Downloaded 34 times

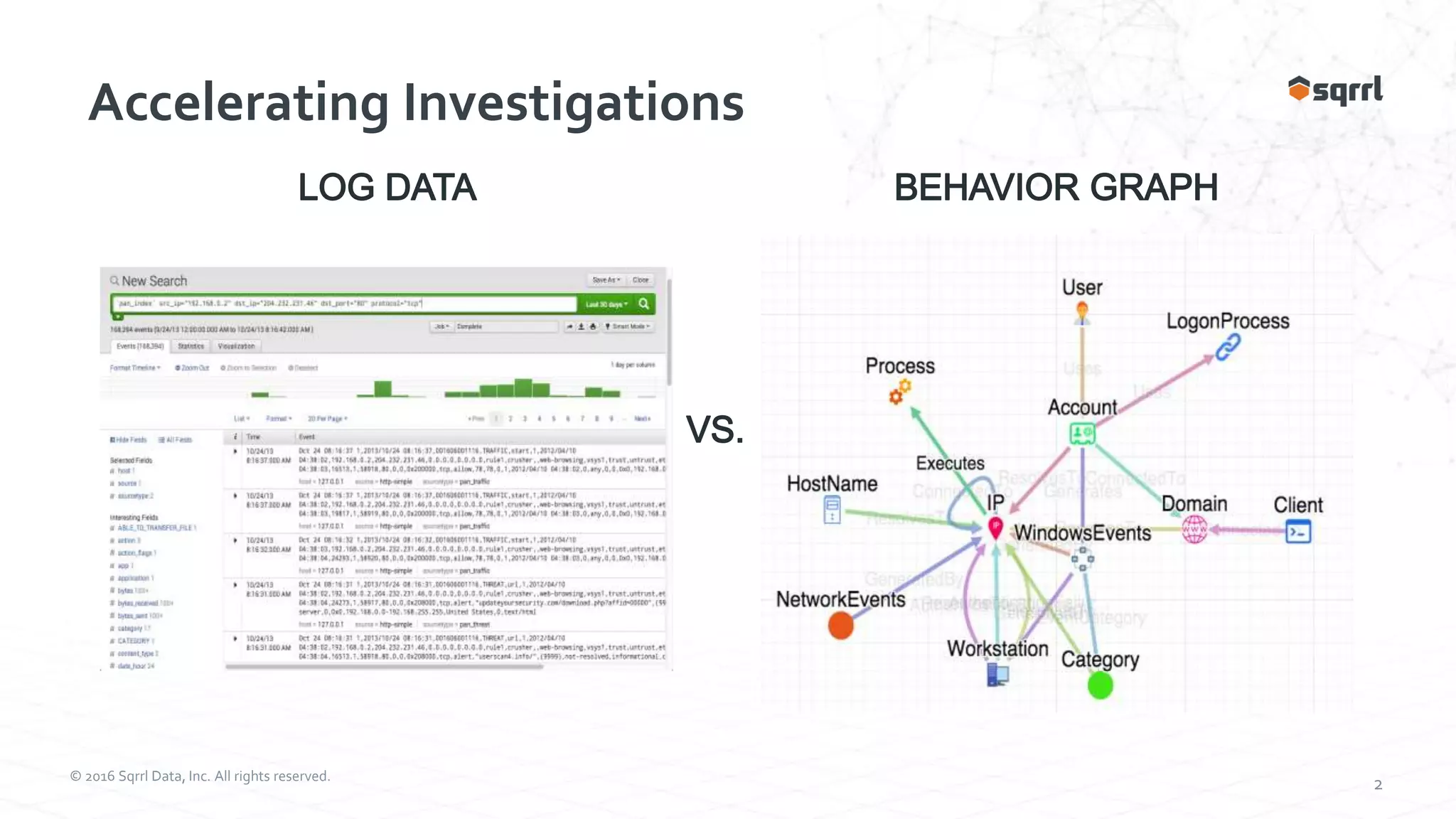

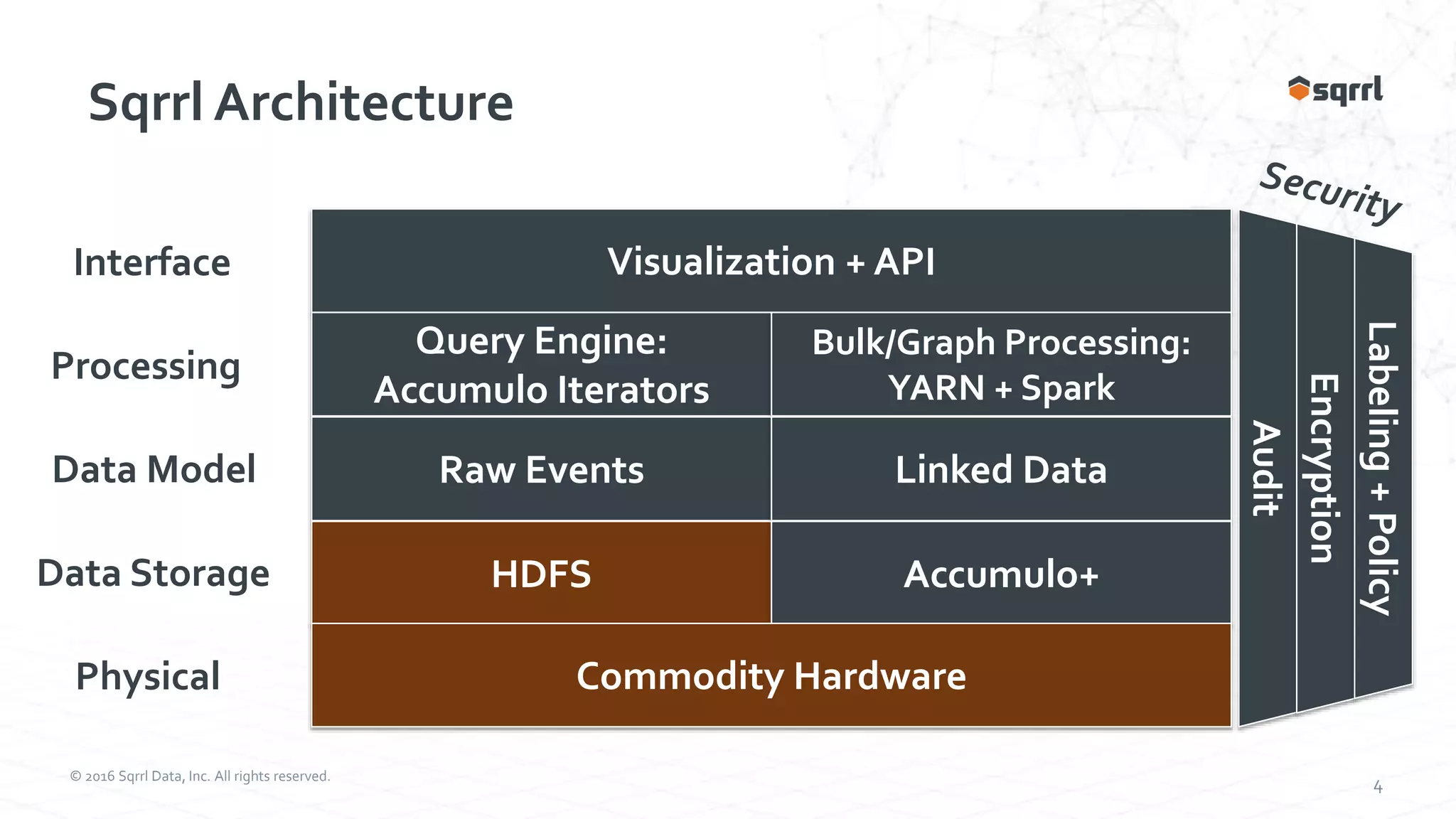



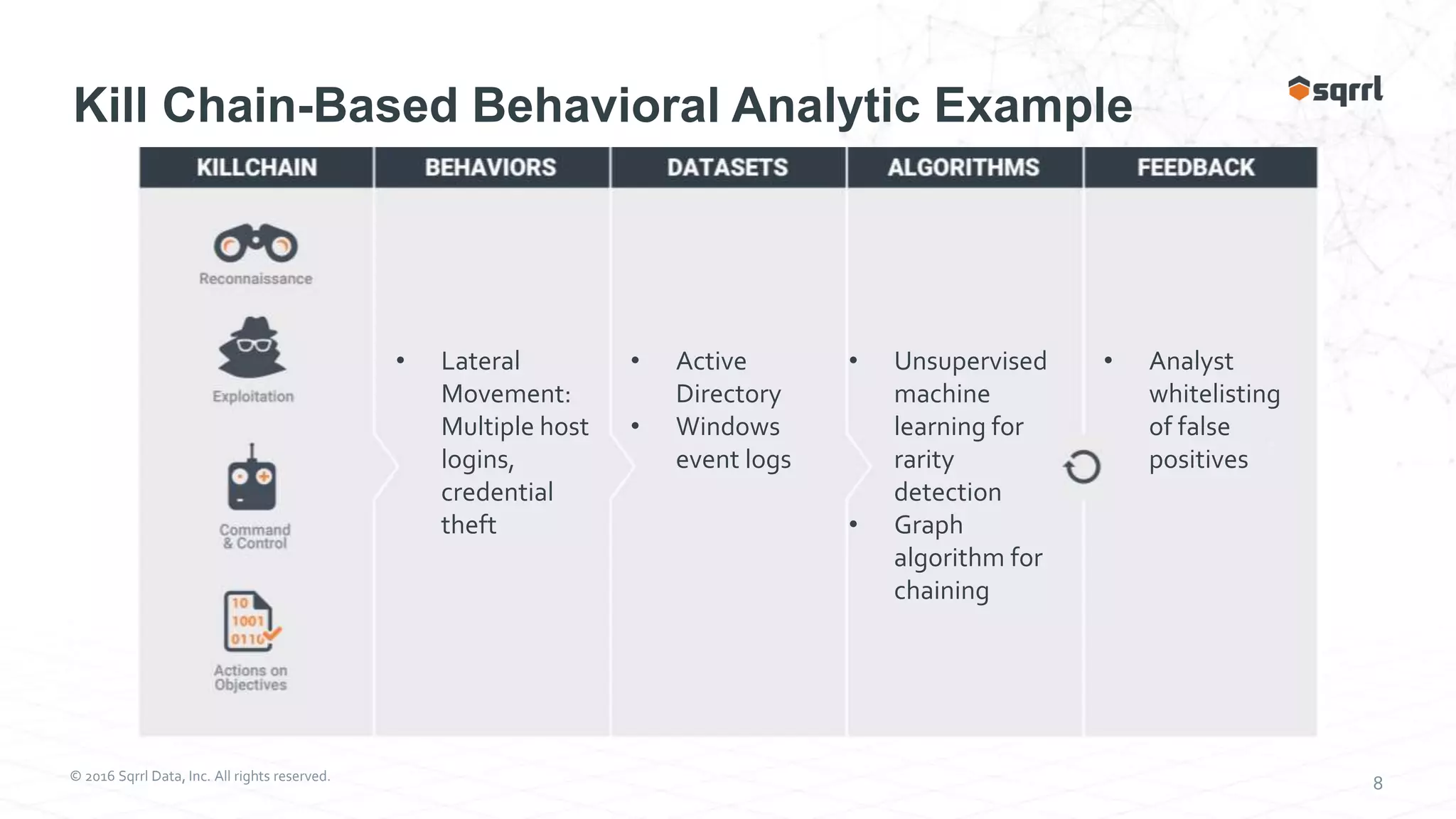



The document discusses the SqrrlThreat Hunting Platform, which collects security, network, and endpoint data to detect threats. It uses Apache Accumulo for distributed storage and processing. Behavioral analytics models adversary behavior based on the attack kill chain. Analytics run on the data to detect rare events and chain them together using graphs. Results are then collated for visualization and analysis to hunt, detect, and disrupt threats.












![Overview of the Cyber Kill Chain [TM]](https://cdn.slidesharecdn.com/ss_thumbnails/cybersecuritykillchain8-161209191549-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































