Downloaded 11 times









![mlflow.set_tracking_uri(self.sagemaker_configs["mlflow_host"])
mlflow.create_experiment(experiment_name)
mlflow.start_run(experiment_id=experiment_id)
mlflow.log_param(key=k, value=quant_hyper_params[k])
mlflow.log_artifact(output + ".bin")
mlflow.log_metric("precision{}".format(metric_type), prec_score)
mlflow.set_tag("promote", "true")
Training module code snippets](https://image.slidesharecdn.com/mlflowaspartofyourmlcicd-190916055754/75/MLFlow-as-part-of-ML-CI-CD-at-Avalara-11-2048.jpg)



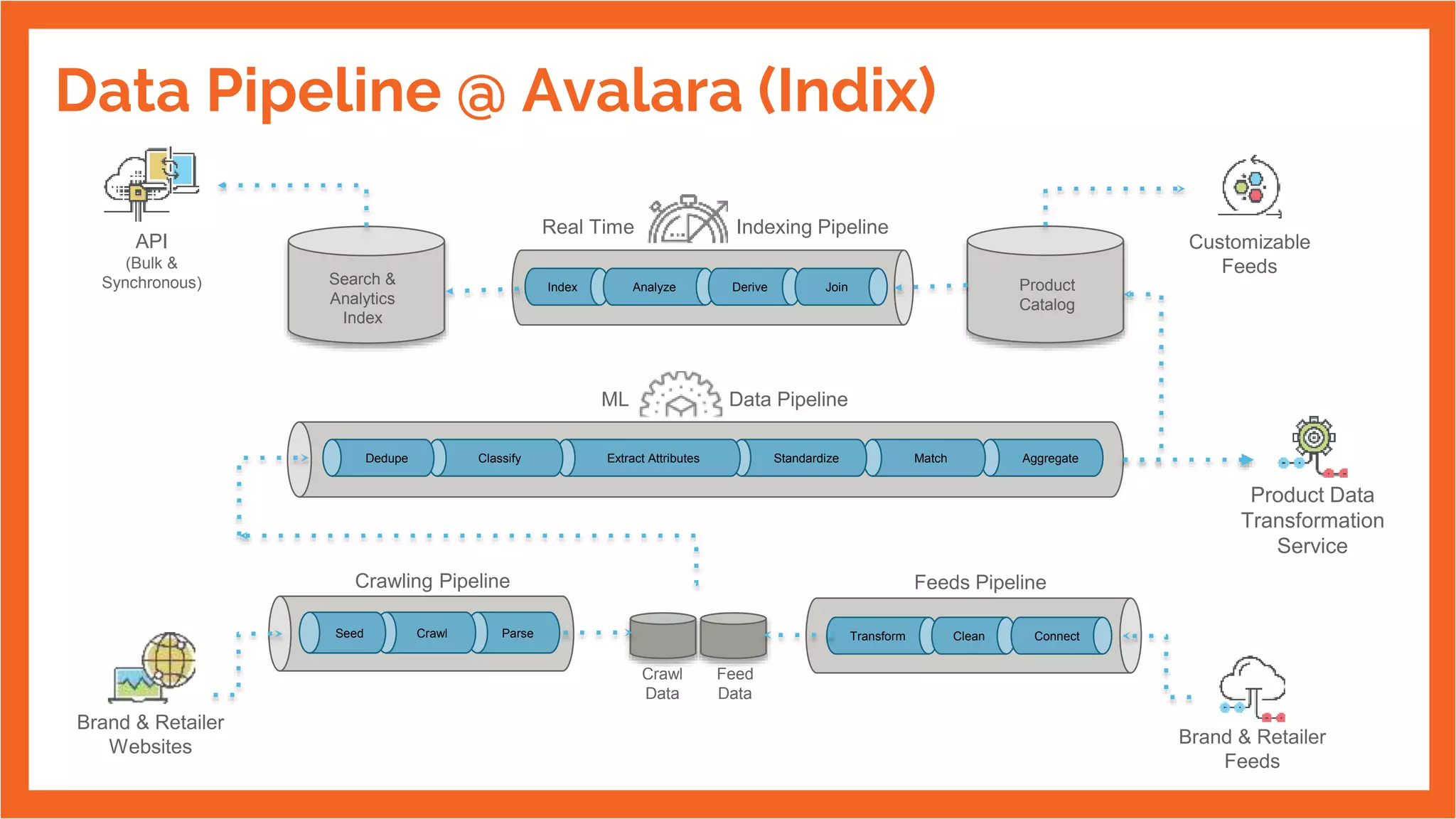
The document discusses the integration of MLflow into the CI/CD workflow at Avalara, highlighting its capabilities in managing machine learning models and data pipelines. It details the scales of data being processed and the various components involved in the machine learning lifecycle, including data transformation, model training, and deployment. Additionally, it mentions the open-source plugin connecting MLflow with GoCD for improved CI/CD processes.



















![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)















































