Download to read offline

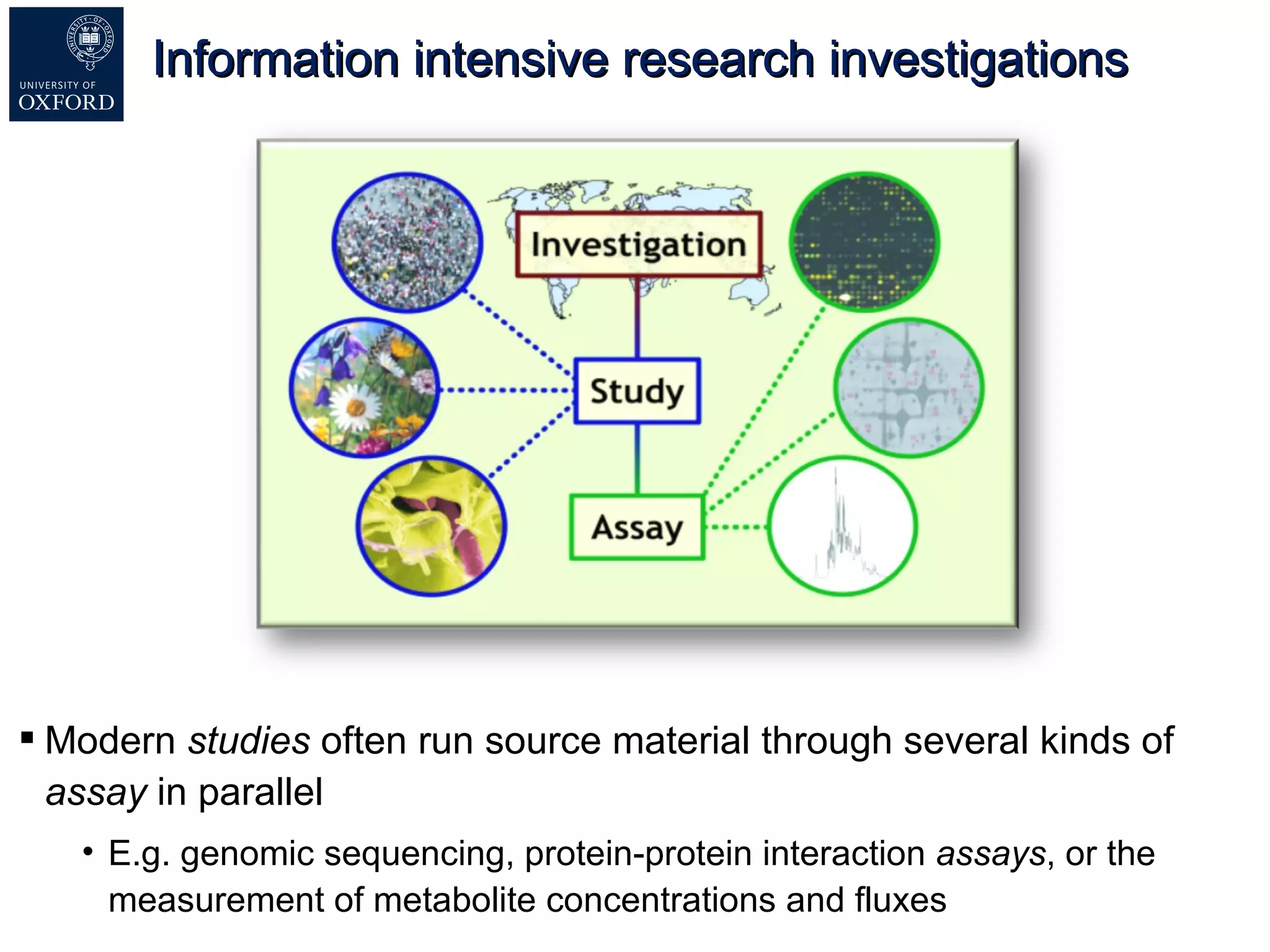
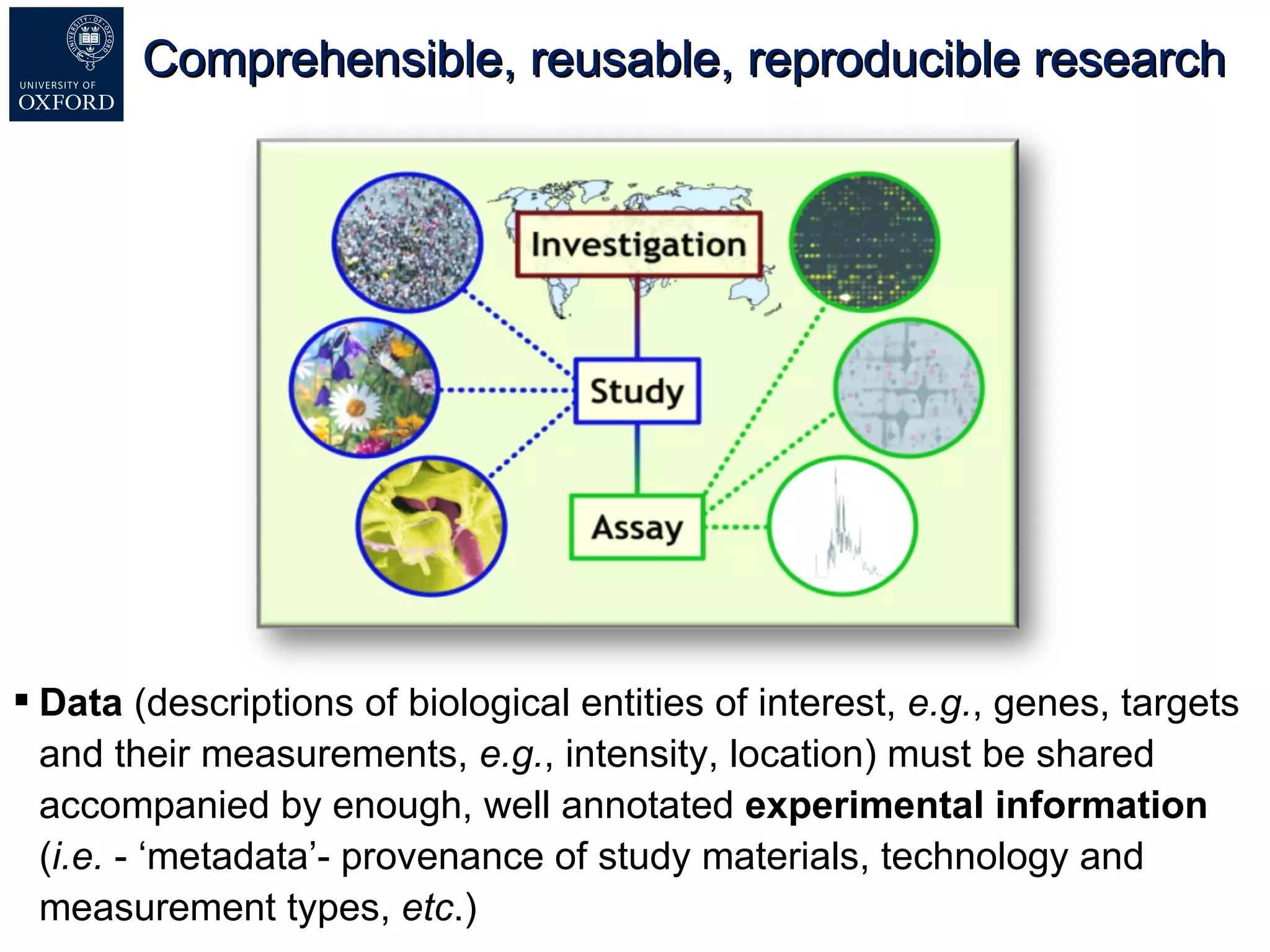






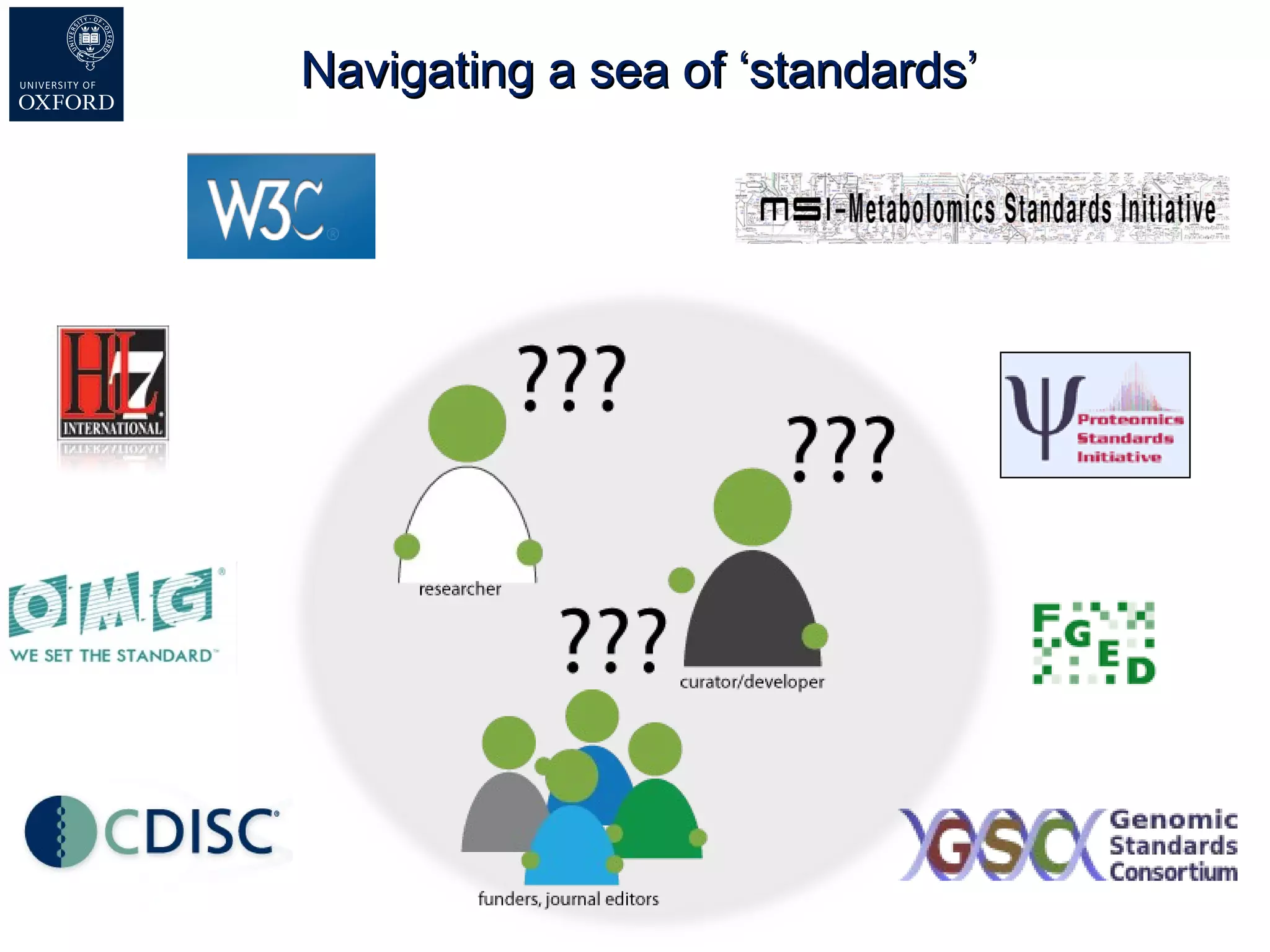
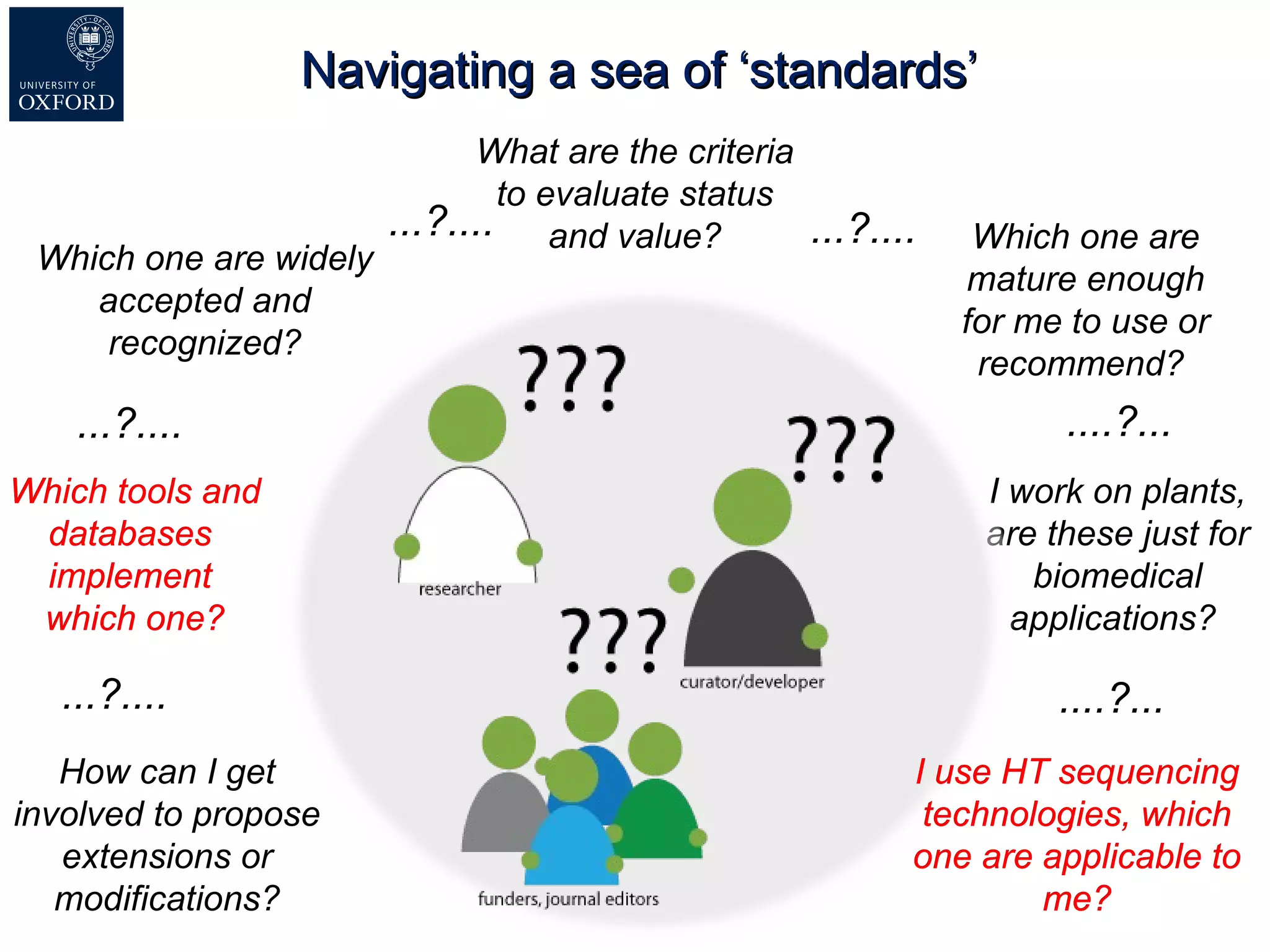
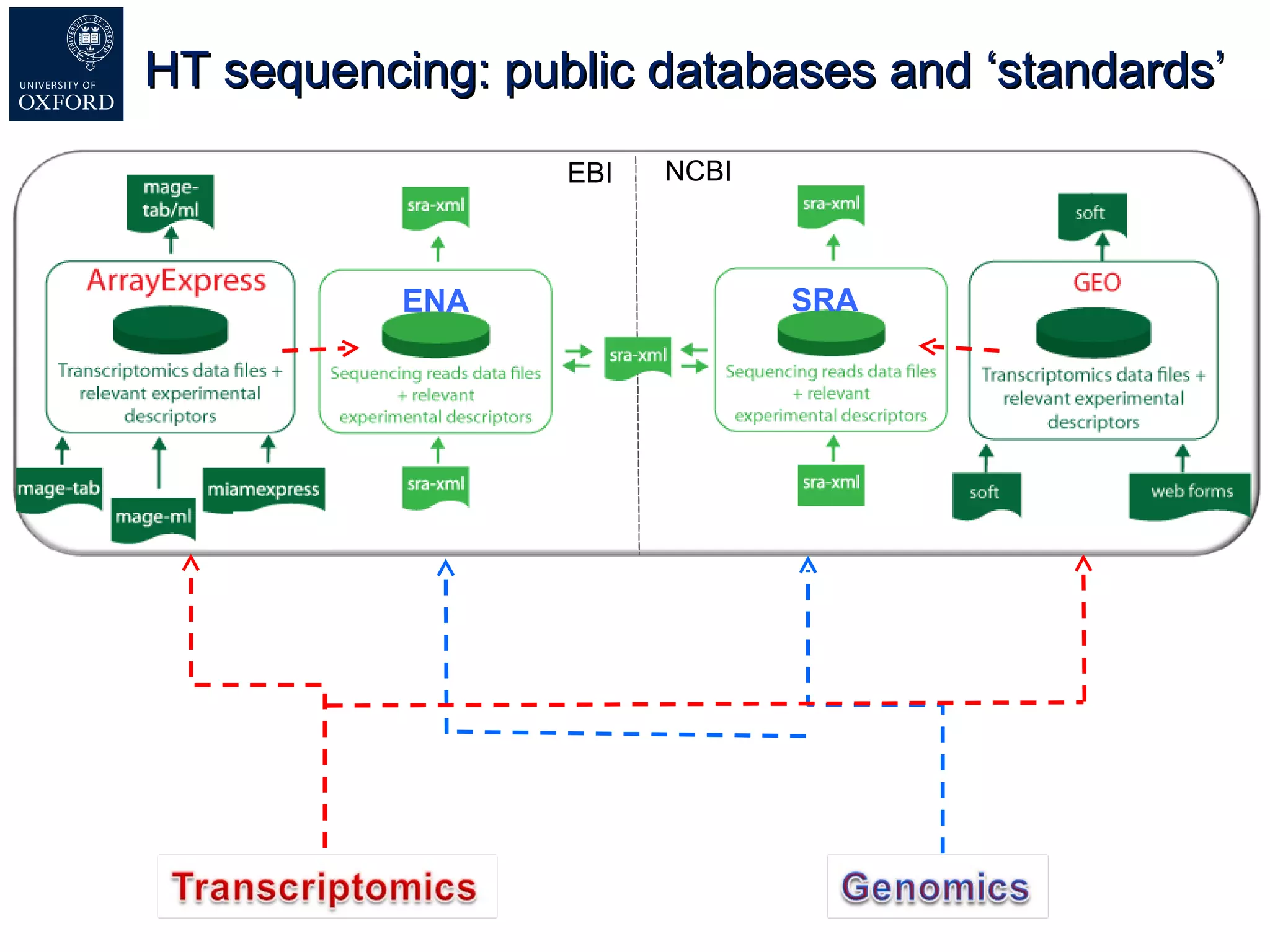
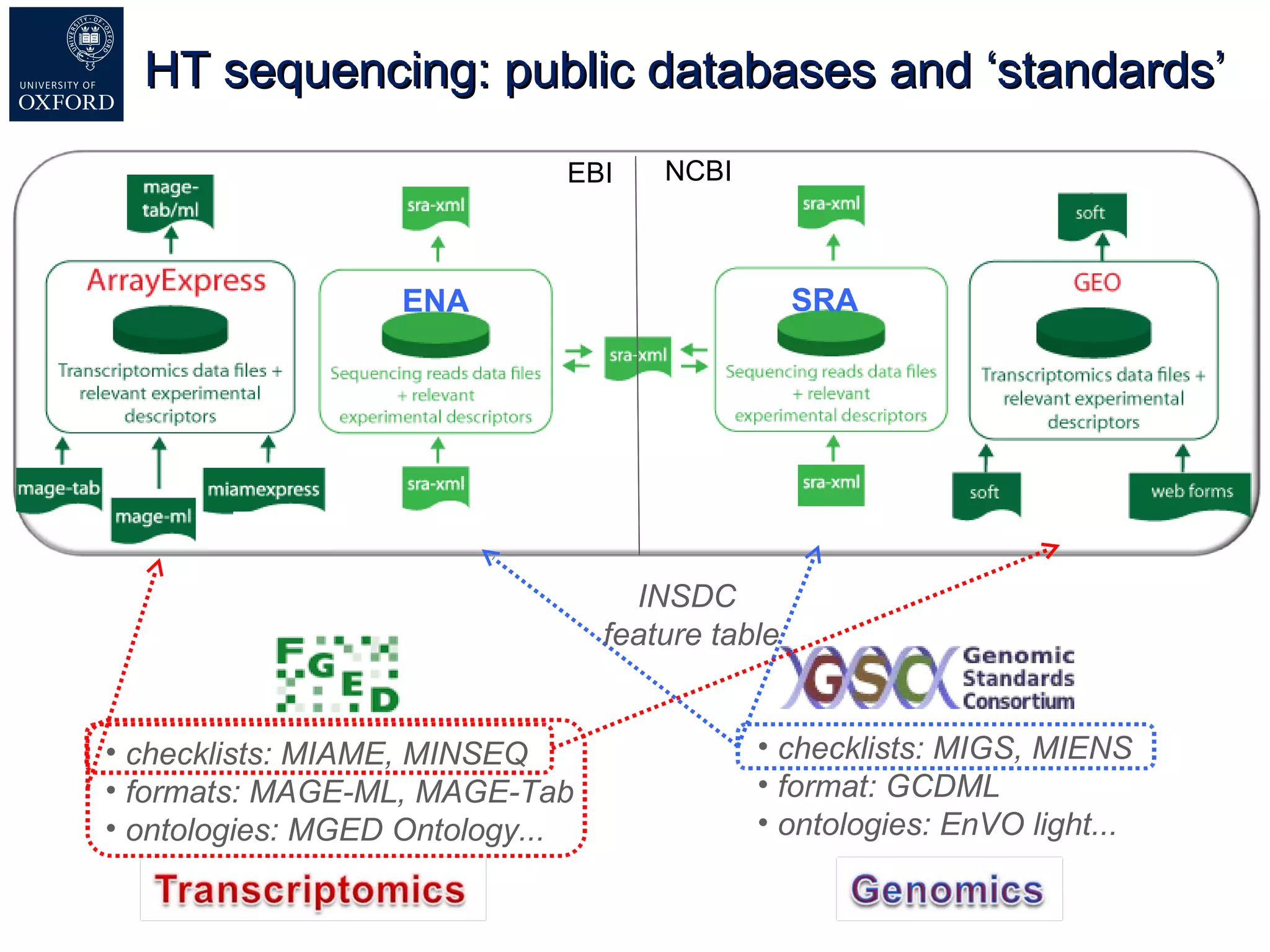

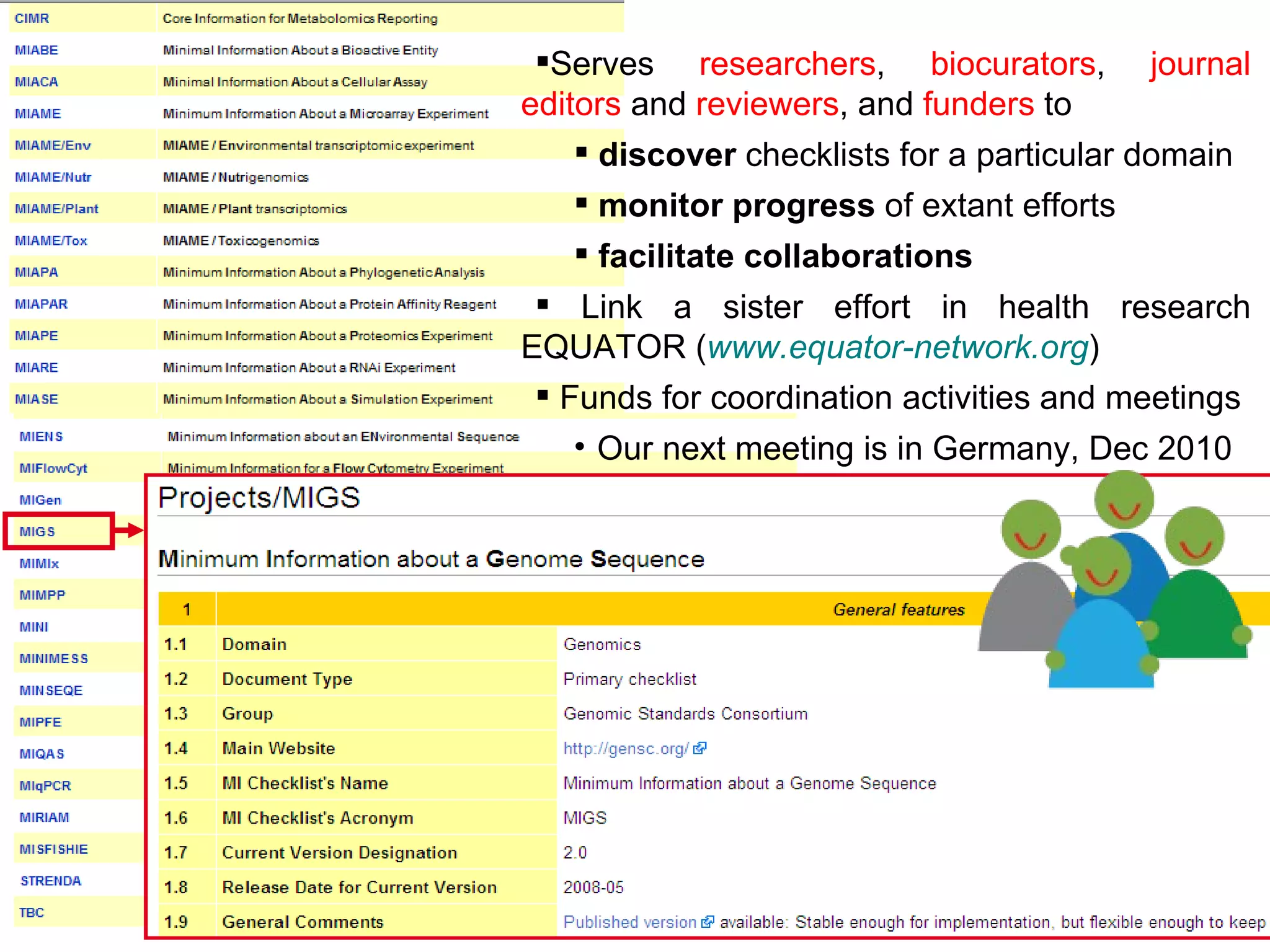

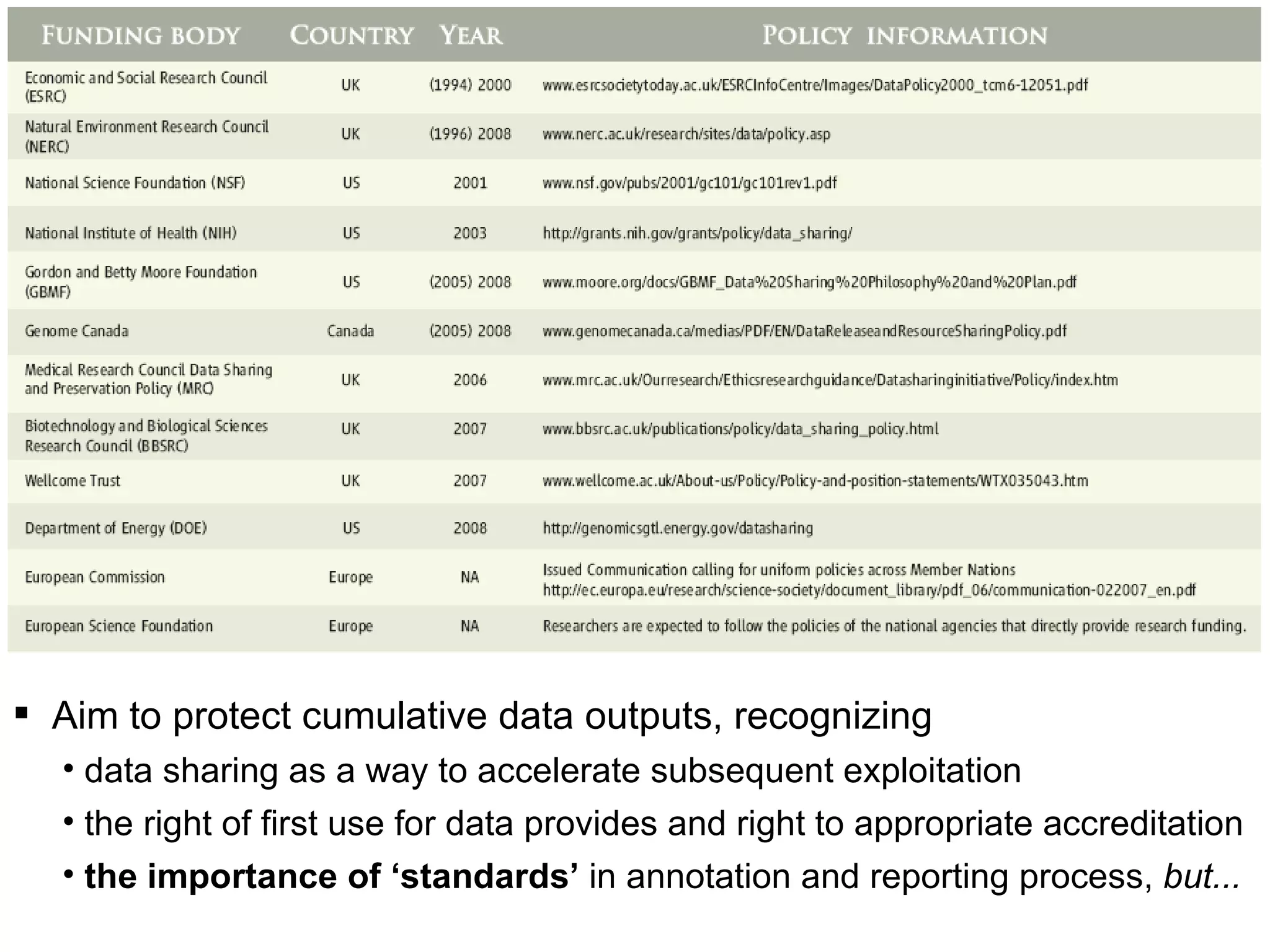
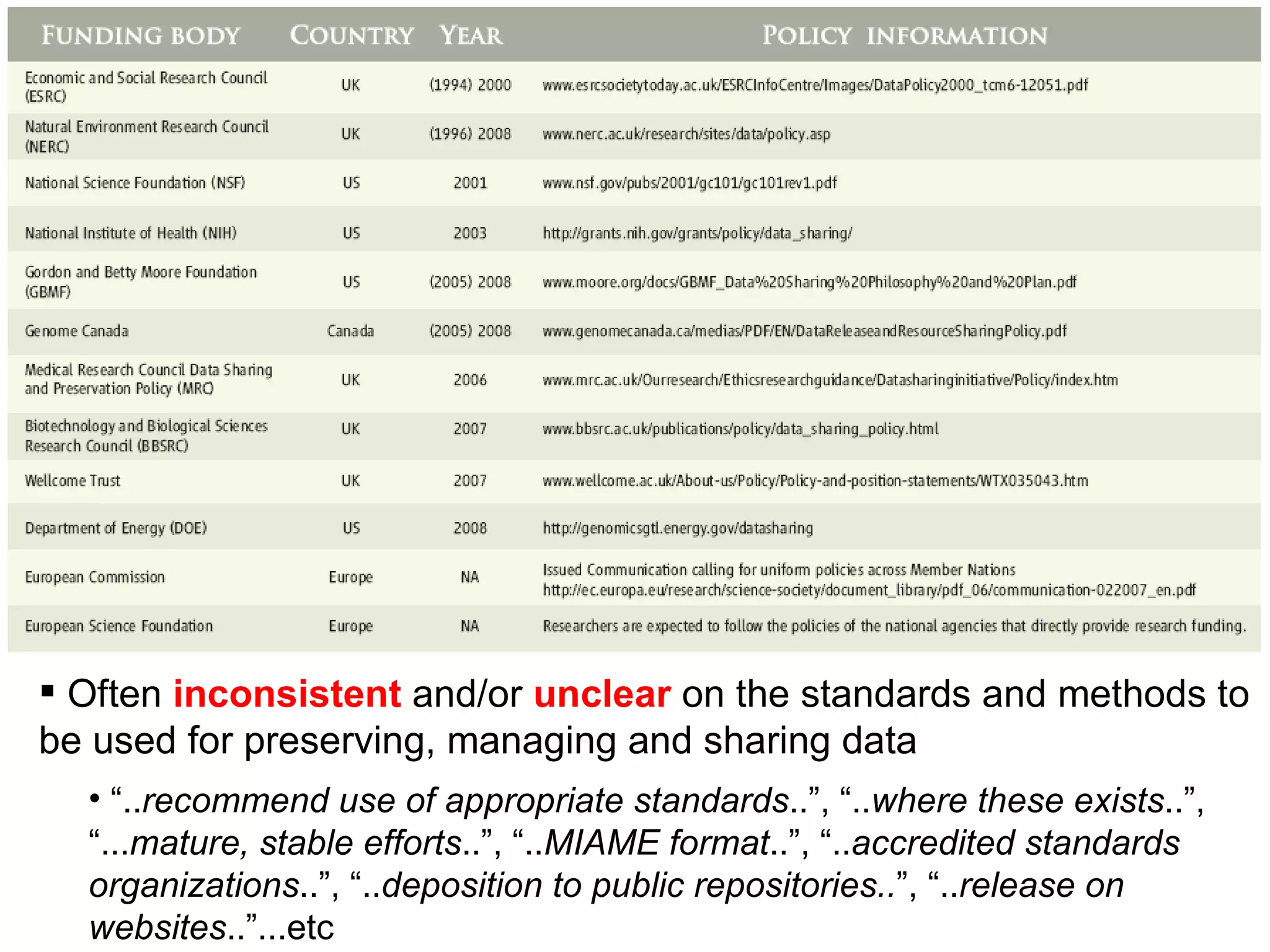
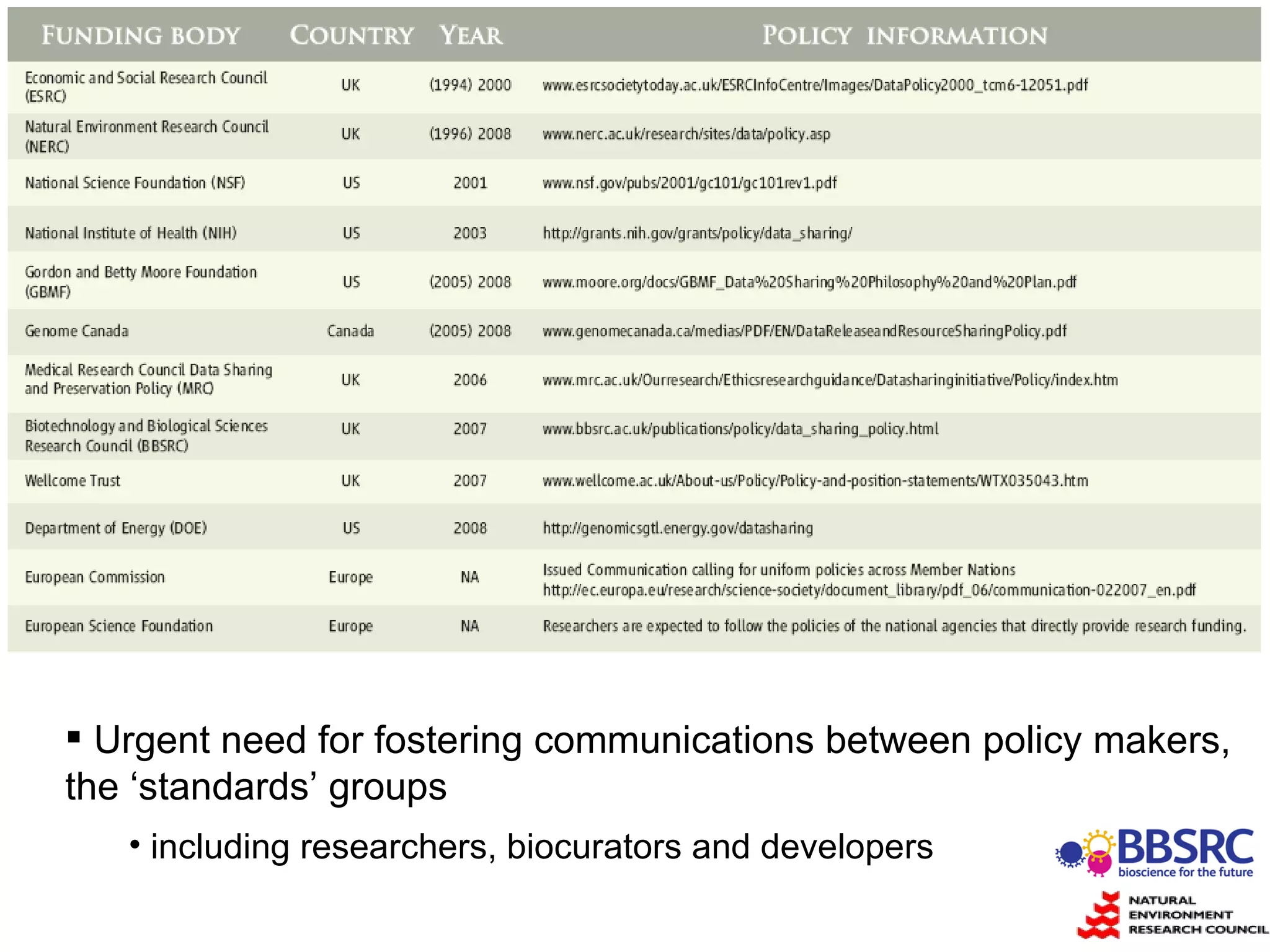
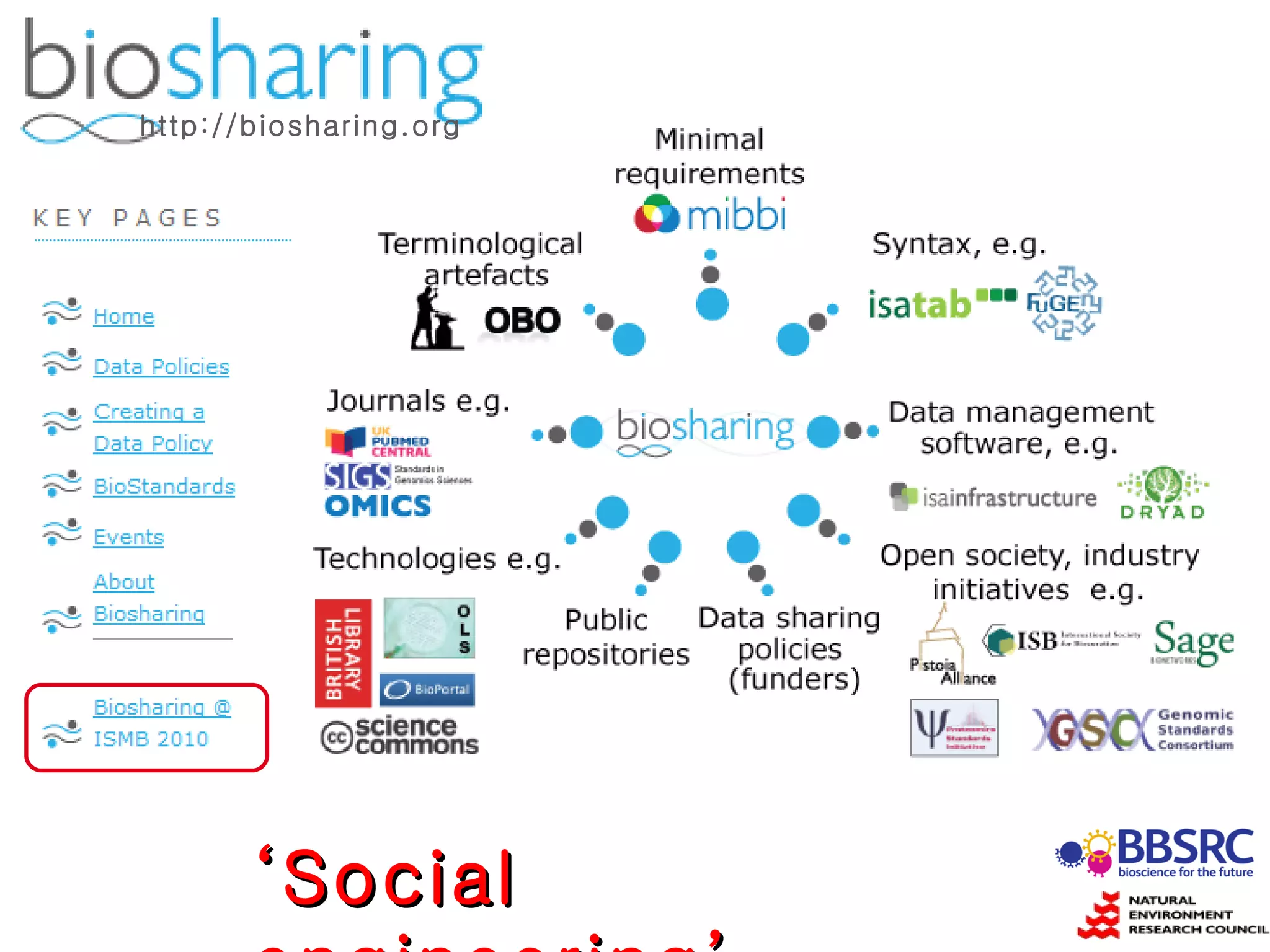




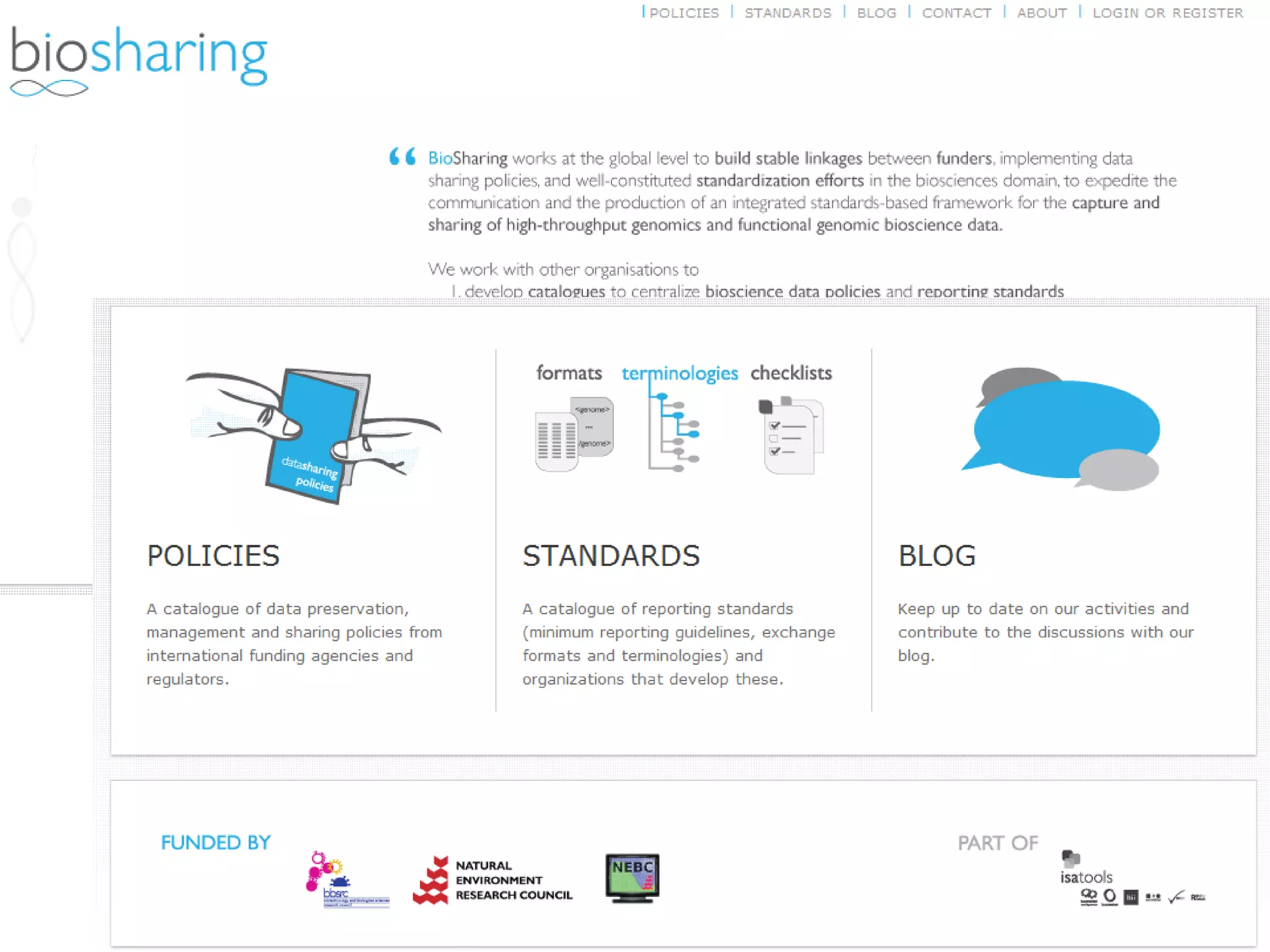
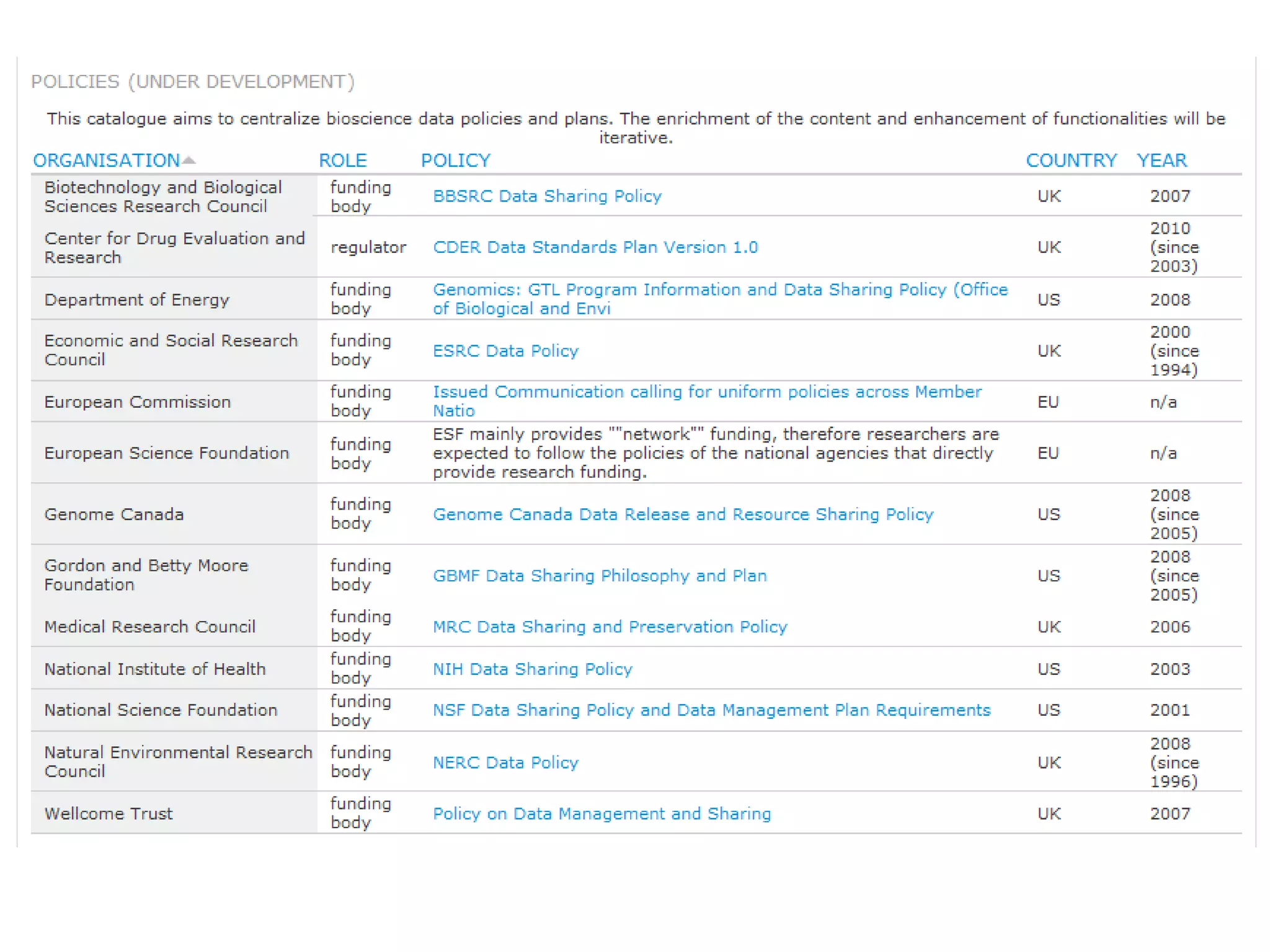
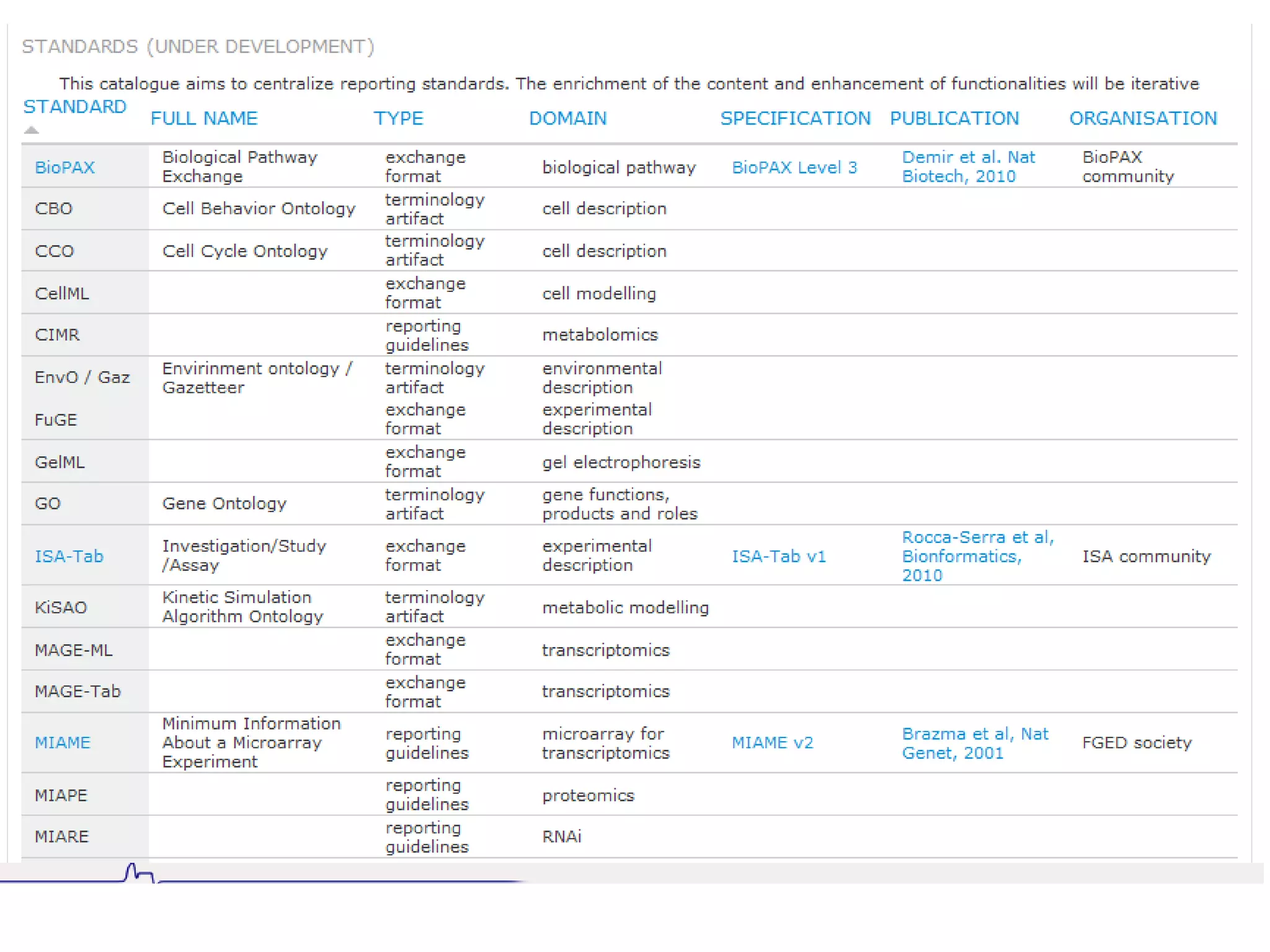

Susanna-Assunta Sansone presented at the International Conference on Systems Biology on standards to enable sharing of experimental data and metadata. Three types of standards are needed: minimum reporting checklists, controlled vocabularies and terminologies, and data exchange formats. Journals, biocurators, and funders are developing these standards to support comprehensible, reusable, and reproducible research. However, navigating the various standards can be challenging, and communication is needed between standards groups and other stakeholders.





























































































