R 에 대한이해와 활용
2016. 01.
By HappyChallenge
email : happychallenge@outlook.com
2.
2
R 프로그램 설치및 환경 설정
o R 프로그램 설치 - 핵심 엔진 : 가장 먼저 할일
- http://mirror.bjtu.edu.cn/cran/ : 북경대 Mirror 사이트
- http://r-project.org/ : 미국 본사
o R STUDIO - 개발 환경 (IDE) 프로그램 설치 : 두번째 할일.
- https://www.rstudio.com/products/RStudio/#Desktop
3.
필요한 패키지 설치
console 창에서 아래와 같이 입력
필요한 package 를 선택하여 설치
install.packages(“dplyr”)
install.packages(“shiny”)
install.packages(“ggplot2”)
install.packages(“plotly”)
install.packages(“RODBC”)
install.packages(“lubridate”)
install.packages(“tidyr”)
install.packages(“xlsx”)
console 창
4.
Basic understanding aboutR
Open Source based S programing for statistics
Good for handling Big Data and easy to visualization
Script language, easy to learn
Compile language exe, etc
Lot of package including data handling and DB connection
More than 4,500 package developed
DB connection
Excel Control
SAS, SPSS Data Connection
Result to PPT, PDF, Word etc
동일한 기능을 하는 다양한 Package 가 있기 때문에 본인이 편리한 것
을 선택하여 사용할 수 있다.
reshape2::melt() == tidyr::gether()
reshape2::acast() == tidyr::spread()
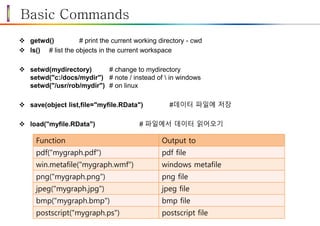
Basic Commands
getwd()# print the current working directory - cwd
ls() # list the objects in the current workspace
setwd(mydirectory) # change to mydirectory
setwd("c:/docs/mydir") # note / instead of in windows
setwd("/usr/rob/mydir") # on linux
save(object list,file="myfile.RData") #데이터 파일에 저장
load("myfile.RData") # 파일에서 데이터 읽어오기
Function Output to
pdf("mygraph.pdf") pdf file
win.metafile("mygraph.wmf") windows metafile
png("mygraph.png") png file
jpeg("mygraph.jpg") jpeg file
bmp("mygraph.bmp") bmp file
postscript("mygraph.ps") postscript file
7.
Basic of R#1
Variable
숫자로 시작하면 안된다. 문자로 시작해야 한다.
Good : var1, hflight, …
Bad : 100var, 3hf …
대소문자를 구분해야 함
Microsoft 관련 언어와 다름
Assign value to Variable
<- , = 모두 가능, 하지만 <- 사용을 권장함.
ex) var1 <- 100 #var1 에 100을 할당함, 나중에 활용하기 위함
Variable 은 사용자가 어떤 특정 값을 큰 데이터에 적용할 때 사용함
일반적으로 데이터는 수 만건에서 수 백만것에 해당
8.
Basic of R#1
Data Type
vector
Factor
matrix
Array
Data Frames
Lists
Useful Functions
length(object) # number of elements or components
str(object) # structure of an object
class(object) # class or type of an object
names(object) # names
c(object,object,...) # combine objects into a vector
cbind(object, object, ...) # combine objects as columns
rbind(object, object, ...) # combine objects as rows
object # prints the object
ls() # list current objects
rm(object) # delete an object
newobject <- edit(object) # edit copy and save as newobject
fix(object) # edit in place
9.
Basic of R#2
Vector #1
여러 개의 데이터가 들어가 있는 데이터의 나열
기호는 c (알파벳) 를 사용함
ex) c(1, 2, 3,…. 100)
ex) c(3, 4, 5)
1:10 c(c(1, 2, 3,…. 10)
Vector 의 연산
a <- c(1, 3, 5)
b <- c(2, 4, 6)
a + b c(3, 7, 11)
개수가 맞지 않을 때는 자동으로 늘어나서 해당 vector 와 연산이 됨
• a + 100 c(101, 103, 105) # c(1, 3, 5) + c(100, 100, 100) 과 동일한 결과
• b + 20 c(22, 24, 26) # c(1, 3, 5) + c(20, 20, 20) 과 동일한 결과
• a – 3 c(-2, 0, 2) # c(1, 3, 5) – c(3, 3, 3) 과 동일한 결과
a * b c(2, 12, 30)
a / b c(0.5000000, 0.7500000, 0.8333333)
기호에 대한 이해
: 결과를 말함
10.
Basic of R#3
Vector #2
Vector Indexing 필요한 순서의 숫자를 이용하여 접근 가능함.
A <- c(1, 3, 5, 7, 9)
a[3] 5, a[4] 7
a[3:5] c(5, 7, 0)
a[-3] c(1, 3, 7, 9)
a[-3:-4] c(1, 3, 9)
Factor
Vector 중 자연수 또는 Unique 한 그룹으로 묶은 것
Vector 가 단순 나열이라면 Factor 는 서로 비교할 수 있음
11.
Basic of R#4
Matrix(행렬) #1
행렬은 가로(행)와 세로(렬)의 데이터
Excel 의 데이터가 대표적
a <- matrix(c(1, 2, 3, 4, 5, 6), nrow=2, ncol=3) # 2x3 행렬
b <- matrix(c(1, 2, 3, 4, 5, 6), nrow=3, ncol=2) # 3x2 행렬
직원의 데이터를 Matrix 로 표현할 경우 행은 사람별 데이터,
열은 나이, 성별, 몸무게, 키, 근무년수,
Matrix(행렬) 의 연산
a + a, a – a, a * a, a / a, a%*%a, a*3, solve(a), t(a)
기호에 대한 이해
# : 주석을 말함 실행 안됨
12.
Basic of R#5
Matrix(행렬) #2
Matrix Indexing
a <- matrix(1:9, nrow=3, ncol=3) # 3x3 행렬
a[1, 2] 4 # 개별 값을 읽어 옴
a[2, 3] 8
a[1, ] c(1, 4, 7) # 행의 값을 모두 읽어 옴
a[ , 2] c(4, 5, 6) # 열의 값을 모두 읽어 옴
a[-3, ] # 해당 행을 제외하고 모두 읽어 옴
a[ , -2] # 해당 열을 제외하고 모두 읽어 옴
13.
Basic of R#6
Matrix(행렬) #3
Matrix and Function
sum(), mean(), sd(), min(), max(), median()…..
모든 함수는 행렬 전체 또는 행, 열별로 적용이 가능함
a <- matrix(1:9), nrow=2, ncol=3) # 3x3 행렬
sum(a) 45 # 전체 합계
mean(a) 5 # 전체 평균
median(a[ , 3]) # 3 열의 중간값
mean(a[ , 2]) # 2 열의 평균
14.
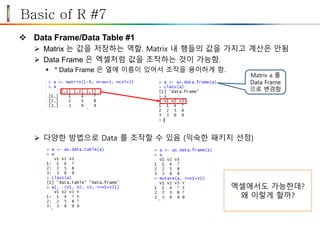
Basic of R#7
Data Frame/Data Table #1
Matrix 는 값을 저장하는 역할. Matrix 내 행들의 값을 가지고 계산은 안됨
Data Frame 은 엑셀처럼 값을 조작하는 것이 가능함.
* Data Frame 은 열에 이름이 있어서 조작을 용이하게 함.
다양한 방법으로 Data 를 조작할 수 있음 (익숙한 패키지 선정)
Matrix a 를
Data Frame
으로 변경함
엑셀에서도 가능한데?
왜 이렇게 할까?
15.
Basic of R#8 - 고난이도
비교 연산
>, <, ==, != TRUE, FALSE 값으로 저장됨
조건 / 반복
if / else if / else
for break
while
함수 만들기
함수명 <- function ( param1, param2, …. ) {
함수의 내용
}
16.
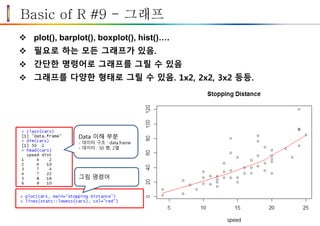
Basic of R#9 - 그래프
plot(), barplot(), boxplot(), hist()….
필요로 하는 모든 그래프가 있음.
간단한 명령어로 그래프를 그릴 수 있음
그래프를 다양한 형태로 그릴 수 있음. 1x2, 2x2, 3x2 등등.
Data 이해 부분
- 데이터 구조 : data.frame
- 데이터 : 50 행, 2열
그림 명령어
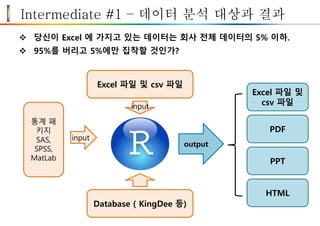
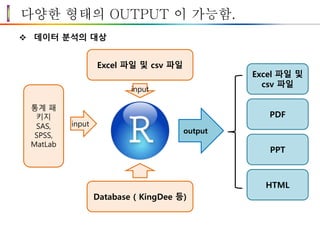
Intermediate #1 –데이터 분석 대상과 결과
당신이 Excel 에 가지고 있는 데이터는 회사 전체 데이터의 5% 이하.
95%를 버리고 5%에만 집착할 것인가?
Excel 파일 및 csv 파일
Database ( KingDee 등)
통계 패
키지
SAS,
SPSS,
MatLab
input
input
output
Excel 파일 및
csv 파일
PDF
PPT
HTML
19.
Intermediate #1 –Excel 파일
다양한 방법으로 엑셀 데이터를 읽어올 수 있음.
읽어온 결과 값은 모두 Data Frame 이 됨.
현재 Excel 파일을 읽을 수 있는 다양한 Package 가 제공되고 있음.
data <- read.csv(“book.csv”) : 가장 기초적인 방법
data <- fread(“book.csv”)
data <- read_excel(“book.xlsx”)
Excel 에서 Data 를 읽어올 뿐만 아니라 Excel에 데이터 저장도 가능
XLConnect Package
my_book <- loadWorkbook("latitude.xlsx") # Excel 파일을 읽어 Handler 사용
latitude.df <- readWorksheet(my_book, sheet=1) #첫번째 Sheet 의 데이터 읽기
다양한 조작을 해서 summary.df 을 만들어 냄.
createSheet(my_book, “data_summary”) #sheet 이름이 “data_summary”
writeWorksheet(my_book, summary.df, “data_summary”) #sheet 이름 “data_summ
ary” 에 summary.df 를 저장함.
saveWorkbook(my_book, “latitude_with_summary.xlsx”) # 파일 저장
20.
Intermediate #1 –DB에서 데이터 읽어오기
RODBC package 사용
실제 많은 데이터는 DB 에 존재함
# DB 연결
kingDee <- odbcConnect(“****", uid=“user", pwd=“password")
# SQL Query 문장 만들기
query <- "select so.FInterID, o.FItemID, o.FName, so.FDate, e.FItemID, e.FName, p.Fname, soi.FQty,
soi.FPrice, soi.FAmount
from SEOrder so, t_Organization o, SEOrderEntry soi, t_ICItemCore p, t_Base_Emp e
where so.FCustID = o.FItemID and so.FInterID = soi.FInterId
and soi.FItemID = p.FItemID and so.FEmpID = e.FItemID"
# SQL Query 실행
sale_df <- sqlQuery(kingDee, query, stringsAsFactors = FALSE)
21.
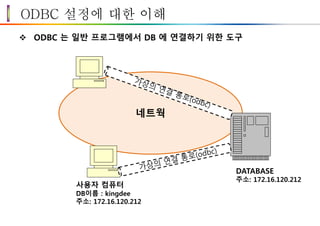
ODBC 설정에 대한이해
ODBC 는 일반 프로그램에서 DB 에 연결하기 위한 도구
네트웍
DATABASE
주소: 172.16.120.212
사용자 컴퓨터
DB이름 : kingdee
주소: 172.16.120.212
22.
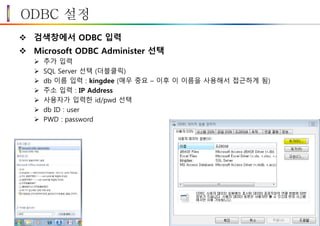
ODBC 설정
검색창에서ODBC 입력
Microsoft ODBC Administer 선택
추가 입력
SQL Server 선택 (더블클릭)
db 이름 입력 : kingdee (매우 중요 – 이후 이 이름을 사용해서 접근하게 됨)
주소 입력 : IP Address
사용자가 입력한 id/pwd 선택
db ID : user
PWD : password
23.
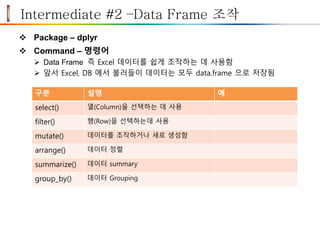
Intermediate #2 –DataFrame 조작
Package – dplyr
Command – 명령어
Data Frame 즉 Excel 데이터를 쉽게 조작하는 데 사용함
앞서 Excel, DB 에서 불러들이 데이터는 모두 data.frame 으로 저장됨
구분 설명 예
select() 열(Column)을 선택하는 데 사용
filter() 행(Row)을 선택하는데 사용
mutate() 데이터를 조작하거나 새로 생성함
arrange() 데이터 정렬
summarize() 데이터 summary
group_by() 데이터 Grouping
24.
Intermediate #2–Data Frame- 열선택
dplyr – select()
열이 많을 때, 필요한 열만 선택하는 방법
명령어 : select(df, 선택하고 싶은 열을 벡터로 표현)
열은 열의 이름을 사용해도 되고, 순서로 표현할 수 있음
hflights 의 DF 를 예로 사용함 : Package hflights 사용
select(hflights, ActualElapsedTime, AirTime, ArrDelay, DepDelay)
• select(hflights, c(10, 11, 12, 13)) == hflights[ , c(10, 11, 12, 13)]
select(hflights, Origin:Cancelled)
• select(hflights, 14:19) == hflights[ , 14:19]
select(hflights, -(DepTime:AirTime))
• select(hflights, -(5:11))
select(hflights, UniqueCarrier, ends_with("Num"), starts_with("Cancel"))
select(hflights, contains("Tim"), contains("Del"))
select(hflights, Year:ArrTime, -DayofMonth)
• hflights[c("Year","Month","DayOfWeek","DepTime","ArrTime")]
select(hflights,starts_with("T"))
• hflights[c("TailNum","TaxiIn","TaxiOut")]
25.
Intermediate #2–Data Frame- 행선택
dplyr – filter()
행이 많을 때, 필요한 행만 선택하는 방법
명령어 : filter(df, 선택하고 싶은 행을 수식으로 표현)
hflights 의 DF 를 예로 사용함 : Package hflights 사용
filter(hflights, Distance >= 3000)
filter(hflights, UniqueCarrier %in% c("JetBlue", "Southwest", "Delta"))
filter(hflights, TaxiIn + TaxiOut > AirTime)
filter(hflights, DepTime < 500 | ArrTime > 2200)
filter(hflights, DepDelay > 0, ArrDelay < 0)
filter(hflights, DayOfWeek %in% c(6,7), Cancelled == 1)
내용은 같은데 다른 표현
hflights[ hflights$Distance >= 3000, ]
hflights[ hflights$UniqueCarrier %in% c(c("JetBlue", "Southwest", "Delta"), ]
26.
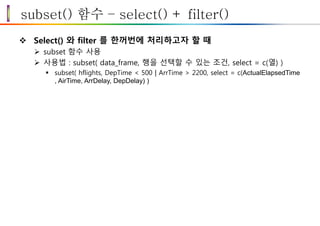
subset() 함수 –select() + filter()
Select() 와 filter 를 한꺼번에 처리하고자 할 때
subset 함수 사용
사용법 : subset( data_frame, 행을 선택할 수 있는 조건, select = c(열) )
subset( hflights, DepTime < 500 | ArrTime > 2200, select = c(ActualElapsedTime
, AirTime, ArrDelay, DepDelay) )
27.
Intermediate #2–Data Frame– 데이터조작
dplyr – mutate()
값들을 조작하여 새로운 데이터 또는 기존 데이터를 변경함
새로운 데이터를 만들어 낼 수 있음
hflights 의 DF 를 예로 사용함 : Package hflights 사용
mutate( hflights, ActualGroundTime = ActualElapsedTime - AirTime)
mutate( hflights, GroundTime = TaxiIn + TaxiOut)
mutate( hflights, AverageSpeed = Distance / AirTime * 60)
mutate( hflights, loss = ArrDelay - DepDelay, loss_percent = (ArrDelay - DepDelay)
/ DepDelay * 100)
transform() == mutate() 같음
transform( hflights, ActualGroundTime = ActualElapsedTime - AirTime)
transform( hflights, GroundTime = TaxiIn + TaxiOut)
transform( hflights, AverageSpeed = Distance / AirTime * 60)
같은 효과
hflights$ActualGroundTime = hflights$ActualElapsedTime – hflights$AirTime
28.
Intermediate #2–Data Frame– Sorting
dplyr – arrange()
행을 어떤 조건 값에 의해 오름차순, 또는 내림차순으로 정리
hflights 의 DF 를 예로 사용함 : Package hflights 사용
arrange( hflights, DepDelay) – 오름차순
• arrange( hflights, desc(DepDelay) ) – 내림차순
arrange( hflights, ActualGroundTime) – 오름차순
• arrange( hflights, desc(ActualGroundTime)) – 오름차순
arrange( hflights, CancellationCode)
arrange( hflights, UniqueCarrier, DepDelay) – 두개 항의 조합
arrange( hflights, UniqueCarrier, desc(DepDelay))
응용
arrange(filter( hflights, Dest == "DFW", DepTime < 800),desc(AirTime)
다른 표현 방법
hflights[ order( hflights$DepDelay ), ] == arrange( hflights, DepDelay )
hflights[ order( -hflights$DepDelay ), ] == arrange( hflights, desc(DepDelay) )
29.
Intermediate #2–Data Frame–summarize
dplyr – summarize()
행을 어떤 조건 값에 의해 오름차순, 또는 내림차순으로 정리
hflights 의 DF 를 예로 사용함 : Package hflights 사용
summarise(hflights, min_dist = min(Distance), max_dist = max(Distance))
summarise(hflights,
earliest = min(ArrDelay),
average = mean(ArrDelay),
latest = max(ArrDelay),
sd = sd(ArrDelay))
summarise(hflights, n_obs = n(),
n_carrier = n_distinct(UniqueCarrier),
n_dest = n_distinct(Dest),
dest100 = nth(Dest, 100))
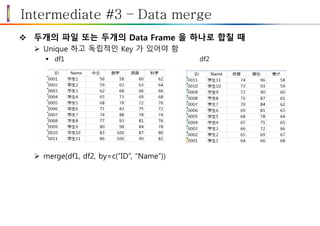
Intermediate #3 –Data merge
두개의 파일 또는 두개의 Data Frame 을 하나로 합칠 때
Unique 하고 독립적인 Key 가 있어야 함
df1 df2
merge(df1, df2, by=c(“ID”, “Name”))
33.
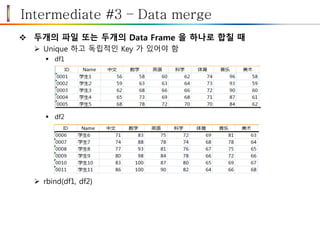
Intermediate #3 –Data merge
두개의 파일 또는 두개의 Data Frame 을 하나로 합칠 때
Unique 하고 독립적인 Key 가 있어야 함
df1
df2
rbind(df1, df2)
34.
Intermediate #3 –Data Reshape
melt()– 여러 개의 행을 한 개 행으로 통합
shape2 package 사용
활용 : melt(data, key, value, …, na.rm = FALSE, convert = FALSE)
예
melt ( iris, id = c(“Species”) )
melt() 함수 적용 전 melt() 함수 적용 후
35.
Intermediate #3 –Data Reshape
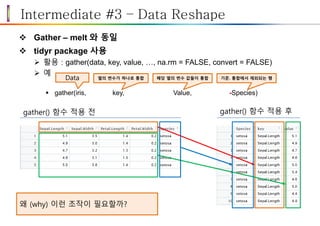
Gather – melt 와 동일
tidyr package 사용
활용 : gather(data, key, value, …, na.rm = FALSE, convert = FALSE)
예
gather(iris, key, Value, -Species)
Data 열의 변수가 하나로 통합 해당 열의 변수 값들이 통합 기준. 통합에서 제외되는 행
gather() 함수 적용 전 gather() 함수 적용 후
왜 (why) 이런 조작이 필요할까?
36.
Intermediate #3 –Data Reshape
dcast() – 하나의 변수를 여러개로 분리 할 때, 즉 key-value pair 를 여
러 개의 열(Column)으로 구분할 때
reshape2 package 사용
활용 : spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
예
dcast(data, Species + group + Part ~ Measure, value.var="value")
Data 분리되는 변수(열) 분리되는 값
dcast() 함수 적용 전 dcast() 함수 적용 후
37.
Intermediate #3 –Data Reshape
spread() == dcast() 와 동일함
tidyr package 사용
활용 : spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
예
spread(data, Measure, value)
Data 분리되는 변수(열) 분리되는 값
spread() 함수 적용 전 spread() 함수 적용 후
38.
Intermediate #3 –Data Reshape
separate() – 하나의 변수를 두개로 분리
tidyr package 사용
활용 : separate(data, col, into, sep = "[^[:alnum:]]+", remove = TRUE, convert
= FALSE, extra = "warn", fill = "warn", ...)
예
separate(data, key, c("Part", "Measure"), ".")
Data 분리되는 변수(열) 분리되는 변수 명 분리 기준 (.)
separate() 함수 적용 전 separate() 함수 적용 후
39.
Intermediate #3 –Data 분리 및 통합
Command Chainning 과 Data 분리 및 통합의 이유
iris.tidy <- iris %>%
gather(key, Value, -Species) %>%
separate(key, c("Part", "Measure"), ".")
iris.wide <- iris %>%
gather(key, value, -Species) %>%
separate(key, c("Part", "Measure"), ".") %>%
spread(Measure, value)
ggplot(iris.tidy, aes(x = Species, y = Value, col = P
art)) + geom_jitter() + facet_grid(. ~Measure)
ggplot(iris.wide, aes(x = Length, y = Width, col = Part))
+ geom_jitter() + facet_grid(. ~Species)
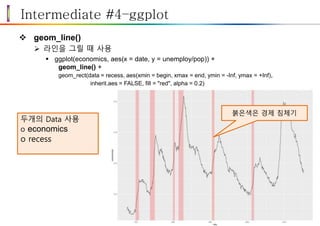
Intermediate #4–ggplot
ggplot은 여러 가지(plot, plotly, ggivs 등)그래픽 package 중에 하나.
자주 사용하는 이유는 확장성이 좋고, 데이터를 다루는 철학 때문
계층적 구조의 철학
Theme
Coordinates
Statistics
Facets
Geometrics
Aesthetics
Data
Theme
Coordinates
통계적 방법
그룹핑등의 구분
표현의 방법
표현할 데이터 선정
Data Frame 를 의미함
Intermediate #4–ggplot
Geometrics의 표현 종류 및 방법
geom_point()
geom_bar()
geom_boxplot()
geom_histogram()
geom_smooth()
…. 기타 30 여가지 기능
44.
Intermediate #4–ggplot
Parameter에 대한 이해
x : x 좌표, aesthetics 의 대상 이외에 다른 데이터를 표현할 때 사용
y : y 좌표, aesthetics 의 대상 이외에 다른 데이터를 표현할 때 사용
col : 점의 외곽을 표현하는 색을 표현함
fill : 점을 채우는 색
shape : point를 어떤 형태로 나타낼 지 결정, 25가지 방법
size : 크기를 나타냄
alpha : 투명도를 나타냄
해당 Parameter 값을 두가지 방법을 통해서 가능함
대상 : col, fill, size, alpha, shape(반드시 discrete/categorical 변수 (자연수)여야 함)
첫째 방법 : 사용자가 강제로 정해 주는 방법
col = “red”, col = “#ffeeaa”, fill = “red”, shape = 3, size = 5
두번째 방법 : Data 값을 활용하는 방법
col = cyl, size = cyl …..
45.
Intermediate #4–ggplot
geom_point()– 특징, 반드시 x, y 가 모두 필요함
Parameter : x, y, alpha, col, fill, shape, size
graph <- ggplot(mtcars, aes( x=wt, y=mpg )) #Data, Aesthetic 은 Fixed 됨
활용 사례
graph + geom_point( aes(col = qsec))
graph + geom_point( aes(alpha = qsec, col = factor(cyl), shape = factor(cyl), size =
cyl))
46.
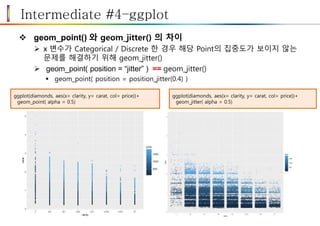
Intermediate #4–ggplot
geom_point()와 geom_jitter() 의 차이
x 변수가 Categorical / Discrete 한 경우 해당 Point의 집중도가 보이지 않는
문제를 해결하기 위해 geom_jitter()
geom_point( position = “jitter” ) == geom_jitter()
geom_point( position = position_jitter(0.4) )
ggplot(diamonds, aes(x= clarity, y= carat, col= price))+
geom_point( alpha = 0.5)
ggplot(diamonds, aes(x= clarity, y= carat, col= price))+
geom_jitter( alpha = 0.5)
47.
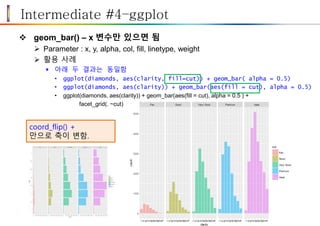
Intermediate #4–ggplot
geom_bar()– x 변수만 있으면 됨
Parameter : x, y, alpha, col, fill, linetype, weight
활용 사례
아래 두 결과는 동일함
• ggplot(diamonds, aes(clarity, fill=cut)) + geom_bar( alpha = 0.5)
• ggplot(diamonds, aes(clarity)) + geom_bar(aes(fill = cut), alpha = 0.5)
• ggplot(diamonds, aes(clarity)) + geom_bar(aes(fill = cut), alpha = 0.5 ) +
facet_grid(. ~cut)
coord_flip() +
만으로 축이 변함.
48.
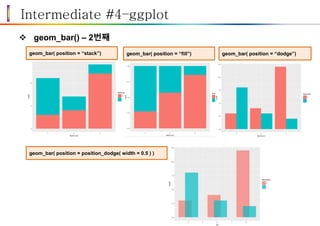
Intermediate #4–ggplot
geom_bar()– 2번째
geom_bar( position = “stack”) geom_bar( position = “fill”) geom_bar( position = “dodge”)
geom_bar( position = position_dodge( width = 0.5 ) )
49.
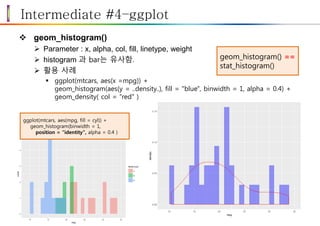
Intermediate #4–ggplot
geom_boxplot()
Parameter : lower, middle, upper, x, ymax, ymin, alpha, colour, fill, linetype, s
hape, size, weight
활용 사례
ggplot(mtcars, aes(factor(cyl), mpg)) +
geom_boxplot(aes(fill = factor(cyl))) +
geom_jitter() +
coord_flip()
jitter() 는 point() 의 변형으
로 한곳에 점이 몰리지 않게
분산 시켜 줌








![Basic of R #3
Vector #2
Vector Indexing 필요한 순서의 숫자를 이용하여 접근 가능함.
A <- c(1, 3, 5, 7, 9)
a[3] 5, a[4] 7
a[3:5] c(5, 7, 0)
a[-3] c(1, 3, 7, 9)
a[-3:-4] c(1, 3, 9)
Factor
Vector 중 자연수 또는 Unique 한 그룹으로 묶은 것
Vector 가 단순 나열이라면 Factor 는 서로 비교할 수 있음](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-10-320.jpg)

![Basic of R #5
Matrix(행렬) #2
Matrix Indexing
a <- matrix(1:9, nrow=3, ncol=3) # 3x3 행렬
a[1, 2] 4 # 개별 값을 읽어 옴
a[2, 3] 8
a[1, ] c(1, 4, 7) # 행의 값을 모두 읽어 옴
a[ , 2] c(4, 5, 6) # 열의 값을 모두 읽어 옴
a[-3, ] # 해당 행을 제외하고 모두 읽어 옴
a[ , -2] # 해당 열을 제외하고 모두 읽어 옴](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-12-320.jpg)
![Basic of R #6
Matrix(행렬) #3
Matrix and Function
sum(), mean(), sd(), min(), max(), median()…..
모든 함수는 행렬 전체 또는 행, 열별로 적용이 가능함
a <- matrix(1:9), nrow=2, ncol=3) # 3x3 행렬
sum(a) 45 # 전체 합계
mean(a) 5 # 전체 평균
median(a[ , 3]) # 3 열의 중간값
mean(a[ , 2]) # 2 열의 평균](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-13-320.jpg)




![Intermediate #2–Data Frame - 열선택
dplyr – select()
열이 많을 때, 필요한 열만 선택하는 방법
명령어 : select(df, 선택하고 싶은 열을 벡터로 표현)
열은 열의 이름을 사용해도 되고, 순서로 표현할 수 있음
hflights 의 DF 를 예로 사용함 : Package hflights 사용
select(hflights, ActualElapsedTime, AirTime, ArrDelay, DepDelay)
• select(hflights, c(10, 11, 12, 13)) == hflights[ , c(10, 11, 12, 13)]
select(hflights, Origin:Cancelled)
• select(hflights, 14:19) == hflights[ , 14:19]
select(hflights, -(DepTime:AirTime))
• select(hflights, -(5:11))
select(hflights, UniqueCarrier, ends_with("Num"), starts_with("Cancel"))
select(hflights, contains("Tim"), contains("Del"))
select(hflights, Year:ArrTime, -DayofMonth)
• hflights[c("Year","Month","DayOfWeek","DepTime","ArrTime")]
select(hflights,starts_with("T"))
• hflights[c("TailNum","TaxiIn","TaxiOut")]](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-24-320.jpg)
![Intermediate #2–Data Frame - 행선택
dplyr – filter()
행이 많을 때, 필요한 행만 선택하는 방법
명령어 : filter(df, 선택하고 싶은 행을 수식으로 표현)
hflights 의 DF 를 예로 사용함 : Package hflights 사용
filter(hflights, Distance >= 3000)
filter(hflights, UniqueCarrier %in% c("JetBlue", "Southwest", "Delta"))
filter(hflights, TaxiIn + TaxiOut > AirTime)
filter(hflights, DepTime < 500 | ArrTime > 2200)
filter(hflights, DepDelay > 0, ArrDelay < 0)
filter(hflights, DayOfWeek %in% c(6,7), Cancelled == 1)
내용은 같은데 다른 표현
hflights[ hflights$Distance >= 3000, ]
hflights[ hflights$UniqueCarrier %in% c(c("JetBlue", "Southwest", "Delta"), ]](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-25-320.jpg)

![Intermediate #2–Data Frame – Sorting
dplyr – arrange()
행을 어떤 조건 값에 의해 오름차순, 또는 내림차순으로 정리
hflights 의 DF 를 예로 사용함 : Package hflights 사용
arrange( hflights, DepDelay) – 오름차순
• arrange( hflights, desc(DepDelay) ) – 내림차순
arrange( hflights, ActualGroundTime) – 오름차순
• arrange( hflights, desc(ActualGroundTime)) – 오름차순
arrange( hflights, CancellationCode)
arrange( hflights, UniqueCarrier, DepDelay) – 두개 항의 조합
arrange( hflights, UniqueCarrier, desc(DepDelay))
응용
arrange(filter( hflights, Dest == "DFW", DepTime < 800),desc(AirTime)
다른 표현 방법
hflights[ order( hflights$DepDelay ), ] == arrange( hflights, DepDelay )
hflights[ order( -hflights$DepDelay ), ] == arrange( hflights, desc(DepDelay) )](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-28-320.jpg)






![Intermediate #3 – Data Reshape
separate() – 하나의 변수를 두개로 분리
tidyr package 사용
활용 : separate(data, col, into, sep = "[^[:alnum:]]+", remove = TRUE, convert
= FALSE, extra = "warn", fill = "warn", ...)
예
separate(data, key, c("Part", "Measure"), ".")
Data 분리되는 변수(열) 분리되는 변수 명 분리 기준 (.)
separate() 함수 적용 전 separate() 함수 적용 후](https://image.slidesharecdn.com/rv1-160115094530/85/R-v1-1-38-320.jpg)













![[Bài giảng, chi dưới] mong dui 2013](https://cdn.slidesharecdn.com/ss_thumbnails/bigingchidimongdui2013-140417204207-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[Week5] Getting started with R](https://cdn.slidesharecdn.com/ss_thumbnails/week5rprogrammingpdf-150130233806-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
















