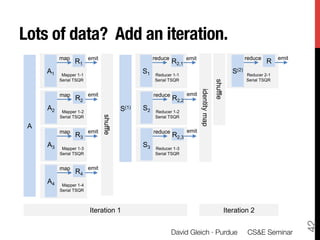
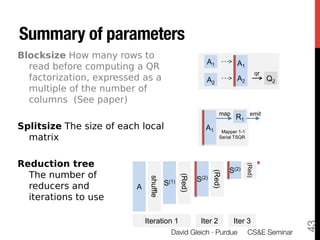
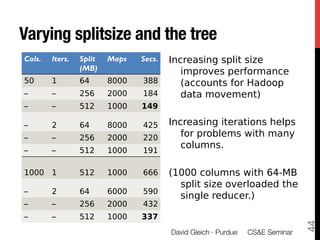
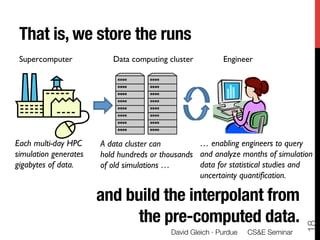
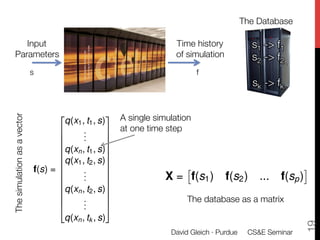
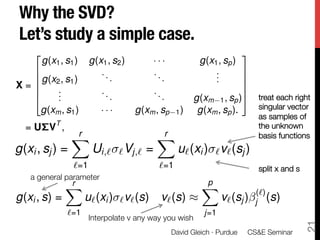
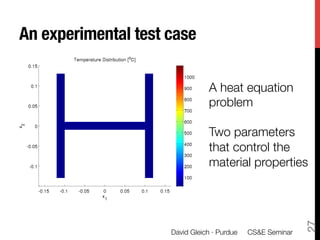
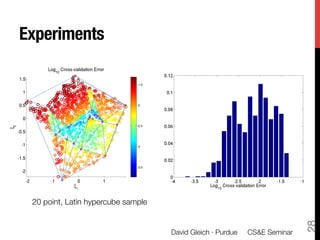
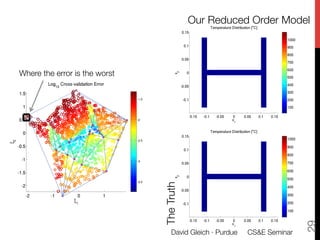
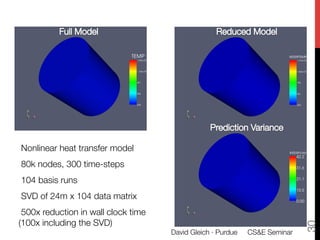
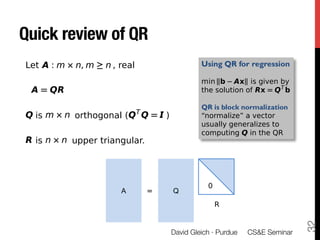
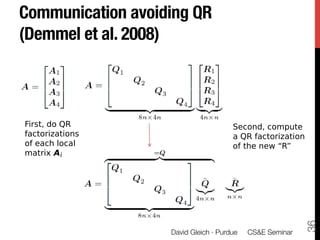
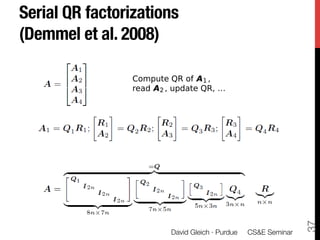
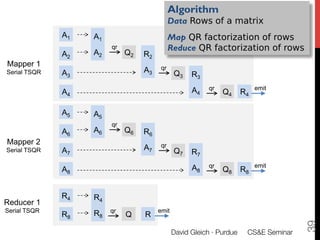
1) The document discusses using large datasets from scientific simulations to analyze uncertainty quantification (UQ) through techniques like randomized parameter studies and reduced order modeling.
2) The author presents work using PageRank as a test case for examining UQ and developing generalized methods for studying parameterized matrix equations.
3) The approach involves constructing an interpolating reduced order model from an ensemble of pre-computed simulation runs stored in a data cluster to enable engineers to efficiently query simulation data for statistical analysis and UQ studies without running new expensive simulations.





![h sensitivity?
alpha alpha PageRank
PageRa
PageRank
RandomPageRank
dom alpha
Random alpha
RAPr
or PageRank meets UQ
( P)x = (1 )v
s the random variables as the random variables
Model PageRank
ageRank as the random variables
y to the links : examined and understoo
x(A) x(A)
x(A)
and look at
k E [x(A)] and Std [x(A)] .
at
E [x(A)] and Std [x(A)] .
y to the E [x(A)]: and Std [x(A)] .understood,
jump examined,
Explored in Constantine and Gleich, WAW2007; and "
Constantine and Gleich, J. Internet Mathematics 2011.
6
David Gleich · Purdue
CS&E Seminar](https://image.slidesharecdn.com/simform-gleich-purdue-cse-2-short-120223101405-phpapp01/85/Simulation-Informatics-Analyzing-Large-Scientific-Datasets-6-320.jpg)
![Random alpha PageRank has
Convergence theory
a rigorous convergence theory.
Method Conv. Work Required What is N?
1 number of
Monte Carlo p N PageRank systems
N samples from A
Path Damping
r N+2 N + 1 matrix vector terms of
(without
N1+ products Neumann series
Std [x(A)])
number of
Gaussian
r 2N N PageRank systems quadrature
Quadrature
points
and r are parameters from Bet ( , b, , r)
7
David F. Gleich (Sandia) David
Random sensitivity Gleich · Purdue
CS&E Seminar
/ 36
Purdue 27](https://image.slidesharecdn.com/simform-gleich-purdue-cse-2-short-120223101405-phpapp01/85/Simulation-Informatics-Analyzing-Large-Scientific-Datasets-7-320.jpg)













![A refined method with !
an error model
Don’t even try to
interpolate the
predictable modes.
t(s) r
X X
f(s) ⇡ uj ↵j (s) + uj j ⌘j
j=1 Predictable
j=t(s)+1 Unpredictable
⌘j ⇠ N(0, 1)
0 1
r
X
TA
Variance[f] = diag @ j uj uj
j=t(s)+1
But now, how to choose t(s)?
25
David Gleich · Purdue
CS&E Seminar](https://image.slidesharecdn.com/simform-gleich-purdue-cse-2-short-120223101405-phpapp01/85/Simulation-Informatics-Analyzing-Large-Scientific-Datasets-25-320.jpg)




![In hadoopy
Full code in hadoopy
import random, numpy, hadoopy def close(self):
class SerialTSQR: self.compress()
def __init__(self,blocksize,isreducer): for row in self.data:
key = random.randint(0,2000000000)
self.bsize=blocksize yield key, row
self.data = []
if isreducer: self.__call__ = self.reducer def mapper(self,key,value):
else: self.__call__ = self.mapper self.collect(key,value)
def reducer(self,key,values):
def compress(self): for value in values: self.mapper(key,value)
R = numpy.linalg.qr(
numpy.array(self.data),'r') if __name__=='__main__':
# reset data and re-initialize to R mapper = SerialTSQR(blocksize=3,isreducer=False)
self.data = [] reducer = SerialTSQR(blocksize=3,isreducer=True)
for row in R: hadoopy.run(mapper, reducer)
self.data.append([float(v) for v in row])
def collect(self,key,value):
self.data.append(value)
if len(self.data)>self.bsize*len(self.data[0]):
self.compress()
41
David Gleich (Sandia) MapReduce 2011 13/22
David Gleich · Purdue
CS&E Seminar](https://image.slidesharecdn.com/simform-gleich-purdue-cse-2-short-120223101405-phpapp01/85/Simulation-Informatics-Analyzing-Large-Scientific-Datasets-41-320.jpg)