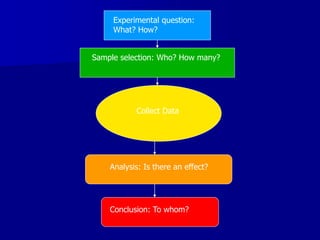
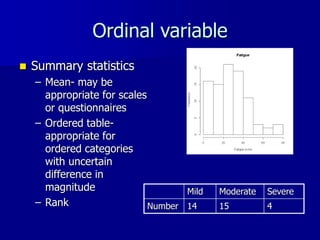
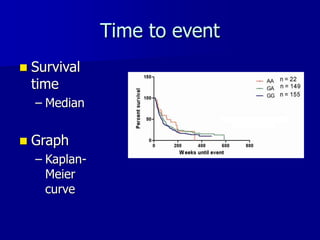
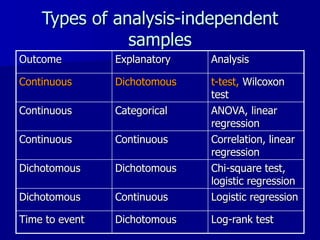
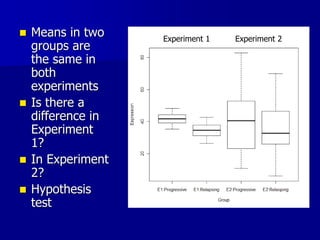
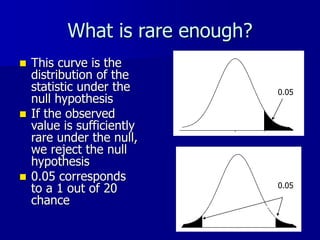
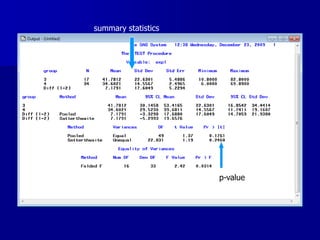
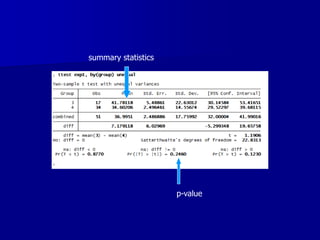
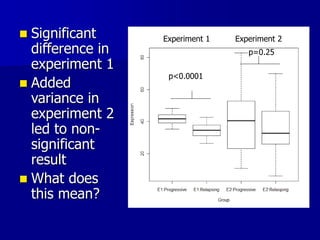
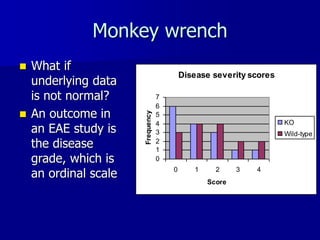
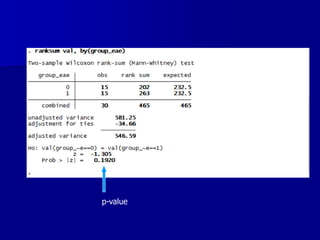
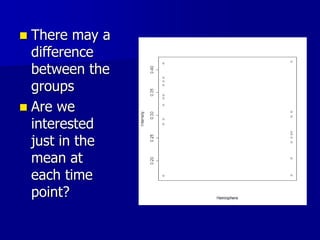
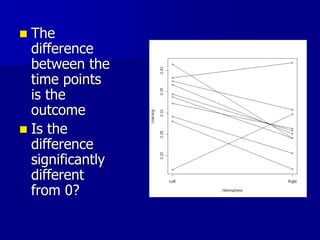
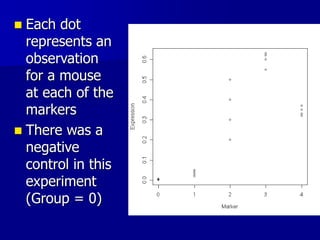
This document provides an introduction to concepts in biostatistics and hypothesis testing. It outlines the objectives of learning about study design, types of data, hypothesis testing, p-values, and choosing appropriate statistical tests. It also describes office hours, topics beyond the scope of the class, and objectives for learning about stages of research studies, hypothesis tests, t-tests, and Wilcoxon tests.