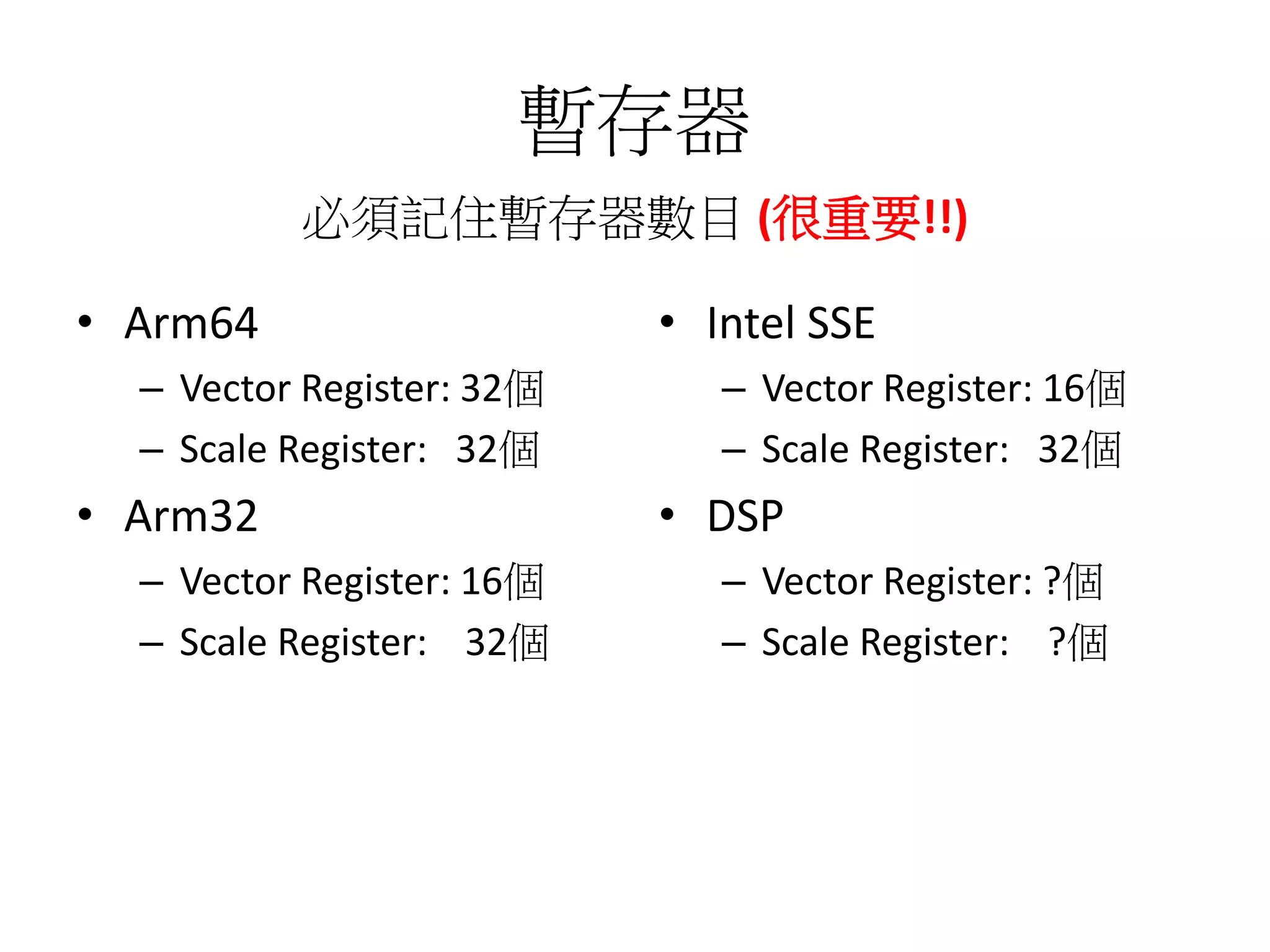
已知方法論
int arr0[100] ={1,2,3…};
void test1 (float *src,float *dst,int len)
{
int arr1[100] = {1,2,3…};
int b =4;
int *arr2 = (int *)malloc(100*sizeof(int));
int c = len + b;
…
}
Memory
L1 cache
Instruction set
Const
Memory
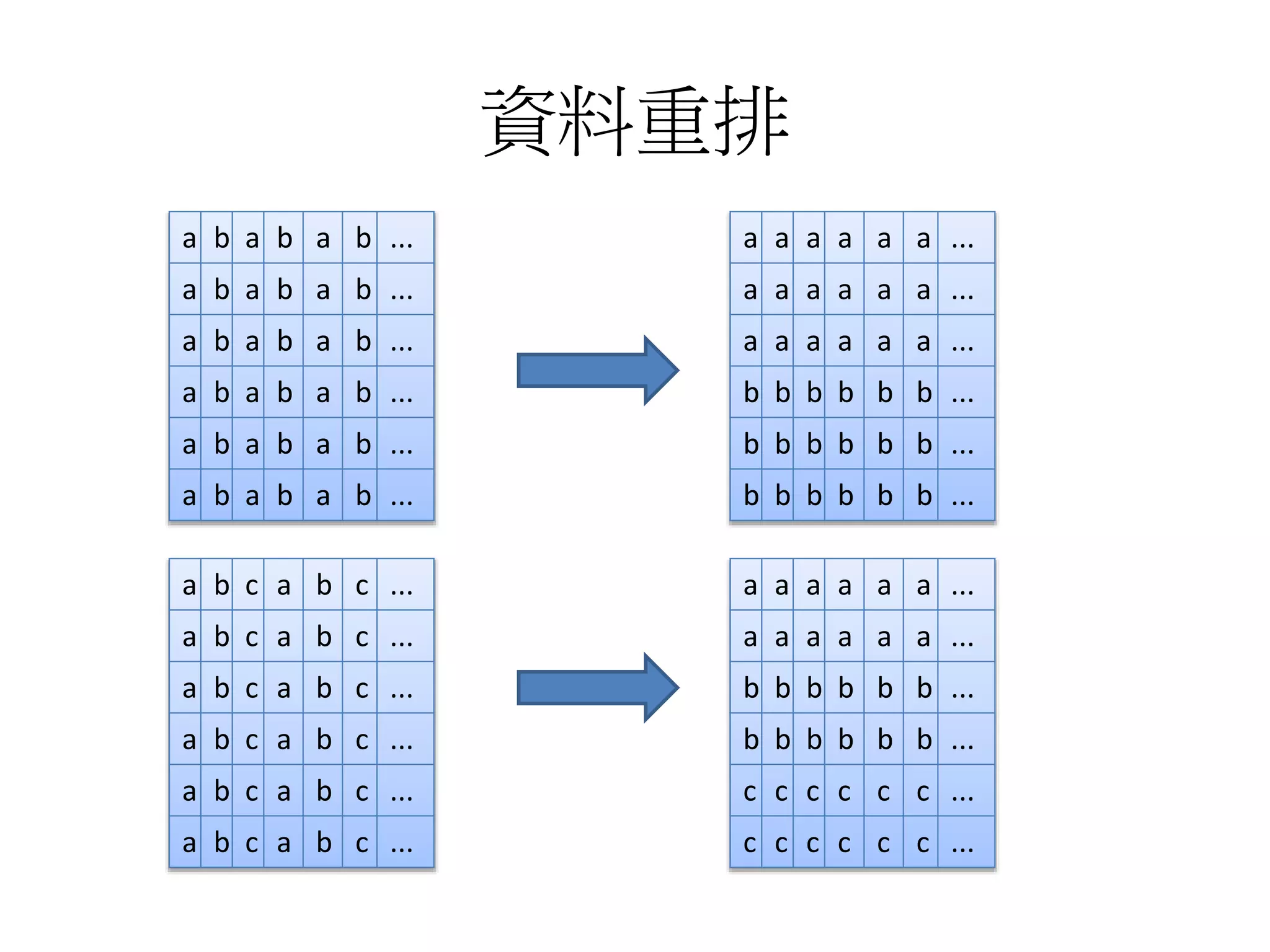
資料重排
a b ab a b ...
a b a b a b ...
a b a b a b ...
a b a b a b ...
a b a b a b ...
a b a b a b ...
a a a a a a ...
a a a a a a ...
a a a a a a ...
b b b b b b ...
b b b b b b ...
b b b b b b ...
a b c a b c ...
a b c a b c ...
a b c a b c ...
a b c a b c ...
a b c a b c ...
a b c a b c ...
a a a a a a ...
a a a a a a ...
b b b b b b ...
b b b b b b ...
c c c c c c ...
c c c c c c ...




![C=A+B ?
float arr0[4] = { 1,2,3,4 };
float arr1[4] = { 5,6,7,8 };
float arr2[4] = { 0 };
A
B
C
A BC +=
Result: arr2[4] => { 6,8,10,12 };](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-5-2048.jpg)
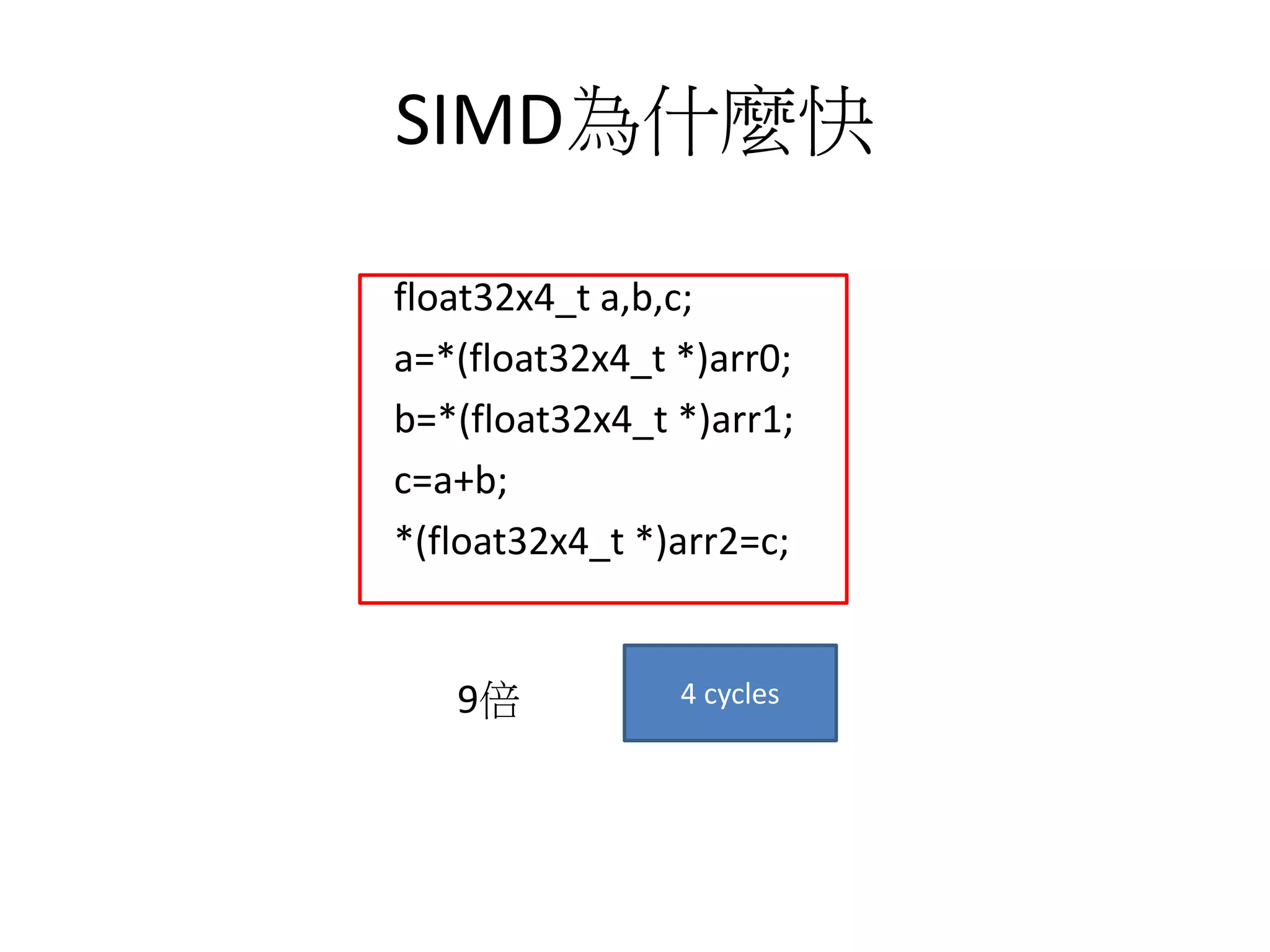
![SIMD為什麼快
for(int i=0;i<4;i++)
arr2[i]=arr0[i]+arr1[i];
for(int i=0;i<4;i++)
*(arr2 + i) = *(arr0 + i)+*(arr1 + i);
1 1*4
(1+1)*4 (1+1)*4 (1+1)*4
37 cycles
1*4
1*4
1. 假定一個指令一個cycle
2. address shift列入考量](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-6-2048.jpg)





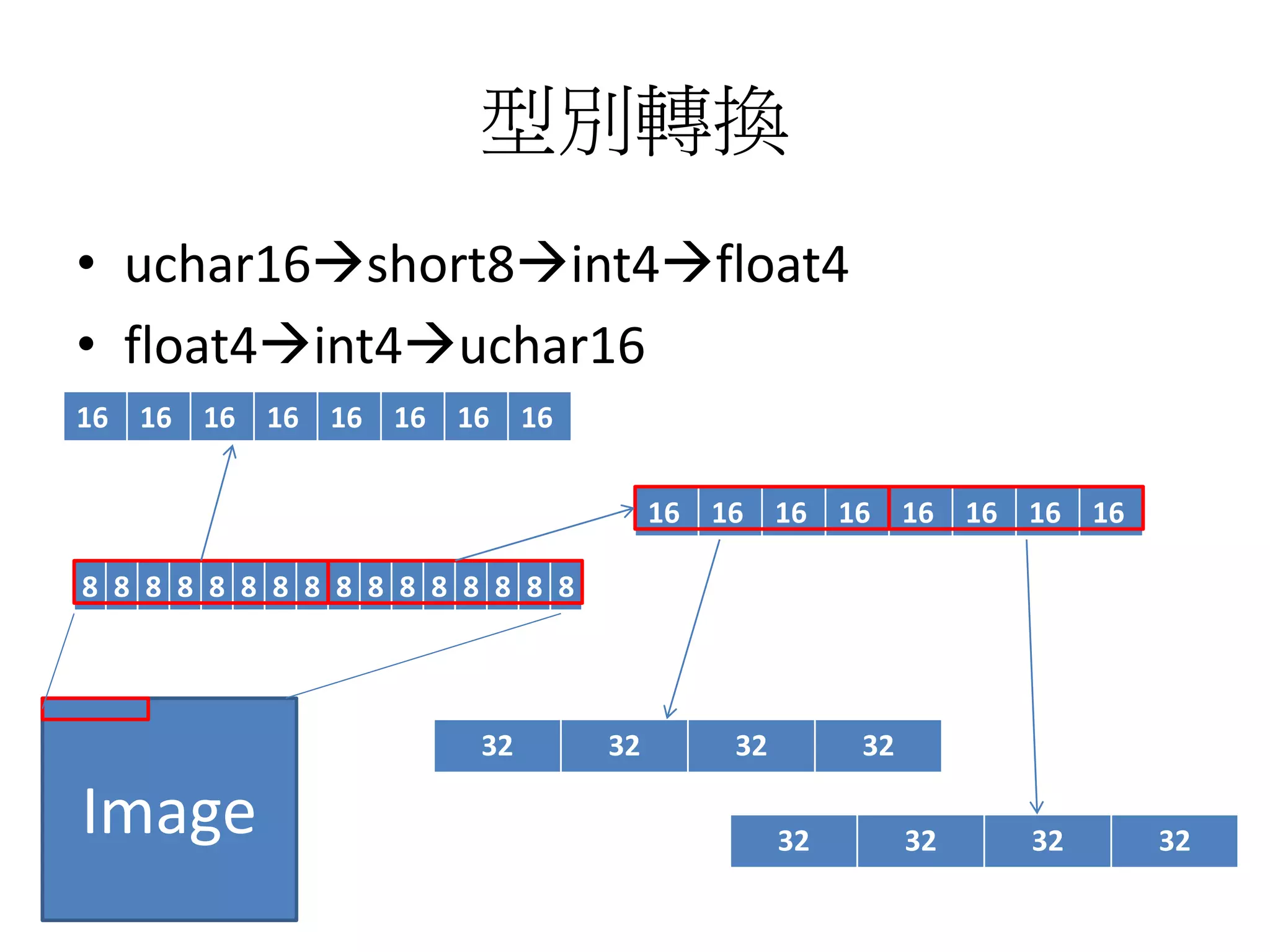
![重新定義暫存器
union reg128 {
uchar16 _uchar16;
short8 _short8;
int4 _int4;
float4 _float4;
double2 _double2;
uchar _uchar[16];
short _short[8];
int _int4;
float _float[4];
double _double[2];
…
void print_uchar()
{
printf(“%d %d..n”,
_uchar[0],_uchar[1],_uchar[2]….);
}
void print_float()
{
printf(“%f %f %f %fn”,
_float[0],_float[1]...);
}
…
};](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-13-2048.jpg)







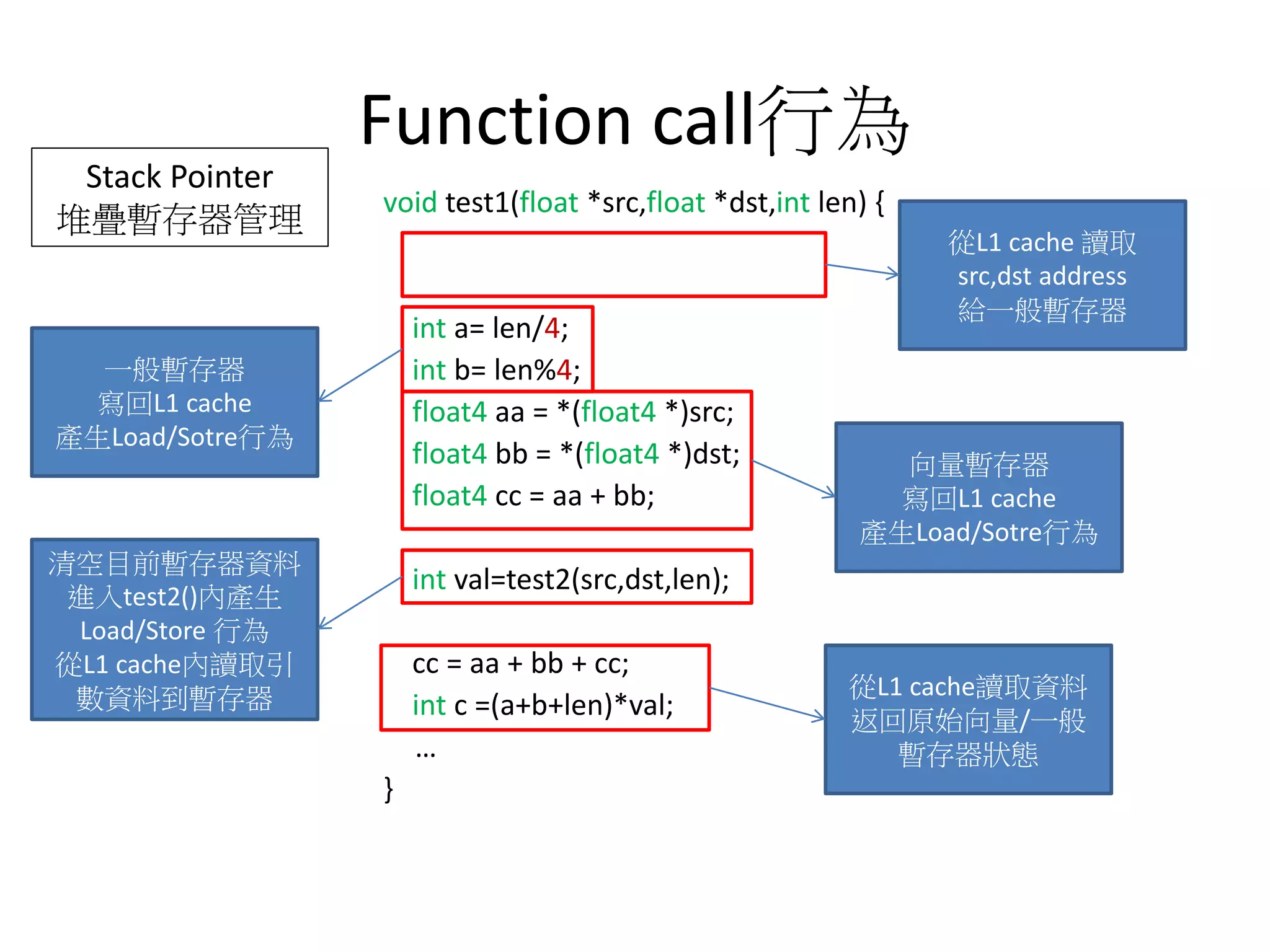
![已知方法論
int arr0[100] = {1,2,3…};
void test1 (float *src,float *dst,int len)
{
int arr1[100] = {1,2,3…};
int b =4;
int *arr2 = (int *)malloc(100*sizeof(int));
int c = len + b;
…
}
Memory
L1 cache
Instruction set
Const
Memory](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-23-2048.jpg)
![已知方法論
class a
{
int val = 3;
int map[100] = {1,2,3,4,5};
a();
…
};
Memory
同等於struct](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-24-2048.jpg)

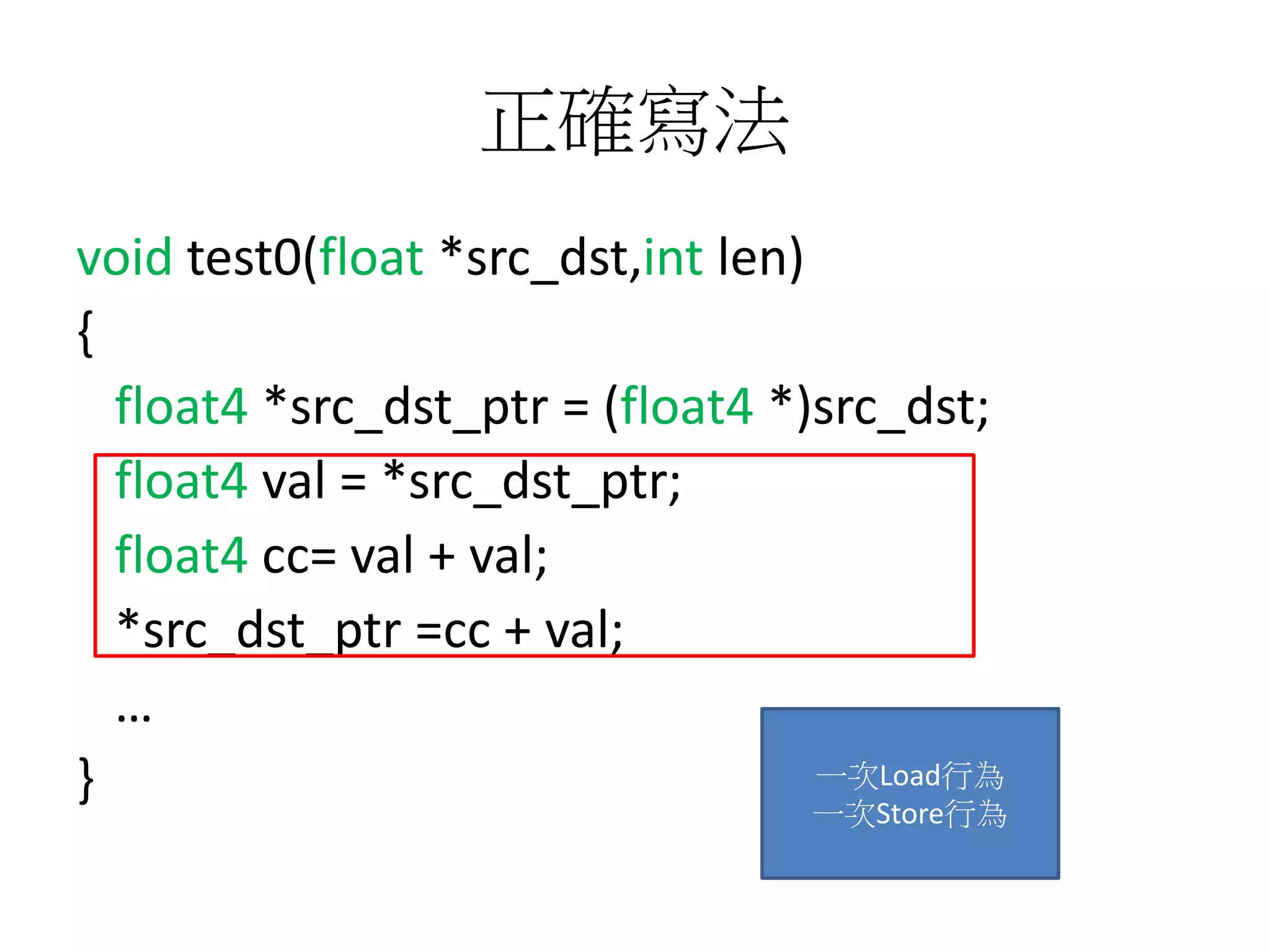
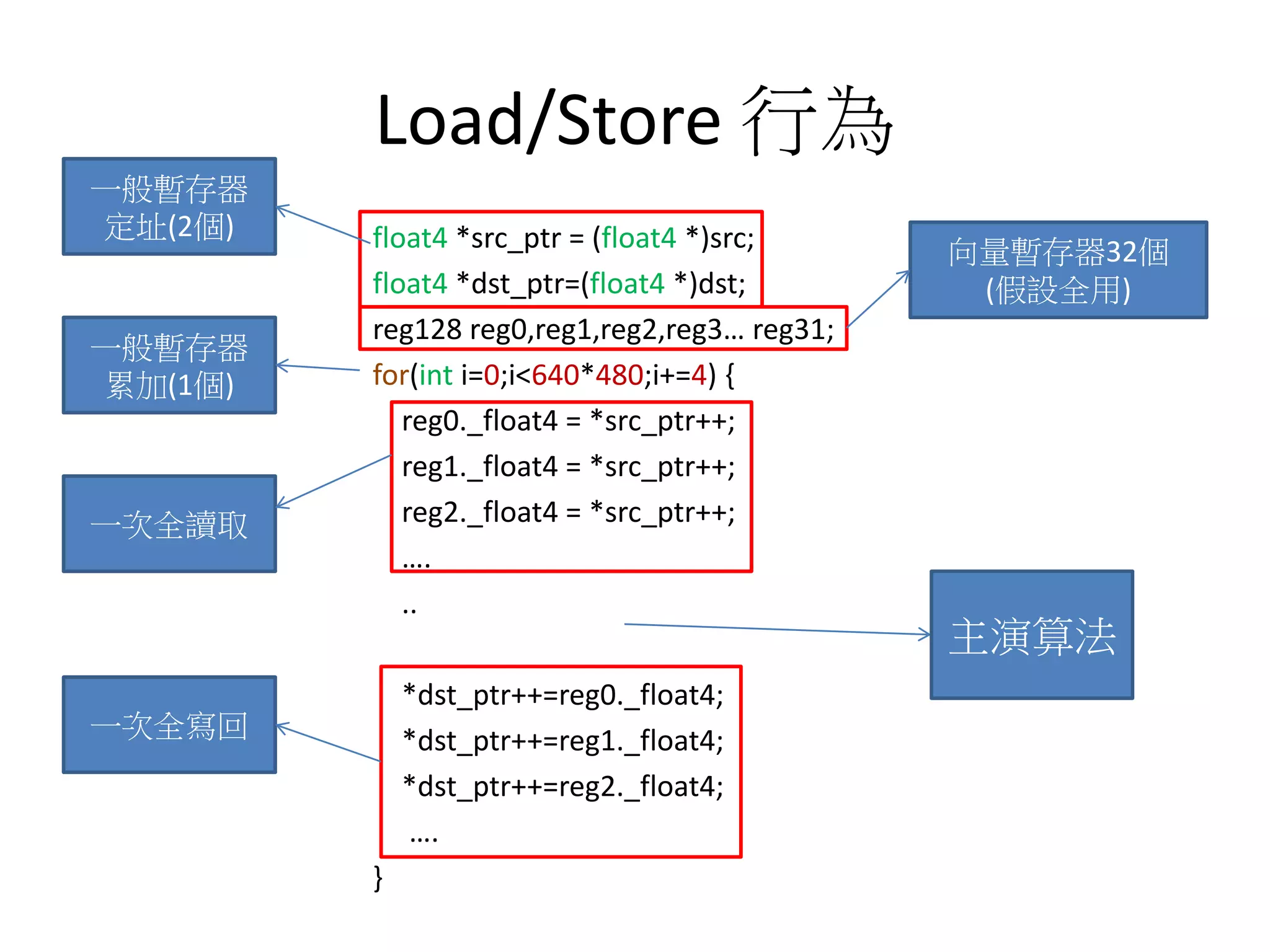
![少用陣列,多用pointer++
void test1(float *src,float *dst,int len)
{
float4 *src_ptr =(float4 *)src;
float4 *dst_ptr=(float4 *)dst;
float4 reg0,reg1…;
for(int i=0;i<len;i+=4)
{
reg0=*src_ptr++;
reg1=*src_ptr++;
reg0 = reg0+reg1;
…..
*dst_ptr++=reg0;
*dst_ptr++=reg1;
}
}
• 不建議使用
void test2(float4 *src,float4 *dst,int len)
{
int len_4 = len/4;
float4 reg0,reg1…;
for(int i=0;i<len_4;i+=2)
{
reg0=src[i]+src[i+1];
…
dst[i]=reg0;
dst[i+1]=src[i+1];
}
}](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-27-2048.jpg)


![解決方法
• 選擇內建指令(unalign)
• 對齊load/store,利用alignr or vext組裝
• malloc or 宣告陣列用16位對齊
32 32 32 32 32 32 32 32
reg0
reg3=vext(reg0,reg1,1)
reg1
float __attribute__ ((aligned (16))) a[40];
float *b=(float *)malloc(sizeof(float)*40);
b= (float*)(((unsigned long)b + 15) & (~0x0F))](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-30-2048.jpg)

![Why
• 假設全float的前提下arm64 vector可提供
– 128個空間大小模擬陣列(4*32)
– 完全不用寫回記憶體的極限操作
• 配合shuffle使用
– 若同時使用超過32個變數,多的資料會寫回L1
cache,造成延遲
float arr[4*32+4] = {…};
float4 *arr_ptr = (float4 *)arr;
float4 a0,a1,a2,a3,a4,a5,a6 … a32;
A0 = *arr_ptr++;
A1= *arr_ptr++;
…
A32 = *arr_ptr++;
超過32個暫存器變數同時使用,
運算過程中會產生額外的
Load/Store 行為,無法被優化](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-33-2048.jpg)



![分支指令行為
float a[100],b[100];
for(int i=0;i<100;i++)
{
if(a[i]<50)
b[i]=a[i];
else
b[i] = 30;
}
1 100 100
(1+1+1)*100
(1+1)*100*2
(1+1)*100
1101 cycles](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-39-2048.jpg)

![解析SIMD分支
float4 cmp = {50,50,50,50};
reg128 val0;
reg128 reg0,mask,tmp0,tmp1;
val0._float4 = { 30,30,30,30 };
for(int i=0;i<100;i+=4)
{
reg0._float4 = *a_ptr++;
mask._uint4=vcltq_f32(reg0._float4,cmp);
tmp0._uint4=vandq_u32(reg0._uint4,mask._uint4);
mask.uint4 = vnotq_u32(mask);
tmp1._uint4=vandq_u32(val0._uint4,mask._uint4);
reg0._uint4=vxor_u32(temp0._uint4,temp1._uint4);
*b_ptr++ = reg0._uint4;
}
if(a[i]<50) b[i]=a[i];
else b[i] =30;
11..1 00..0 11..1 00..0
If true
32個1
If false
32個0
0 128
0000 1111
0011 0100
0000 0100
AND
1111 0000
1011 0001
101 1 0000
NOT
AND
1011 0000
0000 0100
101 1 0100
XOR](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-41-2048.jpg)


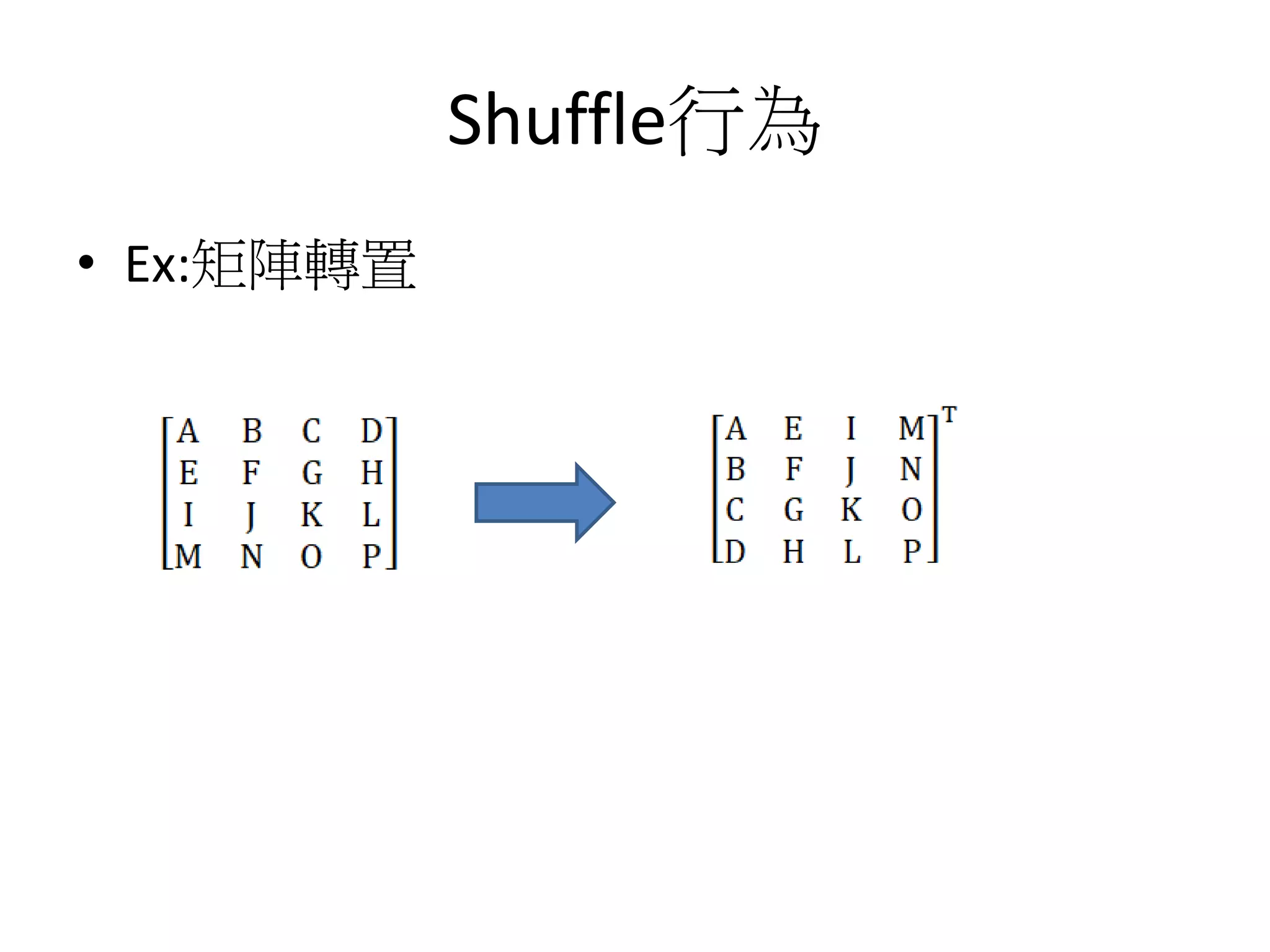
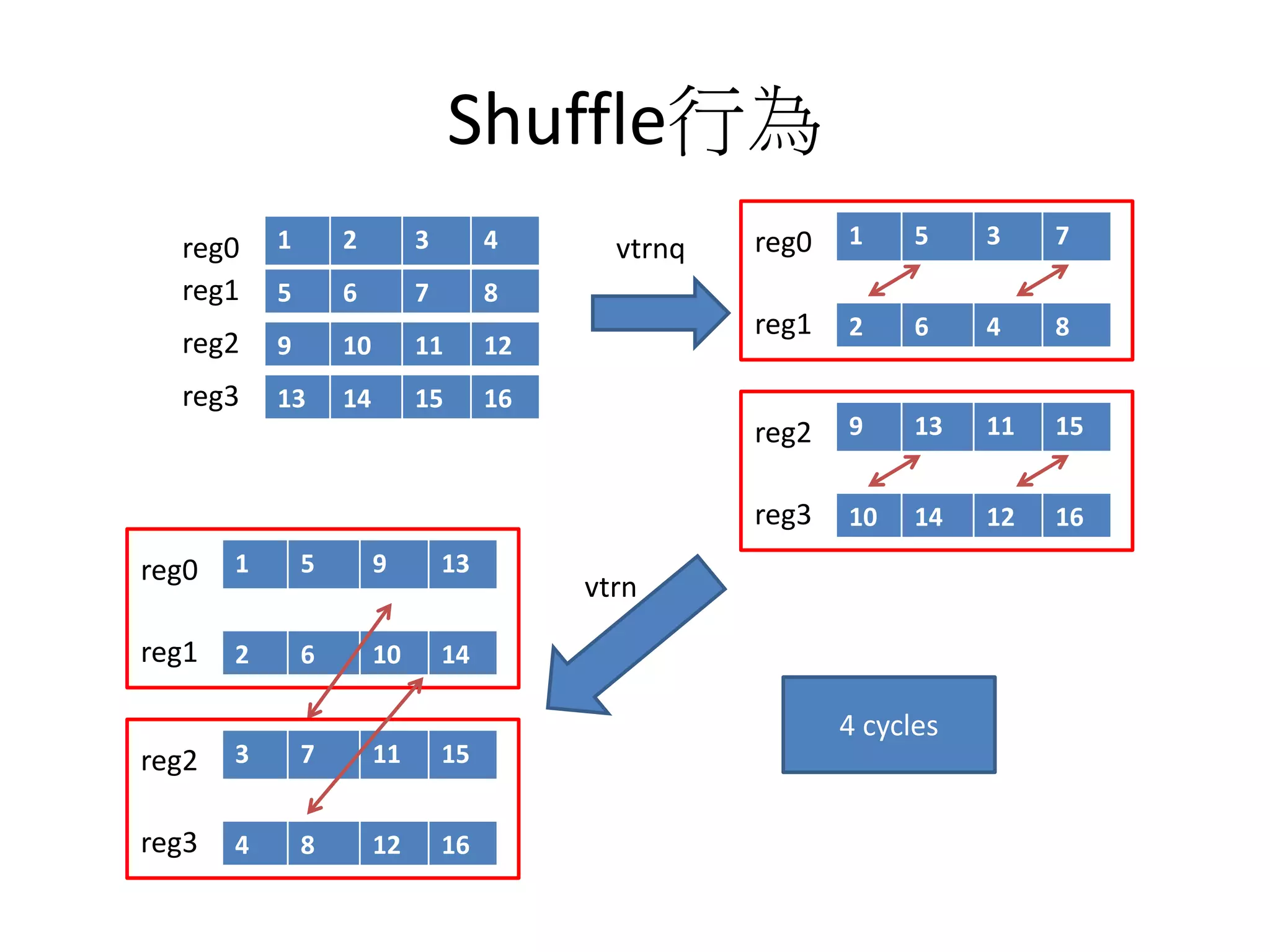
![Shuffle行為
for(int i=0;i<4;i++)
for(int j=i;j<4;j++)
{
int index0=i*4+j,index1=j*4+i;
float temp=a[index0];
a[index0]=a[index1];
a[index1]=temp;
}
(4+3+2+1)*3
4 41
(1+1)*10
(1+1)*10
(1+1)*10*2
159 cycles
(1+1+1+1)*10](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-46-2048.jpg)
![Shuffle行為
reg256 temp0,temp1;
reg128 reg0,reg1,reg2,reg3;
temp0._float4x2=vtrnq_f32(reg0._float4,reg1._float4);
temp1._float4x2=vtrnq_f32(reg2._float4,reg3._float4);
float2 temp =temp0._float2[1];
temp0._float2[1]=temp1._float2[0];
temp1._float2[0]=temp;
temp=temp0._float2[3];
temp0._float2[3]=temp1._float[2];
temp1._float[2]=temp;
4 cycles
vtrn
vtrn
39.75倍](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-47-2048.jpg)
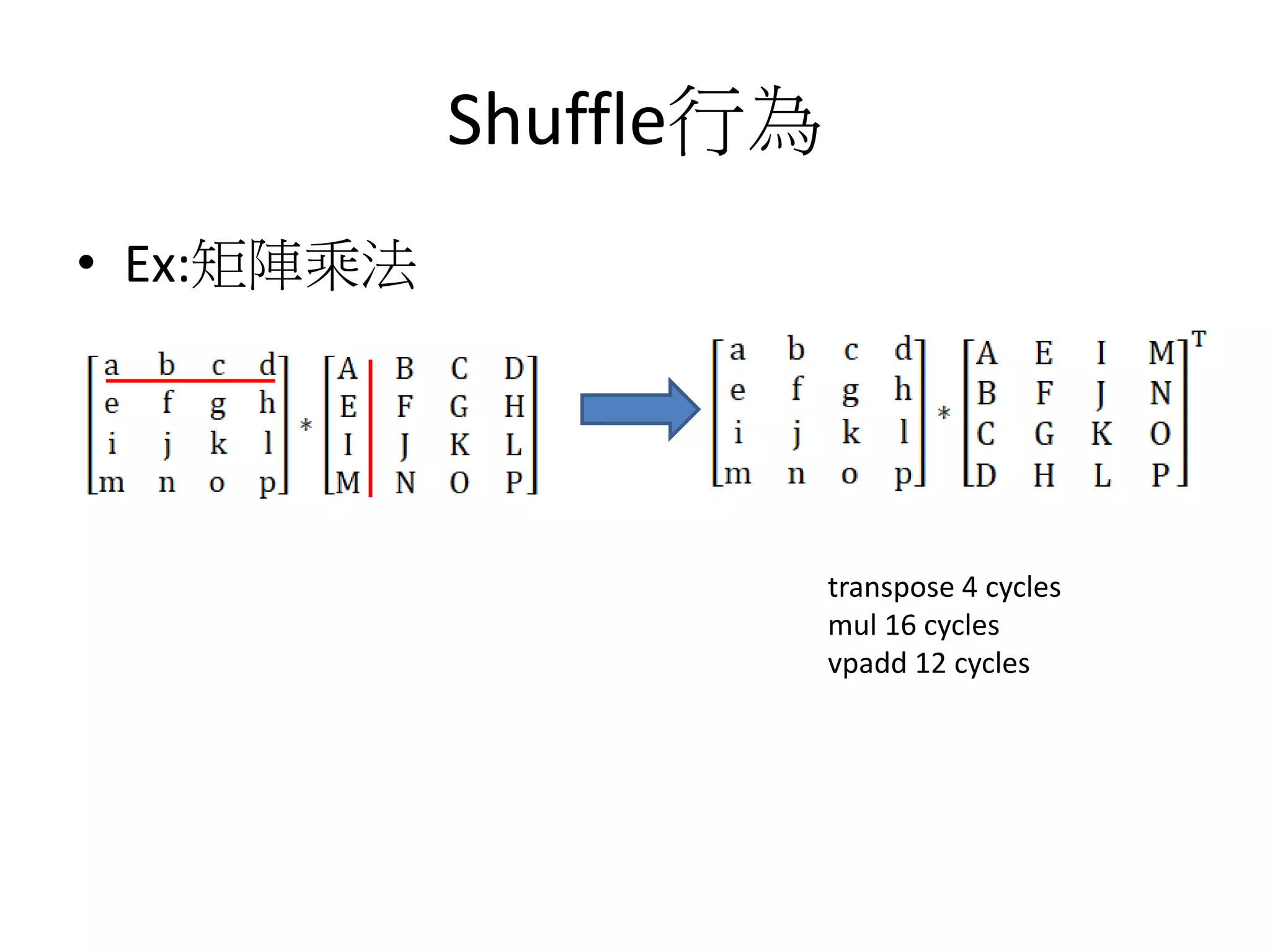





![提取元素及寫回
reg128 reg0;
float4 a= {0,1,2,3};
reg0._float4 = a;
float2 val1= reg0._float2[0];
reg0._float2[1]=val1;
float val0=reg0._float[2];
reg0._float[3] = val0;
1. 指令是否支援,沒支援,寫入L1 Load/Store被當陣列用
2. 要看編譯器聰不聰明!!
0 1 2 3
寫
讀
讀
寫
寫](https://image.slidesharecdn.com/simd-180811140223/75/SIMD-55-2048.jpg)

























![Memory access tracing [poug17]](https://cdn.slidesharecdn.com/ss_thumbnails/memoryaccesstracingpoug17-170904121053-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Pgday.Seoul 2017] 7. PostgreSQL DB Tuning 기업사례 - 송춘자](https://cdn.slidesharecdn.com/ss_thumbnails/cjsongpostgresqldbtuningexam-20171102-171106043044-thumbnail.jpg?width=640&height=640&fit=bounds)













![[科科營]電腦概述](https://cdn.slidesharecdn.com/ss_thumbnails/coursecomputer-130707071458-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






