Downloaded 10 times


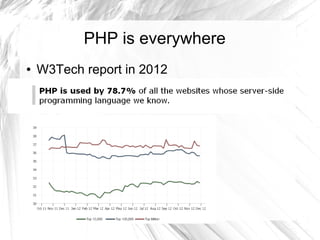
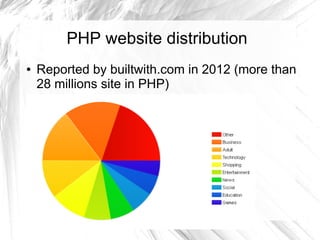





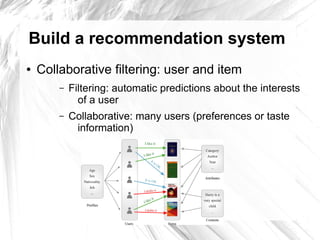
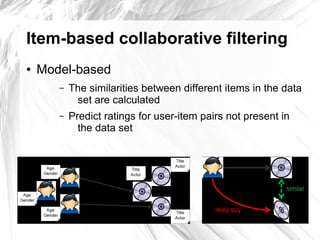













This document provides an introduction to item-based collaborative filtering for building recommendation engines. It discusses how recommendation systems can help provide engaging content for websites. Item-based collaborative filtering models calculate similarities between items based on user ratings and preferences, then uses those similarities to recommend other items users may like. The key steps are collecting user-item interaction data, calculating inter-item similarities, and using those similarities to compute and rank recommendations for users.





























![[Vietnam Mobile Day 2014] The new mobile marketing channel: Social Wifi Marke...](https://cdn.slidesharecdn.com/ss_thumbnails/topic16thenewmobilemarketingchannelsocialwifimarketing-vittun-pgcngtycphnlightbulbad-140528232603-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Vietnam Mobile Day 2014] Xu hướng trong Mobile Learning, 2014 - Nguyễn Thàn...](https://cdn.slidesharecdn.com/ss_thumbnails/topic8-140528065834-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Chiến lược thu hút người dùng cho ứng dụng tại thị ...](https://cdn.slidesharecdn.com/ss_thumbnails/topic15chinlcthuhtngidngchongdngtithtrngvitnam-nguynquc-gimckinhdoanhgmarkjsc-140528231045-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Cá nhân hóa và xác định Khách hàng mục tiêu trong q...](https://cdn.slidesharecdn.com/ss_thumbnails/cnhnhavxcnhkhchhngmctiutrongqungco-honganhtun-phgimcadtech-vccorp-140528232050-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Vietnam Mobile Day 2014] Mobile kết nối thế giới số và thế giới thực và vai ...](https://cdn.slidesharecdn.com/ss_thumbnails/topic16mobilektnithgiisvthgiithcvvaitrcanhnhng-peeyushshekhargimckhikhchhngthtrngmin-140529000231-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Tăng doanh thu quảng cáo cho mobile site và ứng dụn...](https://cdn.slidesharecdn.com/ss_thumbnails/topic15nguyenhaducminh-140529000814-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Touch the future of the web - Nguyễn Việt Anh - Cou...](https://cdn.slidesharecdn.com/ss_thumbnails/topic9touchthefutureoftheweb-nguynvitanh-countrymanager-operasoftwareasanorway-140528074029-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Thanh toán mobile, hiện tại và xu hướng- Nguyễn Chi...](https://cdn.slidesharecdn.com/ss_thumbnails/topic13thanhtonmobilehintivxuhng-nguynchinthng-ceompay-140528130531-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Thanh toán bằng thẻ ngân hàng trên mobile chưa bao ...](https://cdn.slidesharecdn.com/ss_thumbnails/topic12thanhtonbngthngnhngtrnmobilechabaogiddnghnth-trnquangkhi-gimccngthanhton-140528125609-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Toàn cảnh thị trường game smartphone Việt Nam 2013....](https://cdn.slidesharecdn.com/ss_thumbnails/topic3toncnhthtrnggamesmartphonevitnam2013-140528063803-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] Toàn cảnh thị trường game smartphone Việt Nam 2013....](https://cdn.slidesharecdn.com/ss_thumbnails/topic3toncnhthtrnggamesmartphonevitnam2013-140528062620-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Vietnam Mobile Day 2014] Mobile money - Xu hướng thanh toán nhỏ trên mobile ...](https://cdn.slidesharecdn.com/ss_thumbnails/topic8mobilemoney-xuhngthanhtonnhtrnmobile-nguynmnhtngphgimcmservice-140529000248-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Vietnam Mobile Day 2014] How to build a mobile store app in 5 minutes - Ng...](https://cdn.slidesharecdn.com/ss_thumbnails/topic11-140528125157-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)