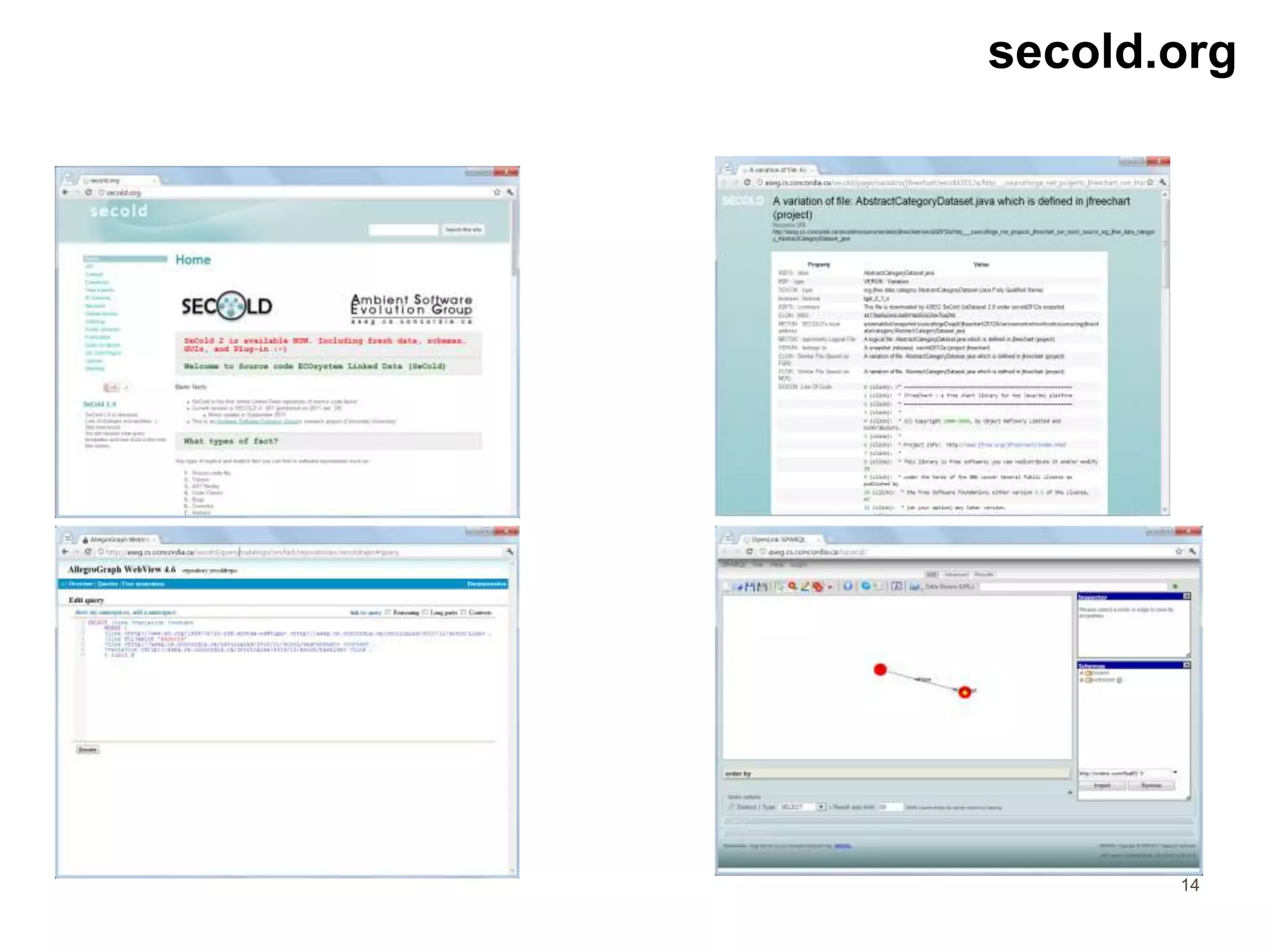
Secold is a linked data platform designed to mine software repositories, aggregating information from over 1,000,000 open source projects. Its primary goals include establishing a foundational framework and conducting data analyses, with ongoing iterations aimed at enhancing the project. The platform enables the sharing of vast amounts of structured data, providing functionalities such as copyright detection and statistical analysis within the software ecosystem.


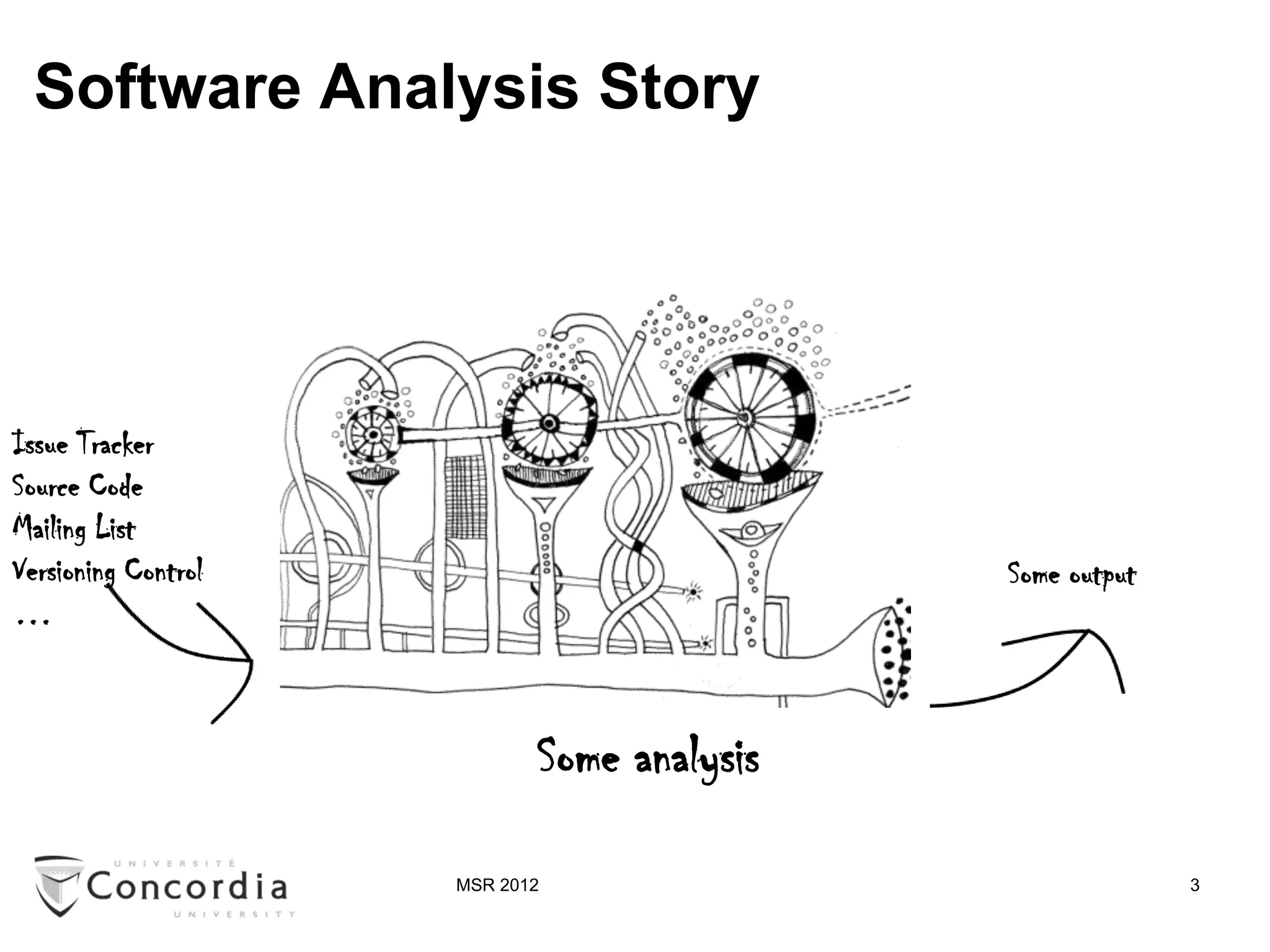
![Software Analysis Story
Issue Tracker
Source Code
Mailing List
Versioning Control Some output
…
Structured
Extraction Internal Data
Process Analysis Process
Raw Representation Structured
Data Output
[Source Code Analysis: A Roadmap, FOSE’07]
MSR 2012 4](https://image.slidesharecdn.com/msr2012public-noanimation-120618120345-phpapp01/75/SeCold-A-Linked-Data-Platform-for-Mining-Software-Repositories-4-2048.jpg)
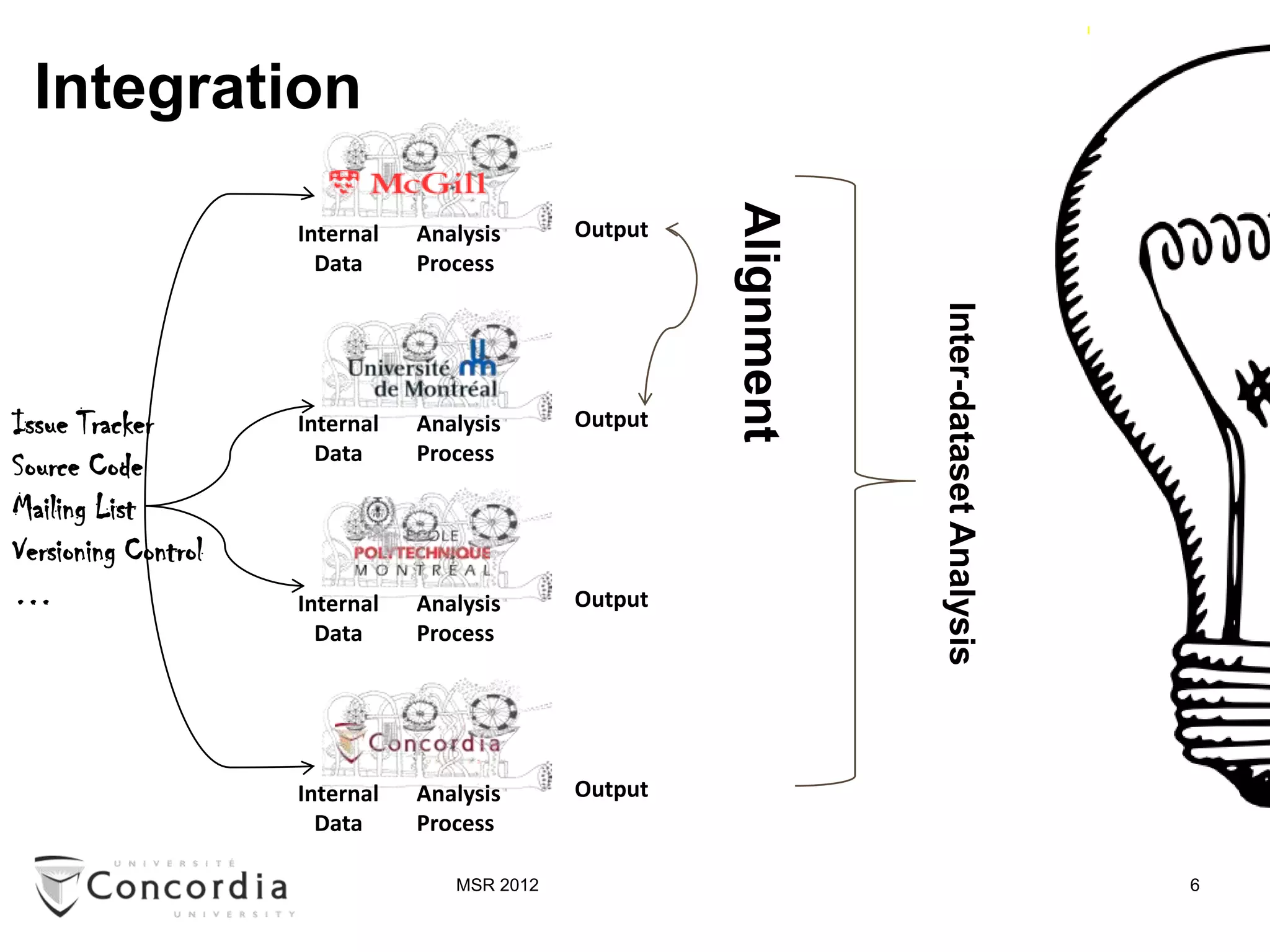
![Issue Tracker
Source Code
Mailing List
Versioning Control
…
Sharing
[Source code analysis: a roadmap, FOSE’07]
[Fostering synergies: how … ICSE-SUITE’10]
MSR 2012 5](https://image.slidesharecdn.com/msr2012public-noanimation-120618120345-phpapp01/75/SeCold-A-Linked-Data-Platform-for-Mining-Software-Repositories-5-2048.jpg)





![SeCold
LinkedData Cloud (LOD)
SeCold:
Among the 9 largest
Media datasets in the cloud
Publication
Triple
Circle size
count
Government Very large >1B
Large 1B-10M
Medium 10M-500k
Small 500k-10k
Life Science Very small <10k
[Linking Open Data cloud diagram, by Richard Cyganiak and Anja Jentzsch. http://lod-cloud.net/, as of Sept 2011]
MSR 2012 13](https://image.slidesharecdn.com/msr2012public-noanimation-120618120345-phpapp01/75/SeCold-A-Linked-Data-Platform-for-Mining-Software-Repositories-13-2048.jpg)
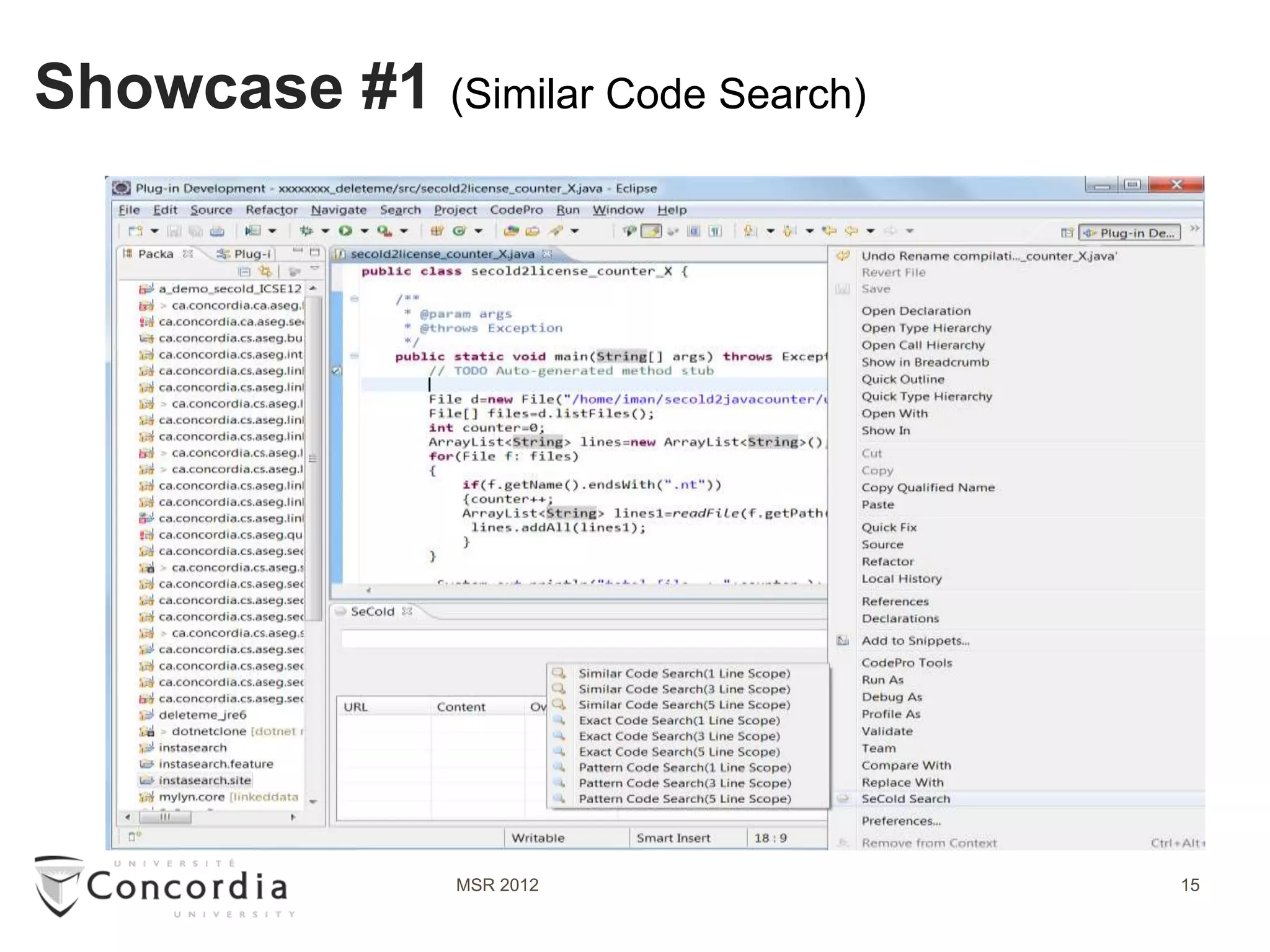
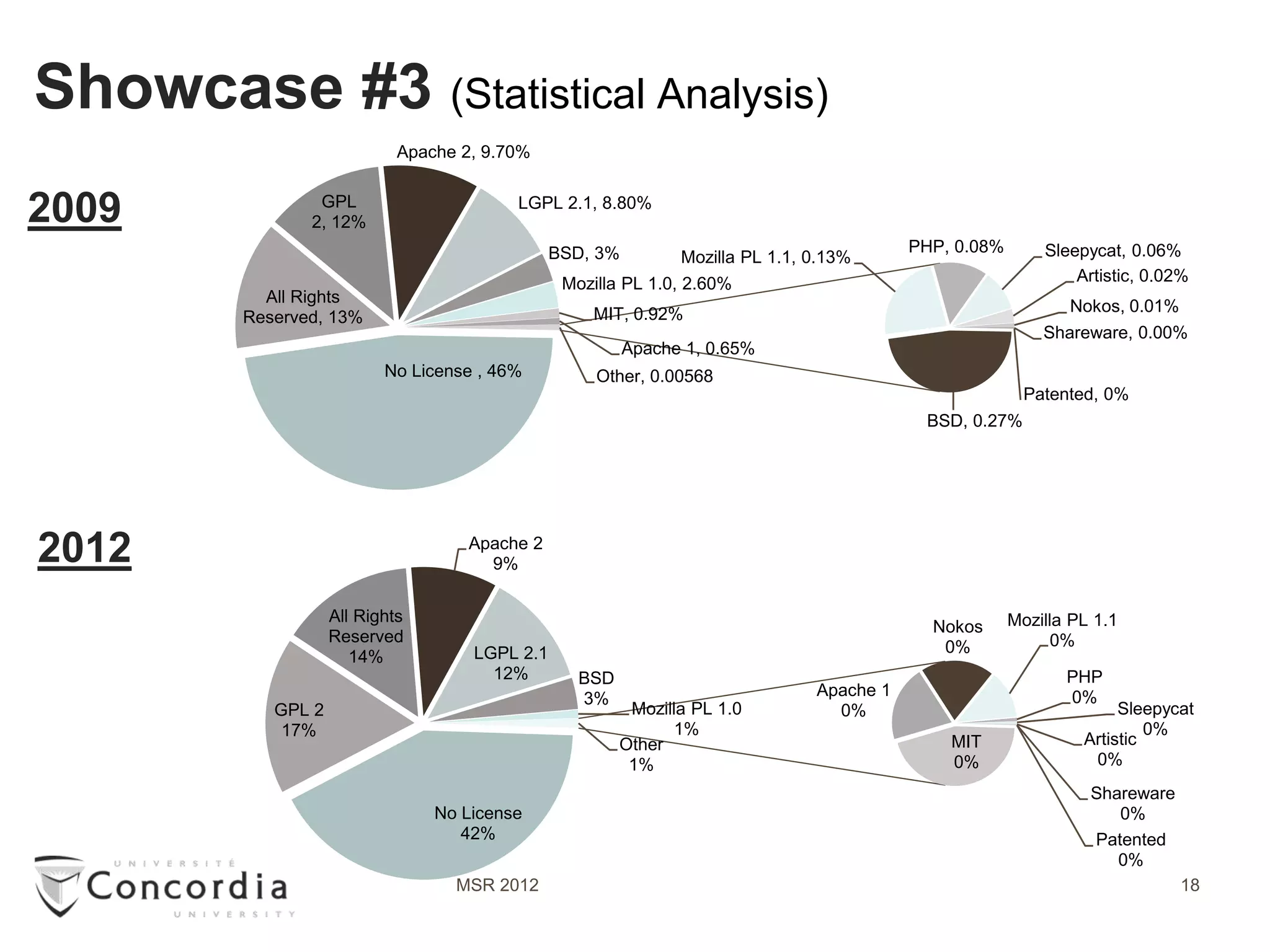
![Showcase #2 –Part1 (Copyright violation detection)
Se Clone [SeClone … ICPC’11& WCRE’11]
Line level fingerprints
Clone (Type 1,2 and 3)
Internal Analysis Output
Data Process
Source Code of
25K projects Upload
Ninka [A sentence-matching …, ASE’10]
License per file
Internal Analysis Output
Data Process
MSR 2012 16](https://image.slidesharecdn.com/msr2012public-noanimation-120618120345-phpapp01/75/SeCold-A-Linked-Data-Platform-for-Mining-Software-Repositories-16-2048.jpg)
![Showcase #2 –Part2 (Copyright violation detection)
e … ICPC’11& WCRE’11]
Line level fingerprints
Clone (Type 1,2 and 3)
s Output
Copyright violation detection:
select ?fileA ?fileB where {
Upload ?fileA testxi ?fingerprint .
?fileB testxi ? fingerprint .
?fileA hasLicense ?la .
?fileB hasLicense ?lb .
-matching …, ASE’10]
Filter (?la != ?lb) }
License per file
Output
MSR 2012 17](https://image.slidesharecdn.com/msr2012public-noanimation-120618120345-phpapp01/75/SeCold-A-Linked-Data-Platform-for-Mining-Software-Repositories-17-2048.jpg)