Downloaded 11 times









![Preprocessing
● Tokenize all text columns with OpenNLP, lowercase tokens
and filter out stop words ["‐", "-", "-", "‒", "–", "—", "―", "-", "+", "/", "*",
".", ",", "'", "(", ")", """, "&", ":", "to", "of", "and", "or", "for", "the", "a"]](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-9-320.jpg)
![Preprocessing
● Tokenize all text columns with OpenNLP, lowercase tokens
and filter out stop words ["‐", "-", "-", "‒", "–", "—", "―", "-", "+", "/", "*",
".", ",", "'", "(", ")", """, "&", ":", "to", "of", "and", "or", "for", "the", "a"]
● Perform softmax normalization for all float columns
● Replace all NaNs in float columns with 0](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-10-320.jpg)
![Preprocessing
● Tokenize all text columns with OpenNLP, lowercase tokens
and filter out stop words ["‐", "-", "-", "‒", "–", "—", "―", "-", "+", "/", "*",
".", ",", "'", "(", ")", """, "&", ":", "to", "of", "and", "or", "for", "the", "a"]
● Perform softmax normalization for all float columns
● Replace all NaNs in float columns with 0
● Keep floats intact, replace NaNs with the specified value
or](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-11-320.jpg)
![Word representation
One-hot encoding
social [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-12-320.jpg)


![Bag-of-words
Text column features
Sub_Object_Description
employees
wages
salaries
services
personal [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-15-320.jpg)
![Bag-of-words
Text column features
Sub_Object_Description
employees
wages
salaries
services
personal [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Sub_Object_Description_bow [0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0]
∑](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-16-320.jpg)






![Bag-of-words
(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encoding
social [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-23-320.jpg)
![Bag-of-words
(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encoding
social [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
● Impossible to generalize to unseen words](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-24-320.jpg)
![Bag-of-words
(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encoding
social [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
● Impossible to generalize to unseen words
● One-hot encoding can be memory inefficient](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-25-320.jpg)
![Word representation
Distributed representation
social [-0.56, 8.65, 5.32, -3.14]
public [-0.42, 9.84, 4.51, -2.71]](https://image.slidesharecdn.com/wordembeddingsforsocialgoods-150310143924-conversion-gate01/85/Word-embeddings-for-social-goods-26-320.jpg)
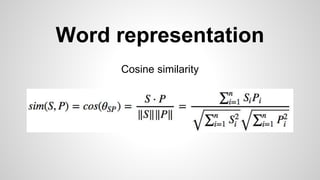











































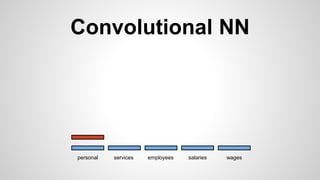
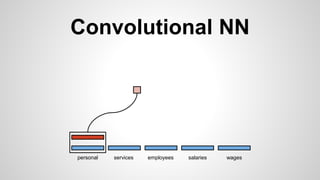
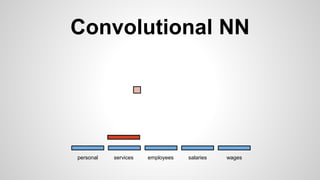
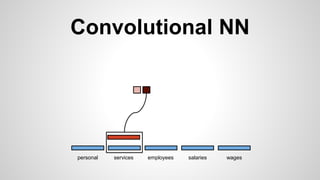

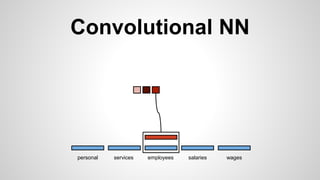

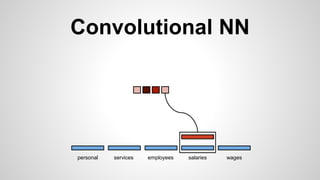

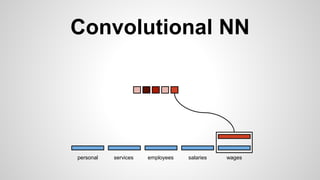


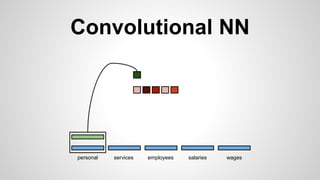

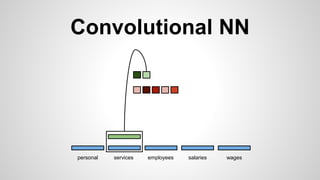

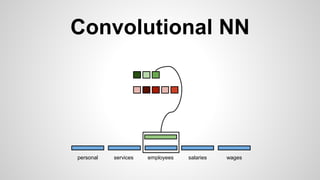

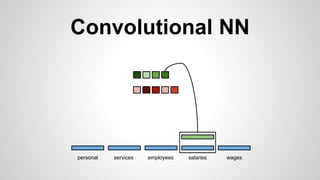

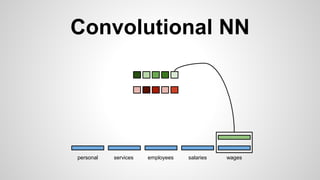


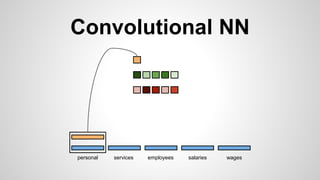

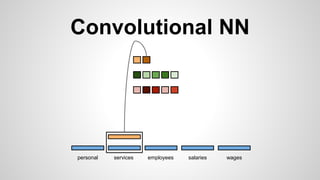
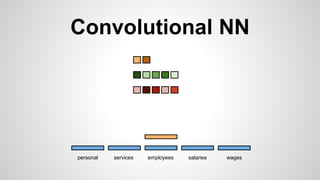
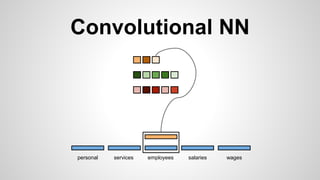
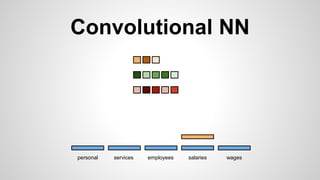
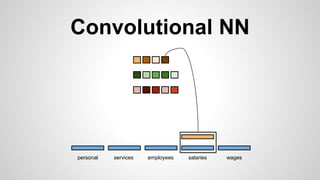
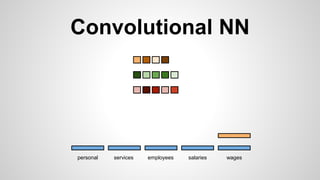
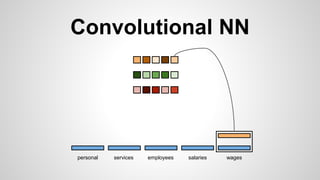


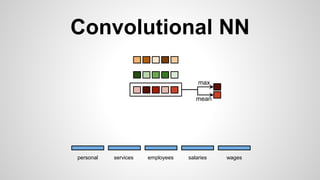
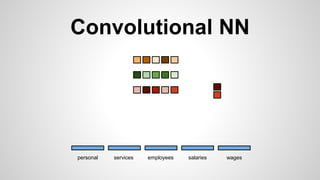
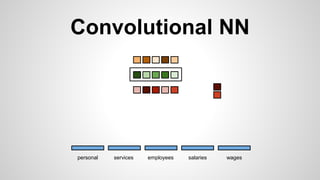
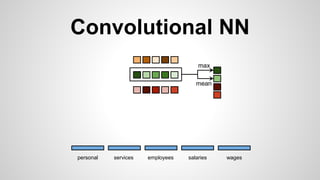

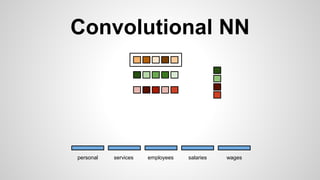
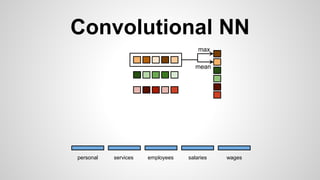




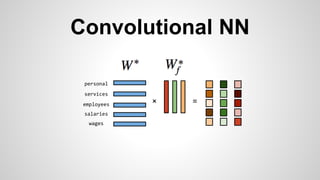
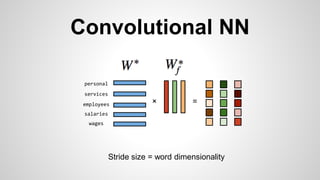












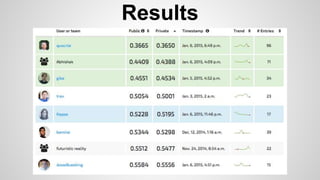


This document discusses different methods for creating word embeddings from text data, including bag-of-words, continuous bag-of-words, weighted continuous bag-of-words, and convolutional neural networks. Bag-of-words represents words as one-hot encodings but does not capture similarity between words. Continuous bag-of-words learns distributed word representations but treats all words equally. Weighted continuous bag-of-words aims to address this by learning word importance weights. Convolutional neural networks apply convolutions to word vectors to learn local contextual representations of words. These methods are evaluated on a text classification task, with convolutional neural networks achieving the best performance.















































