This document summarizes a student homework assignment on speech watermarking. It discusses several key topics:
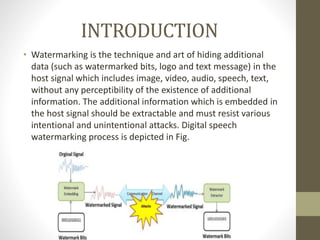
1. The introduction defines digital speech watermarking and its purpose of hiding additional data in audio signals imperceptibly. Two main types are discussed based on robustness to attacks.
2. Applications of digital speech watermarking include copy control, device control, owner identification, and proof of ownership.
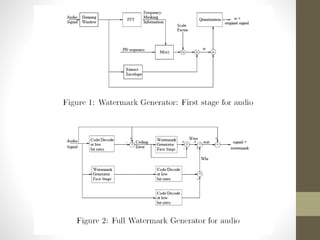
3. The watermark design embeds a unique codeword into each audio signal using a repeated application of a basic watermarking operation on processed audio segments.
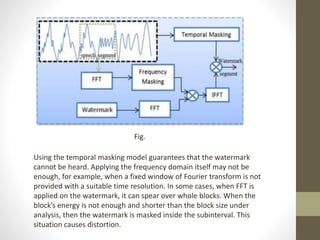
4. Watermark embedding and extraction techniques are discussed, making use of auditory masking in the frequency and temporal domains to embed water