The document provides an overview of social network analysis (SNA), detailing its definition, use cases, and applications in mapping relationships and flows among various entities. It introduces the NetworkX Python package for creating and analyzing complex networks, along with installation instructions and dependencies. Additionally, it includes beginner guidance on using NetworkX to create graphs.




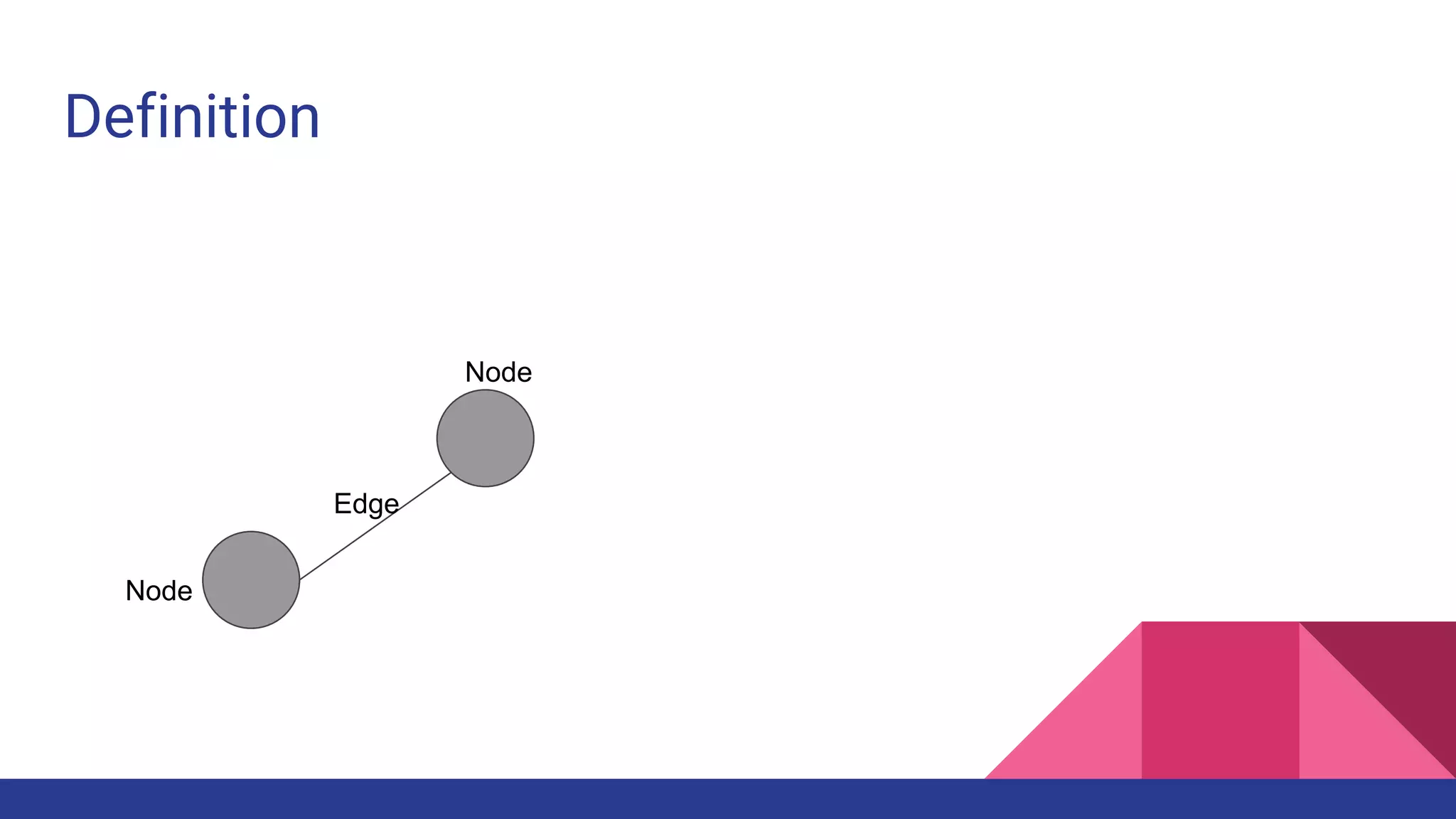
![What is?
Social network analysis [SNA] is the mapping and measuring of relationships and
flows between people, groups, organizations, computers, URLs, and other
connected information/knowledge entities.](https://image.slidesharecdn.com/socialnetworkanalysisdengannetworkx-171117081033/75/Social-Network-Analysis-dengan-NetworkX-5-2048.jpg)





















![Social network analysis [SNA] is the mapping and measuring of relationships a...](https://cdn.slidesharecdn.com/ss_thumbnails/representationandclassesofproerties-241121092336-8d88e173-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

