LINKEDIN: SOCIAL NETWORKDAT
PROEFSSIONALS HELPT
PRODUCTIEVER EN SUCCESVOLLER TE
WORDEN
TRACK ALLE CLICKS, PAGE VIEWS,
INTERACTIONS
AANBEVELING VOOR CONNECTIES,
PROFILE VIEWS, ADVERTISING
+40 MILJOEN NIEUWE LEDEN Q1 + Q2
2015
700 MILJOEN OMZET PER KWARTAAL
3
4.
NEST: SLIMME THERMOSTAATMET
INTERNET OF THINGS OPZET
REDUCTIE VAN ENERGIE-VERSPILLING
NEST LEERT GEBRUIKSPATROON, LEGT
IEDERE ACTIE VAST
STEMT VERWARMING DAAR OP AF
-50% ENERGIE-VERSPILLING
-10% VERWARMINGSKOSTEN
-15% AIRCO KOSTEN
4
5.
ONLY 1/5 OFMEDICAL
DOCTORS WITH STATISTICAL
TRAINING CAN UNDERSTAND
SCIENTIFIC RESEARCH
PAPERS
...MOST MEDICAL DOCTORS
DON’T HAVE STATISTICAL
TRAINING
5
STIJN HOPPENBROUWERS
Stijn Hoppenbrouwersis lector Data & Knowledge Engineering bij de HAN en universitair
docent bij de afdeling Data Science aan de Radboud Universiteit. Vanuit een achtergrond
in informatiesystemen en taalwetenschappen, een PhD in Computer Science, richt Stijn
zich op praktijkgericht ontwerp en toepassing van data- en kennistechnologie, met open
oog voor het samenspel tussen techniek, mens en organisatie.
MAYA SAPPELLI
Maya Sappelli is onderzoeker Data Science bij het lectoraat Data & Knowledge
Engineering bij de HAN. Maya heeft een achtergrond in Kunstmatige Intelligentie en
Taalwetenschappen, en een PhD in Computer Science. Na toegepast onderzoek te
hebben gedaan bij TNO en FDMG richt ze zich bij de HAN op het helpen van bedrijven
en organisaties om meerwaarde te creëren met data door het inzetten van de juiste
technieken.
11.
LEAN & BIGDATA / MACHINE LEARNING
Artificial intelligence: Autonomous,
machine-based reasoning system
Omgeving waarnemen
Redeneren over doelen
Acties in gang zetten
Data science: methoden, processen en
systemen om kennis en inzichten te
onttrekken uit (zowel gestructureerde als
ongestructureerde) data
12.
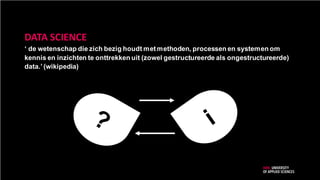
‘ de wetenschapdie zich bezig houdt metmethoden, processen en systemen om
kennis en inzichten te onttrekken uit (zowel gestructureerde als ongestructureerde)
data.’ (wikipedia)
DATA SCIENCE
13.
VRAAG & ANTWOORD
•Typen Vragen:
- Descriptief (beschrijvend): Hoeveel auto’s heb ik verkocht?
- Predictief (voorspellend): Hoeveel auto’s zal ik volgende maand verkopen?
- Prescriptief (voorschrijvend): Wat moet ik doen om 10% meer auto’s te
verkopen?
• Typen Antwoorden:
- Geven kennis of informatie bijv. informatie over de huidige situatie
- Lossen een probleem op bijv. reduceren de hoeveelheid benodidgde
menselijke inzet
- Ondersteunen een beslissing: bijv. een constatering van een tumor met hoge
zekerheid
- Geven een financieel voordeel: bijv. meer gebruikers
14.
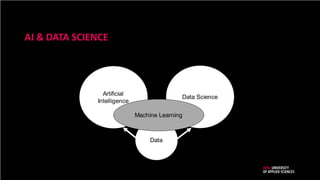
AI & DATASCIENCE
Artificial
Intelligence
Data
Data Science
Machine Learning
16.
Data Science
Big Data
AI
DeepLearning
Machine Learning
Sensor Data
IoT
Social Media
Analytics
Statistics
SPSS
R
Python
Text Mining
Natural Language Processing
Logic
Decision Support
Semantic Web
OntologiesExpert Systems
Databases
Data Modelling
Data Warehousing
Data Management
Data Governance
SQL
Data semantics
Data Quality Data Engineering
NoSQL Business Intelligence (BI)
Applied
(e)Health
Energy
Smart Industry
Smart Mobility
Smart Cities
Legal Tech
Privacy
Security
Media
TensorflowHadoop
Docker
Ethics
Explainability
17.
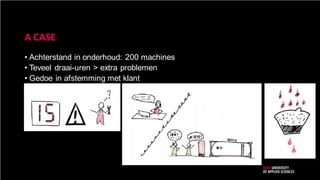
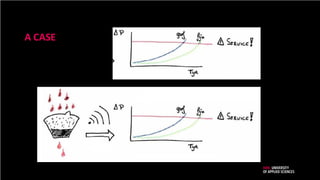
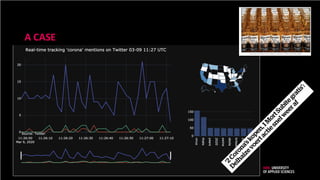
A CASE
• Achterstandin onderhoud: 200 machines
• Teveel draai-uren > extra problemen
• Gedoe in afstemming met klant
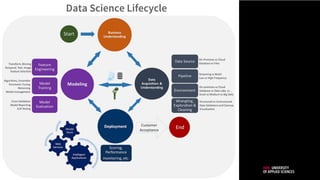
Modeling Task
Value Proposition
End-UserActions Data Sources
Deployment
and Integration
Monitoring and
Value Testing
Licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.Adapted from The Machine Learning Canvas by Louis Dorard, Ph.D.
Machine Learning Canvas Designed for: Designed by: Date: Iteration: .
End-User Persona
Model Evaluation
Business Objectives
What methods and
metrics can be used to
monitor ’online’ model
performance? How is
the actual business
value measured?
How can the model be
deployed and brought
into production? How
is it exposed to the
end-user and
integrated in a product
or service?
How do predictions elicit actions (or
decisions) that result in the proposed value
for the end-user?
What are we going to predict and with what
information? What is the type of machine
learning problem?
Which raw data sources can we use (internal
and external)? How and with what frequency
should the data be collected?
What methods and metrics can be used to
evaluate the ‘offline’ performance? What is
the cost of being wrong?
Who are the end-users of the predictive model? What are the
jobs they need to get done? What are their immediate pains and
potential gains in trying to do so?
How do we help the end-users get the job done and satisfy
their needs? How do we alleviate or eliminate their pains and
create value through gains?
What business objectives are we serving? What KPI will be
improved and by how much? What is the business value and
how can it be measured?
21.
YOUR CASE
• Watzijn zoal interessante databronnen die je kent?
• Intern / Extern
• Wat zijn issues op het werk die je nu hebt?
• Welke informatievraag zit daar achter? (dialoog)
• Hoe kun je naar antwoord toewerken op basis van info/data bronnen?
• Heb je die bronnen al, of moet je er aan zien te komen?
22.
UITDAGINGENKANSEN
TAKE AWAYS: COMPUTERSAYS …
• Voorspellen kwaliteit
• Planning verbeteren
• Versterking medewerkers
• Patronen ontdekken
• Nieuwe toepassingen ontdekken
• Complex
• Formaliseren
• Veel goede data nodig
• Beperkte statistische kennis
SENTIMENT ANALYSE
Wat ishet sentiment?
1. Op basis van woordenlijsten - 'negatieve woorden' en 'positieve woorden'
a. Is 'ziek', negatief of positief
b. Hoe zit het met 'geen idee' of 'niet zo goed'
2. Op basis van machine learning
Uitdagingen:
- sarcasme, ironie, etc.
- meerdere sentimenten in 1 zin
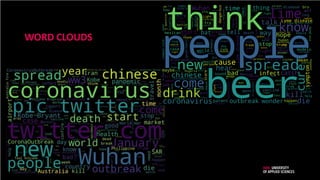
ONGESTRUCTUREERDE DATA: ANDERETOEPASSINGEN
• Klachtenanalyse
• Analyse van foutmeldingen
• Zoeken van informatie in tekstuele documenten
• Juridisch Kennismanagement
• Beeldherkenning
34.
YOUR CASE
• Watvoor ongestructureerde data heb je in huis?
• Wat voor externe data kan relevant zijn?
• Is er een vraag die je met deze data zou kunnen beantwoorden?
• Moet er daarvoor nog een interpretatieslag gemaakt worden?
35.
TAKE AWAYS
• Eris gestructureerde en ongestructureerde data
- Andere eigenschappen
- Andere visualisaties
• Ongestructureerde data moet nog ’geinterpreteerd’ worden:
- Wie
- Wat
- Waar
- Hoe
36.
CONCRETE PROJECTEN ENOPLEIDINGEN
< Master Engineering Systems – Lean
< Lean 4zero
Master Applied Data Sciences >
Lean & Robotica >
< Digital factory
Factory of the future >