Downloaded 15 times














![© 2015 EXASOL AG
Example taken from Reynold Xin’s 2012 “Shark: Hive (SQL) on Spark” presentation
Map/Reduce: the wrong language for Analytics ?
Stage 0: Map-Shuffle-Reduce
Mapper(row) {
fields = row.split("t")
emit(fields[0], fields[1]);
}
Reducer(key, values) {
sum = 0;
for (value in values) {
sum += value;
}
emit(key, sum);
}
Stage 1: Map-Shuffle
Mapper(row) {
...
emit(page_views, page_name);
}
... shuffle
Stage 2: Local
data = open("stage1.out")
for (i in 0 to 10) {
print(data.getNext())
}](https://image.slidesharecdn.com/bcssqlandnosqlexasol-16-03-15-150319163205-conversion-gate01/85/SQL-vs-NoSQL-Why-you-ll-never-dump-your-relations-Dave-Shuttleworth-EXASOL-16-320.jpg)


















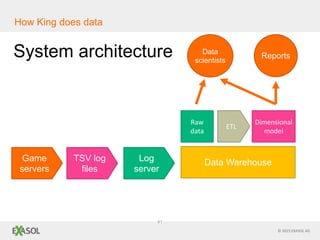
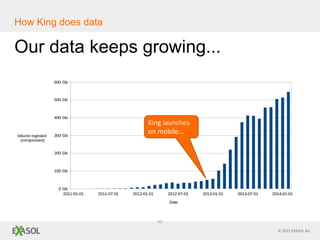
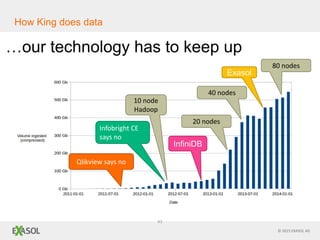
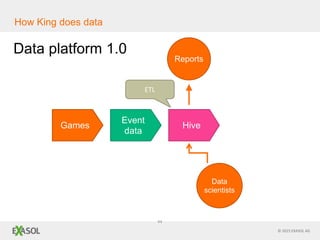
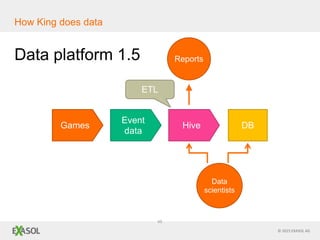

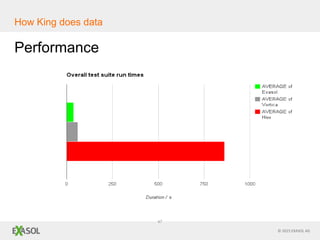
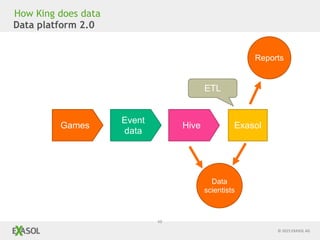
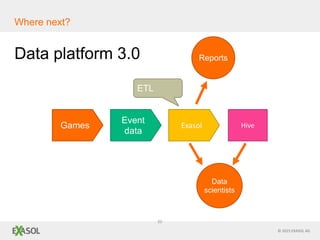

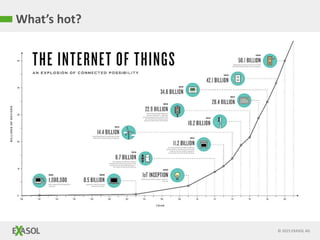









The document discusses SQL vs NoSQL databases. It provides background on the proliferation of NoSQL databases and their advantages over relational databases for handling unstructured data, high scalability, and easy distribution. However, it argues that SQL remains well-suited for analytical queries due to its portability, wide use, and the fact that many reporting tools are built for it. The document also presents a case study of how the online gaming company King uses a hybrid of SQL and NoSQL technologies to handle their massive scale of user data and high-volume analytics needs.



































































