Download as PDF, PPTX




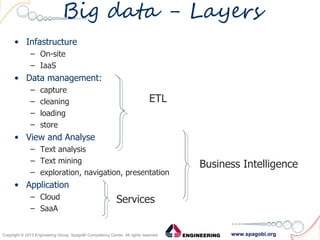

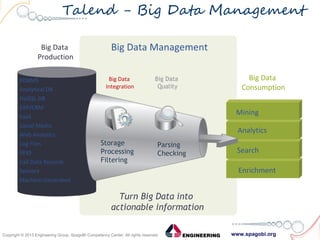


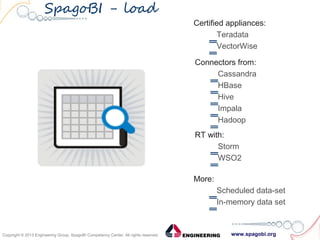
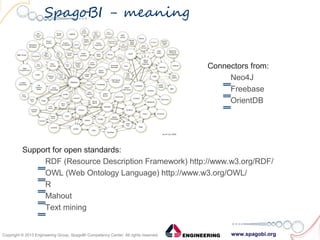
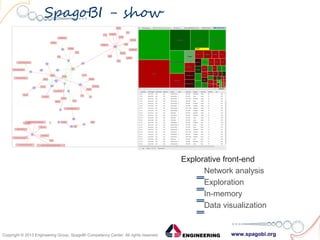
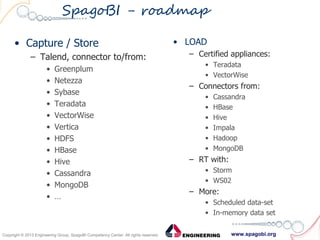
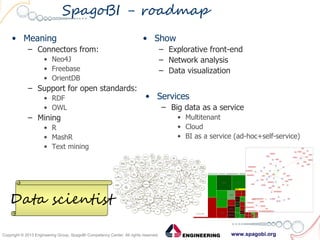



The document outlines the collaboration between SpagoBI and Talend to address big data challenges by leveraging their respective tools for data management and business intelligence. It discusses key big data characteristics such as volume, variety, velocity, variability, veracity, and value, as well as the infrastructure and processes involved in managing big data. Additionally, it highlights the roadmap for integrating both platforms to enhance their capabilities and provide comprehensive data solutions.

































































![[SFScon'17] More than a decade with free open source software](https://cdn.slidesharecdn.com/ss_thumbnails/sfsconfinalruffatti-171115143706-thumbnail.jpg?width=640&height=640&fit=bounds)












![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








