




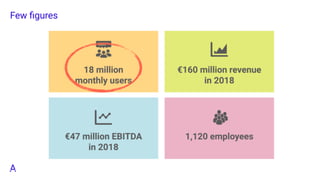











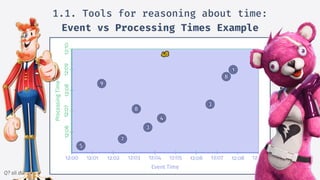










![Q? sli.do #5910
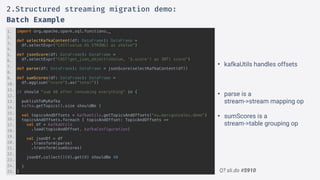
def jsonScoreAndDate(df: DataFrame): DataFrame =
df.selectExpr(
"from_json(sValue, 'score INT, eventTime LONG, delayInMin INT') struct",
"timestamp as procTime")
.select(col("struct.*"), 'procTime)
.selectExpr("timestamp(eventTime/1000) as eventTime", "score", "procTime")
def parse(df: DataFrame): DataFrame = {
jsonScoreAndDate(selectKafkaContent(df))
}
def windowedSumScores(df: DataFrame): DataFrame =
df.groupBy(window($"eventTime", "2 minutes")).agg(sum("score").as("total"))
it should "sum 14, 18, 4, 12 after consuming everything in 2 minute windows" in {
val topicsAndOffsets = kafkaUtils.getTopicsAndOffsets("eu.marcgonzalez.demo")
topicsAndOffsets.foreach { topicAndOffset: TopicAndOffsets =>
val df = kafkaUtils
.load(topicAndOffset, kafkaConfiguration)
val jsonDf = df
.transform(parse)
.transform(windowedSumScores)
jsonDf
.sort("window").collect()
.foldLeft(Seq.empty[Int])(
(a, v) => a ++ Seq(v.get(1).asInstanceOf[Long].toInt)
) shouldBe Seq(14, 18, 4, 12)
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
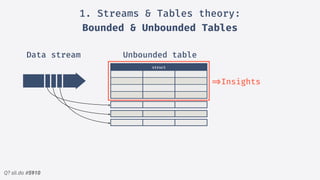
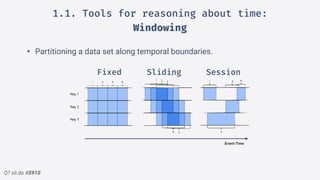
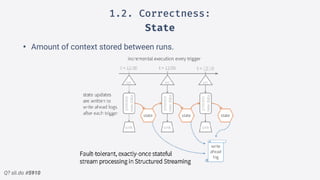
2.Structured streaming migration demo:
Windowed Batch
• Extract eventTime from JSON
• Always try to enforce a
schema (JSON, AVRO)
• Fixed window partitions our
insight](https://image.slidesharecdn.com/sparkmeetuppdfnomotion-191209151325/85/Spark-Barcelona-Meetup-Migrating-Batch-Jobs-into-Structured-Streaming-38-320.jpg)
![Q? sli.do #5910
it should "sum 14,18,4,12 after streaming everything in 2 minute windows" in {
val topicsAndOffsets = kafkaUtils.getTopicsAndOffsets("eu.marcgonzalez.demo")
topicsAndOffsets.foreach { topicAndOffset: TopicAndOffsets =>
val df = spark.readStream
.format(“kafka")
.option(“kafka.bootstrap.servers", "localhost:9092")
.option("startingOffsets", "earliest")
.option("subscribe", topicAndOffset.topic)
.load()
df.isStreaming shouldBe true
val jsonDf = df
.transform(parse)
.transform(windowedSumScores)
val query = jsonDf.writeStream
.outputMode("update") //complete
.format("memory") //console
.queryName(queryName)
.trigger(Trigger.ProcessingTime("5 seconds")) //Once
.start()
query.awaitTermination(10 * 1000)
spark.sql(s"select * from $queryName order by window asc")
.collect()
.foldLeft(Seq.empty[Int])(
(a, v) => a ++ Seq(v.get(1).asInstanceOf[Long].toInt)
) shouldBe Seq(14, 18, 4, 12)
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
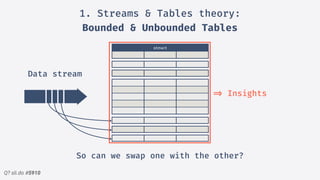
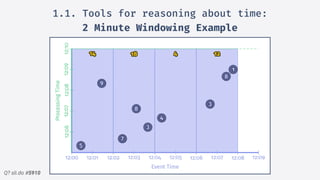
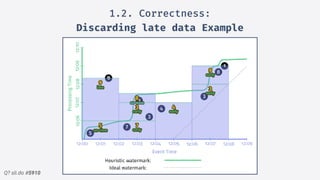
2.Structured streaming migration demo:
Windowed Stream Example
• read -> readStream, allowing S.S.S.
to take control over the input
offsets.
• Our dataframe is now a streaming
dataframe, & supports all previous
ops.
• write -> writeStream
• Modes: Complete, Update &
Append
• Sinks: Kafka, File, forEach,
memory & console for debug.
• Queryable state -> Eventual
Consistency](https://image.slidesharecdn.com/sparkmeetuppdfnomotion-191209151325/85/Spark-Barcelona-Meetup-Migrating-Batch-Jobs-into-Structured-Streaming-39-320.jpg)
![Q? sli.do #5910
it should "sum 5,18,4,12 after streaming everything in 2 minute windows" in {
timelyPublishToMyKafka
val topicsAndOffsets = kafkaUtils.getTopicsAndOffsets("eu.marcgonzalez.demo")
topicsAndOffsets.foreach { topicAndOffset: TopicAndOffsets =>
// Same reader as previous
val jsonDf = df
.transform(parse)
.withWatermark("eventTime", "2 minutes")
.transform(windowedSumScores)
val query = jsonDf
.writeStream
.outputMode(“update") //append
.format(“memory")
.queryName(queryName)
.trigger(Trigger.ProcessingTime("5 seconds”))
.start()
query.awaitTermination(15 * SECONDS_MS)
spark.sql(s"select window, max(total) from $queryName
group by window order by window asc")
.collect()
.foldLeft(Seq.empty[Int])(
(a, v) => a ++ Seq(v.get(1).asInstanceOf[Long].toInt)
) shouldBe Seq(5, 18, 4, 12)
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
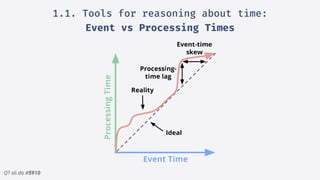
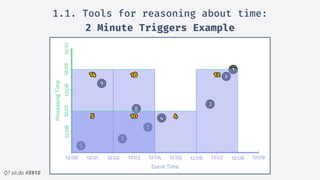
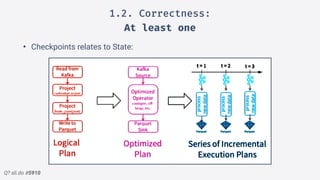
2.Structured streaming migration demo:
Windowed Stream + Watermark Example
• Introduce a delay when
sending to kafka.
• We add a 2 minute watermark
• Event on a closed window gets
discarded!
• Append mode only sends
closed windows.](https://image.slidesharecdn.com/sparkmeetuppdfnomotion-191209151325/85/Spark-Barcelona-Meetup-Migrating-Batch-Jobs-into-Structured-Streaming-40-320.jpg)










This document summarizes Marc Gonzalez's presentation on migrating batch jobs into structured streaming. The presentation covers streams and tables theory, including how bounded and unbounded tables relate to streams. It then demonstrates migrating a batch job that sums scores over windows to a structured streaming job in Spark, covering aspects like event vs processing time and watermarks. Finally, it discusses the Beam model and upcoming Apache Beam meetup.



































































