Downloaded 28 times











![1 A database cleaning point of view
Recognizing / merging entities
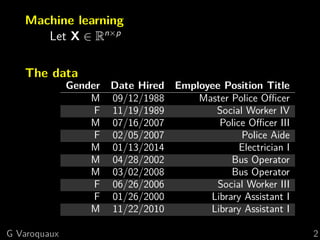
Record linkage:
matching across different (clean) tables
Deduplication/fuzzy matching:
matching in one dirty table
Techniques [Fellegi and Sunter 1969]
Supervised learning (known matches)
Clustering
Expectation Maximization to learn a metric
Outputs a “clean” database
G Varoquaux 9](https://image.slidesharecdn.com/slides-181120121444/85/Similarity-encoding-for-learning-on-dirty-categorical-variables-13-320.jpg)


![1 A natural language processing point of view
Stemming / normalization
Set of (handcrafted) rules
Need to be adapted to new language / new domains
Semantics
Relate different discreet objects
Formal semantics (entity resolution in knowlege bases)
Distributional semantics:
“a word is characterized by the company it keeps”
Character-level NLP
For entity resolution [Klein... 2003]
For semantics [Bojanowski... 2017]
“London” & “Londres” may carry different information
G Varoquaux 10](https://image.slidesharecdn.com/slides-181120121444/85/Similarity-encoding-for-learning-on-dirty-categorical-variables-16-320.jpg)
![1 A machine-learning point of view
High-cardinality categorical data
Encoding each category blows up the dimension
Target encoding [Micci-Barreca 2001]
Represent each category by
a simple statistical link to the target y
eg E[y|Xi = Ck]
1D real-number embedding for a categorical column
Bring close categories with same link to y
Great for tree-based machine-learning [Dorogush...]
G Varoquaux 11](https://image.slidesharecdn.com/slides-181120121444/85/Similarity-encoding-for-learning-on-dirty-categorical-variables-17-320.jpg)
![1 A machine-learning point of view
High-cardinality categorical data
Encoding each category blows up the dimension
Target encoding [Micci-Barreca 2001]
Represent each category by
a simple statistical link to the target y
eg E[y|Xi = Ck]
1D real-number embedding for a categorical column
Bring close categories with same link to y
Great for tree-based machine-learning [Dorogush...]
But fails on unseen categories
G Varoquaux 11](https://image.slidesharecdn.com/slides-181120121444/85/Similarity-encoding-for-learning-on-dirty-categorical-variables-18-320.jpg)
![2 Similarity encoding
[P. Cerda, G. Varoquaux, & B. Kegl, Machine Learning 2018]
G Varoquaux 12](https://image.slidesharecdn.com/slides-181120121444/85/Similarity-encoding-for-learning-on-dirty-categorical-variables-19-320.jpg)
![2 Similarity encoding
[P. Cerda, G. Varoquaux, & B. Kegl, Machine Learning 2018]
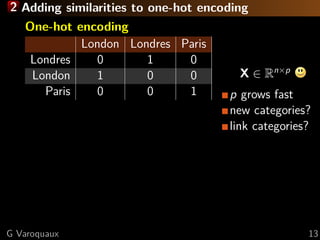
1. One-hot encoding maps categories to vector spaces
2. String similarities capture information
G Varoquaux 12](https://image.slidesharecdn.com/slides-181120121444/85/Similarity-encoding-for-learning-on-dirty-categorical-variables-20-320.jpg)



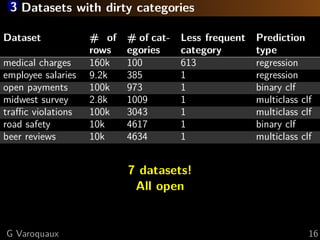

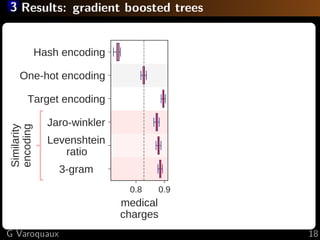
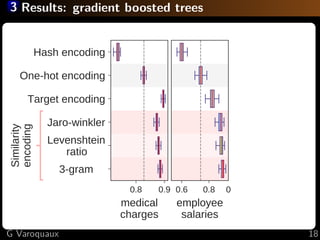
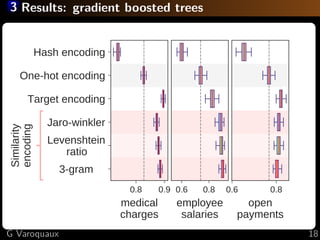



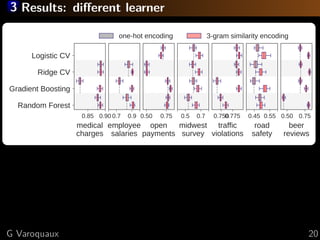

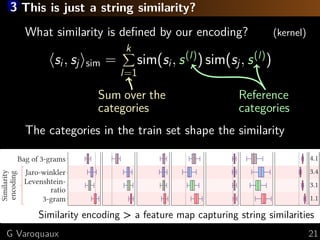


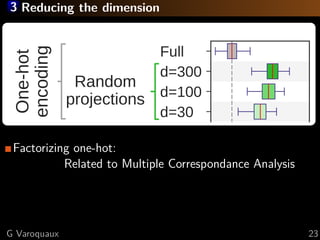
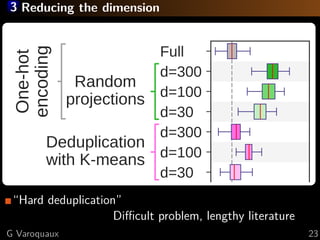

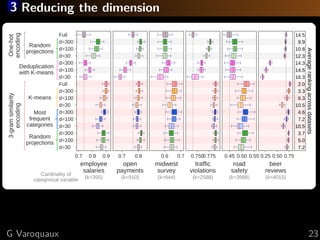
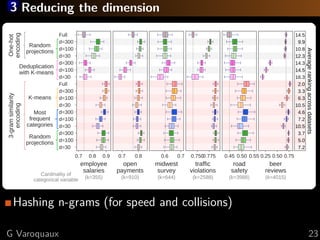




The document discusses the challenges of handling 'dirty' categorical variables in machine learning, emphasizing issues like typos, overlapping categories, and high cardinality. It introduces the concept of similarity encoding as a solution to improve statistical learning on these messy datasets. The empirical study presented compares various data encoding techniques and demonstrates that similarity encoding can outperform traditional methods such as one-hot encoding.