- The document presents a new formulation of the attention mechanism in Transformers using kernels. This allows defining attention over a larger space and integrating positional embeddings.
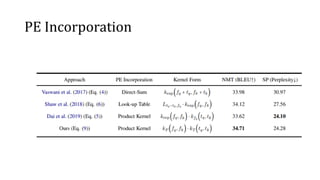
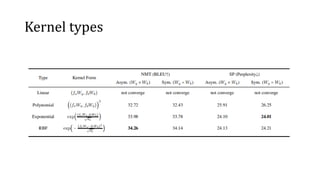
- Experiments on neural machine translation and sequence prediction tasks study different kernel forms like RBF and their combination with positional encodings.
- Results show the best kernel is the RBF kernel and competitive performance to state-of-the-art models with less computation.












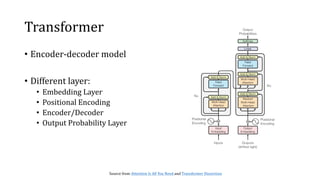



![• Transformer’s attention is an order-agnostic operation given the
order in the inputs.
• Transformer introduced positional embedding to indicate the
positional relation for the inputs.
• 𝒙 = [𝑥1, 𝑥2, ⋯ , 𝑥 𝑇]
• 𝑥𝑖 = (𝑓𝑖, 𝑡𝑖) with
• 𝑓𝑖 ∈ ℱ non-temporal feature (E.g., word representation, frame in a video etc.)
• 𝑡𝑖 ∈ 𝒯 temporal feature (E.g., sine and cosine functions)](https://image.slidesharecdn.com/transformerdissection-200609093026/85/Paper-Study-Transformer-dissection-16-320.jpg)























































![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)





























