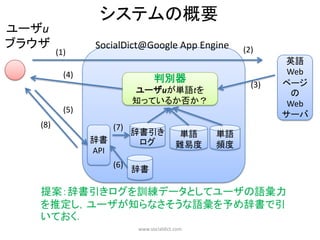
素性を追加
θ (1 , , u , , |U | ), d ( d1 , , dt , , d|T | )
eu (0,,1, 0, 0) et (0, ,1, 0 , 0)
u t
|U| |T|
w rasch θ d , φrasch (u, t ) eu et とすると,
T T
P( yn 1| un , tn ) u dt
(w rasch φ rasch (u, t ))と表せる
T
www.socialdict.com
24.
素性を追加
w rasch θ d
T
Rasch: φrasch (u, t ) eu et
T
LOGRES: w LOGRES θ d w a
T
(強化版) φ LOGRES (u, t ) (eu et φ a )T
φaに素性を追加することが可能.追加した素性:
•Google 1-gram
約1兆ページのWebページ中の英単語の頻度.
•SVL12000
人手で基本的な単語12,000語に対し,難易度を12段階でつ
けたもの.
www.socialdict.com
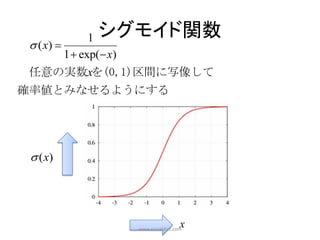
補足4 (1/2):2値を1本の式で表現
y
P( yn 1| u , t ; w ) w φ w φ
T T
0 | u; w ) 1 w φ 1 w φ
1 y
T T
P ( yn
より、
1 w φ
y 1 y
P( y | φ; w ) w φ T T
と表せる。
www.socialdict.com
27.
補足4 (2/2):対数尤度関数を定義
結局、N本のデータを考え、次の対数尤度関数
E(w)をwに関して最小化する問題に落とせる
N
E (w ) log P( yn | φ n ; w )
n 1
N
log P( yn | φ n ; w )
n 1
log w T φ n 1 w φ
N yn 1 yn
T
n
n 1
N
yn log w T φ n 1 yn log 1 w T φ n
n 1
www.socialdict.com
28.
SGD
N
w arg max P( yn | un , tn ; w ) arg min E ( w)
w n 1 w
N N
E (w ) log P( yn | un , tn ; w) , E (w ) En (w )
n 1 n 1
1
k λ, k0は定数
( k k0 ) (ハイパーパラメータ)
SGD: w ( k 1) w ( k ) k En (w ( k ) )
N
最急降下法: w ( k 1) w ( k ) En (w ( k ) )
(比較) n 1
ηは定数
www.socialdict.com
語彙力測定方法
自己申告式 折衷式 自己申告式
Dale (1965) Paribakht+ (1993) 今回の設定
I never saw it before. I have never seen this 見たこともない
word.
見たことがある気が
する
I’ve heard of it, but I I have seen this word 確 実 に 見 た こ と は あ
don’t know what it before, but I don’t know るが意味は知らない/
means. what it means. 覚えたことがあるが
意味を忘れている
I recognize it in I have seen this word 意 味 を 知 っ て い る 気
context. before, and I think it がする/意味が推測で
means xxx. きる
I know it. I know this word. It means 意 味 を 確 実 に 知 っ て
xxx. いる
I can use this word in a
sentence.
www.socialdict.com
31.
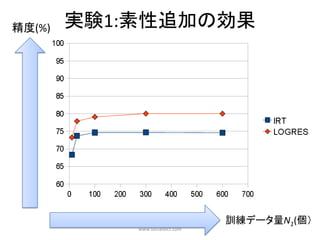
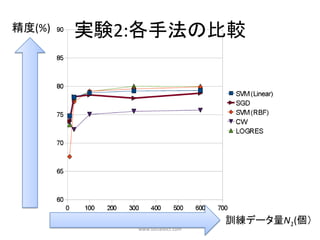
実験設定
実験目的:どの程度システムを使い込むと,どの程度の精度で予
測可能なのかを測定する.
•辞書引きログがN0個蓄積されたところにユーザが1人新規にシ
ステムを使い始め,N1個の単語の既知/非既知が得られたと想
定.
• この時,そのユーザのTestに含まれる単語のうち何%について
既知/非既知を正解できたかを1人の精度とした.
• 12000語を
ログ(N0)+10~600語(N1) Training
1400語 Development
9999語 Test
に分割し、16人の精度の平均値を計算。
• ログは,辞書引きログの代わりに,同じ(yn,un,tn)の形式のログ
が残るsmart.fm(旧iKnow)というシステムのログで代用
www.socialdict.com