Download to read offline








![10
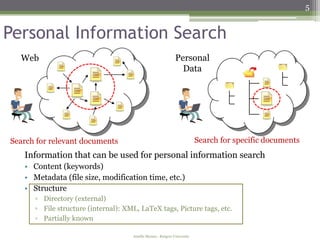
Unified Structure and Content
Target file: Halloween party pictures taken at home where someone
wears a witch costume
//Home[.//“Halloween” and .//“witch”]
File
root
Boundary
Home
“Halloween” “witch”
Amélie Marian - Rutgers University](https://image.slidesharecdn.com/searchingdatawithsubstanceandstyleslideshare-121019091900-phpapp02/85/Searching-data-with-substance-and-style-10-320.jpg)






![21
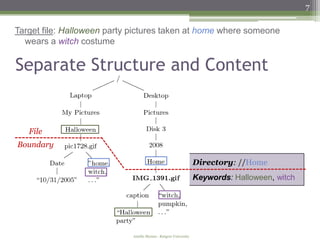
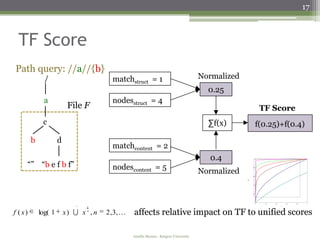
Case Study
▫ Search for a witch costume picture taken at home on Halloween
Target: IMG_1391.gif (tagged with “witch” and “Halloween”)
Query Query Condition Comment Rank
Type
U //home[.//”witch” and Accurate condition 1
.//”halloween”]
U //halloween/witch/”home” Structure / content switched 1
C {witch, halloween} Accurate condition 20
C:D {witch, halloween} : {home} Accurate condition 1
C:D {witch, home} : {halloween} Structure / content switched 245-
252
Amélie Marian - Rutgers University](https://image.slidesharecdn.com/searchingdatawithsubstanceandstyleslideshare-121019091900-phpapp02/85/Searching-data-with-substance-and-style-21-320.jpg)







![32
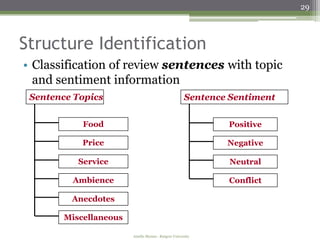
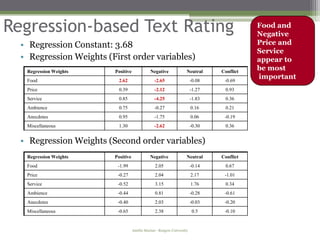
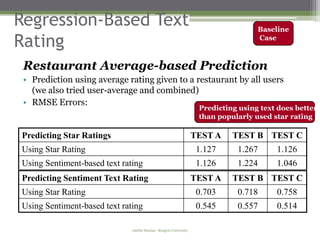
Regression-based Text Rating
• Use text of reviews to generate a rating
• Different categories and sentiment should have different
importance in the rating
Method
• We use multivariate quadratic regression
• Each normalized sentence type [(category, sentiment)] is
a variable in the regression
• Dependent variable is metadata star-rating
• Used training sets to learn the weights for each sentence
type; weights are used in computing text-based score
Amélie Marian - Rutgers University](https://image.slidesharecdn.com/searchingdatawithsubstanceandstyleslideshare-121019091900-phpapp02/85/Searching-data-with-substance-and-style-32-320.jpg)




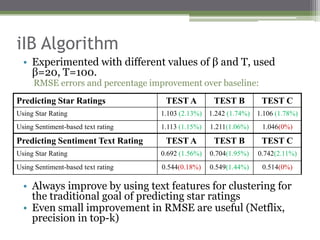








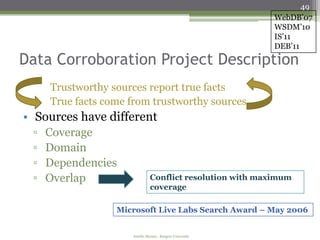
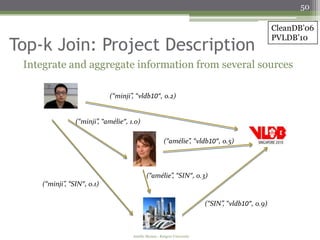




The document discusses semi-structured data processing and personal information search. It describes research at Rutgers University on developing tools for searching semi-structured data that unifies content and structure. The research aims to allow queries to contain both structural and content components and return results even if queries are incomplete. It proposes approaches like defining a unified data model, query relaxations to approximate queries, and scoring frameworks to rank unified search results.






















































