
> sumH = sum(h)
> sumH
[1] 855
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
7.
(산술) 평균 –R로 구하기
• 전체 측정값을 지불비용의 총합으로 나누기
> sumH / length(h)
[1] 171
• R에서의 평균 함수 : mean()
> mean(h)
[1] 171
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
8.
(산술) 평균
• 앞선예제 자료를 순서대로 나열해 보자.
측정비용은 무게와 같아서 모두 1로 동일
1 1 1 1 1
165 168 171 174 177
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
9.
(산술) 평균
• 다음 변화에서 무게 중심점은 어떻게 움직일까?
1 1 1 1 1
165 168 171 175 177
1 1 1 1 1
165 168 171 174 177 … 195
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
10.
(산술) 평균
• 평균은양쪽 끝값의 변화에 민감하다.
– 보완사항 : x% 절사평균(Trimmed Mean)
• 작은 쪽과 큰 쪽을 각각 전체 자료중 (x/2)%의 자료를 제거하
고 남은 값들로 평균 측정
• 작은 쪽과 큰 쪽의 변화에 민감한 평균의 성질 보완
• 체조 점수의 예
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
중앙값
• 5개의 자료가있을 경우 그 순위만 나열해 보자.
1 2 3 4 5
중앙값보다 작은 자료의 수가 중앙값보다 큰 자료의 수가
전체 자료의 반 이상 전체 자료의 반 이상
이 두 조건을 동시에 만족하는 값
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
13.
중앙값
• 자료의 개수가짝수일 때
1st 2nd 3rd 4th
11 15 17 20
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
14.
평균과 중앙값의 관계
•다음과 같은 자료가 있다고 하자.
3
2 3 4
1 2 3 4 5
평균 : 3, 중앙값 : 3
– 자료가 좌우대칭(중심을 기준으로 작은 쪽과 큰 쪽의
개수가 서로 같은 경우)이면 평균과 중앙값이 같다.
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
15.
평균과 중앙값의 관계
•앞선 자료가 다음과 같이 변한다면?
3
1 2 3 4
1 2 3 4
중앙값은 여전히 3 (5번째 위치에 있는 값이 3)
평균은 왼쪽으로 이동할까? 오른쪽으로 이동할까?
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
16.
평균과 중앙값의 관계
•다음과 같은 자료라면?
3
2 3 4 5
2 3 4 5
중앙값은 여전히 3 (5번째 위치에 있는 값이 3)
평균은 왼쪽으로 이동할까? 오른쪽으로 이동할까?
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
17.
평균과 중앙값의 관계
•평균이 양쪽 끝값의 변화에 민감한 반면 중앙값은
민감하지 않다.
• 평균과 중앙값의 위치 만으로 대략 자료의 형태를
유추해 볼 수 있다.
– 최빈값을 같이 알면 더 수월하게 파악할 수 있다.
• 대표값
– 어떤 관찰집단의 특징을 대표한다.
– 약점 : 정보가 한 점으로 수렴한다.
• Ex) 평균이 사람 잡는다.
• 퍼진 정도를 같이 나타내어 정보의 손실을 줄인다.
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
18.
자료의 퍼진 정도
•대표값(평균 혹은 중앙값)을 중심으로 하여 얼마
나 자료들이 퍼져 있는지를 나타낸다.
• 기본적인 퍼진 정도
– 범위(range) :최대값(max) – 최소값(min)
– 편차(deviation)
• 개별 관찰값 – 평균
• 편차의 합은 0이다 ← 평균의 중요 성질
– 평균에서 사용한 자료를 이용하여 R을 통한 확인
> dev = h - mean(h)
> sum(dev)
[1] 0
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
19.
자료의 퍼진 정도- 표준편차
• 편차를 뜯어 보자.
• 다음은 앞선 평균자료에서 사용한 개별 편차이다.
> h - mean(h)
[1] -3 3 0 -6 6
– 평균의 입장에서 볼 때 -3이나 3은 모두 거리는 3만큼
떨어져 있다.
– 음수와 양수는 방향을 나타낼 뿐 평균의 입장에서는 얼
마만큼 멀리 떨어져있는지 궁금하다.
– 절대값을 취해도 되지만 계산시 고려할 점이 많으니 다
른 방법을 생각해 보자.
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
20.
자료의 퍼진 정도- 표준편차
• 각 편차들을 제곱해 보자.
> (h - mean(h)) ^ 2
[1] 9 9 0 36 36
• 자 이제 각 편차들에 대해 평균을 구해보자.
– 평균의 다른말로 기대값이라는 용어를 앞서 이야기 하였다.
– 개별 자료들이 평균에 대해 얼마만큼 떨어질지 기대하는 값을 구
해보자는 의미로 생각해 보자.
– 개별 편차 제곱들 역시 측정 비용으로 1만큼 갖고 있다고 생각하
고 편차 제곱 합을 편차들의 개수인 5로 나누자.
> sum((h - mean(h)) ^ 2) / 5
[1] 18
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72
21.
자료의 퍼진 정도- 표준편차
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72




![(산술) 평균 – R로 구하기
168 174 171 165 177
• 자료 입력
> h = c(168, 174, 171, 165, 177)
• 전체 지불 비용 : 자료 h의 원소의 갯수
> length(h)
[1] 5
• 전체 측정값 구하기
> sumH = sum(h)
> sumH
[1] 855
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-6-320.jpg)
![(산술) 평균 – R로 구하기
• 전체 측정값을 지불비용의 총합으로 나누기
> sumH / length(h)
[1] 171
• R에서의 평균 함수 : mean()
> mean(h)
[1] 171
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-7-320.jpg)










![자료의 퍼진 정도
• 대표값(평균 혹은 중앙값)을 중심으로 하여 얼마
나 자료들이 퍼져 있는지를 나타낸다.
• 기본적인 퍼진 정도
– 범위(range) :최대값(max) – 최소값(min)
– 편차(deviation)
• 개별 관찰값 – 평균
• 편차의 합은 0이다 ← 평균의 중요 성질
– 평균에서 사용한 자료를 이용하여 R을 통한 확인
> dev = h - mean(h)
> sum(dev)
[1] 0
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-18-320.jpg)
![자료의 퍼진 정도 - 표준편차
• 편차를 뜯어 보자.
• 다음은 앞선 평균자료에서 사용한 개별 편차이다.
> h - mean(h)
[1] -3 3 0 -6 6
– 평균의 입장에서 볼 때 -3이나 3은 모두 거리는 3만큼
떨어져 있다.
– 음수와 양수는 방향을 나타낼 뿐 평균의 입장에서는 얼
마만큼 멀리 떨어져있는지 궁금하다.
– 절대값을 취해도 되지만 계산시 고려할 점이 많으니 다
른 방법을 생각해 보자.
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-19-320.jpg)
![자료의 퍼진 정도 - 표준편차
• 각 편차들을 제곱해 보자.
> (h - mean(h)) ^ 2
[1] 9 9 0 36 36
• 자 이제 각 편차들에 대해 평균을 구해보자.
– 평균의 다른말로 기대값이라는 용어를 앞서 이야기 하였다.
– 개별 자료들이 평균에 대해 얼마만큼 떨어질지 기대하는 값을 구
해보자는 의미로 생각해 보자.
– 개별 편차 제곱들 역시 측정 비용으로 1만큼 갖고 있다고 생각하
고 편차 제곱 합을 편차들의 개수인 5로 나누자.
> sum((h - mean(h)) ^ 2) / 5
[1] 18
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-20-320.jpg)

![자료의 퍼진 정도 - 표준편차
> var(h)
[1] 22.5
> sd(h)
[1] 4.743416
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-22-320.jpg)

![자료의 퍼진 정도 - 사분위수범위
• R에서의 사분위수와 사분위수범위
> quantile(h)
0% 25% 50% 75% 100%
165 168 171 174 177
> IQR(h)
[1] 6
• 간략한 요약값들의 정보
> summary(h)
Min. 1st Qu. Median Mean 3rd Qu. Max.
165 168 171 171 174 177
R과 통계 한림대학교 이윤환, http://fb.com/yoonani72](https://image.slidesharecdn.com/03-120326082607-phpapp01/85/slide-24-320.jpg)


















![[오픈콘텐츠랩] 논문 "쉽게" 쓰기 전략 _ 히든:그레이스](https://cdn.slidesharecdn.com/ss_thumbnails/ppt20150807-150808034659-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)









![[오픈콘텐츠랩/Boc] 소셜 데이팅 특강 강의자료](https://cdn.slidesharecdn.com/ss_thumbnails/ppt02-150204041810-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Ankus Open Source Conference 2013] 빅데이터 분석을 위한 통계 이해와 해석](https://cdn.slidesharecdn.com/ss_thumbnails/random-131117193321-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Week6] Getting started with R](https://cdn.slidesharecdn.com/ss_thumbnails/week6rprogramming2-150203214058-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















