Download to read offline


![Amélie Marian – Rutgers University09/30/2013
2
Forum Popularity and Search
• Forums with most traffic
[http://rankings.big-boards.com]
- BMW
- 50K uniq visitors/day
- 25M Posts
- 0.6M Members
- Filipino Community
- Subaru Impreza Owners
- Rome Total War
- …
- Pakistan Cricket Fan Site
- Prison Talk
- Online Money making
Despite popularity,
forums lack good
search capabilities](https://image.slidesharecdn.com/webdonesept2013ss-130930044108-phpapp02/85/Searching-Web-Forums-2-320.jpg)
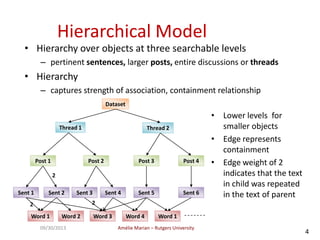


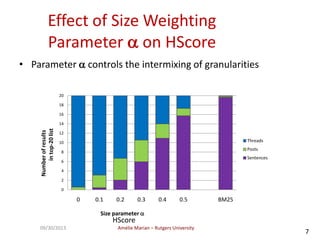



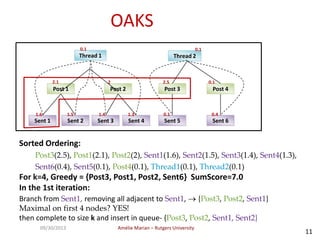





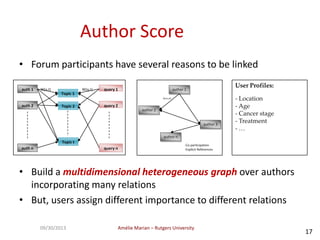

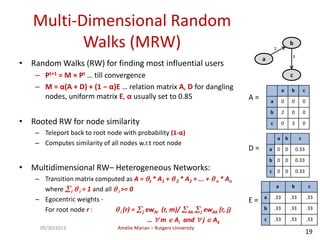

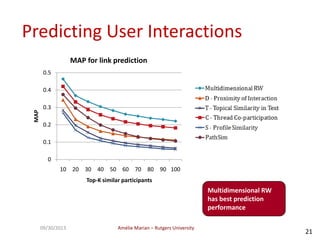





The document discusses searching web forums and summarizing forum content at different granularity levels. It proposes a hierarchical model to represent forum structure with threads, posts, and sentences at different levels. It also describes algorithms like OAKS to generate optimal non-overlapping result sets by maximizing quality scores across levels. Evaluation shows the mixed-granularity approach outperforms methods using only posts in terms of perceived relevance of results for queries. The document also discusses enhancing search using authorship information through multi-dimensional random walks to compute author scores.
































![CASE_PRESENTATION_ON_subdural_hematoma(SDH)[1 FINAL PPT]-1.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/casepresentationonsubduralhematomasdh1finalppt-1-260129172522-d405d375-thumbnail.jpg?width=640&height=640&fit=bounds)


















