Download as PDF, PPTX



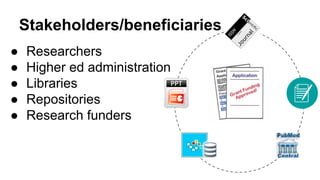

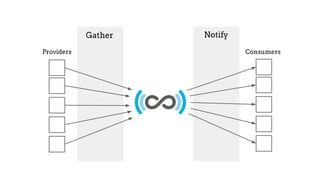
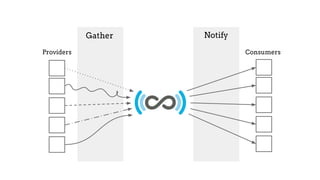
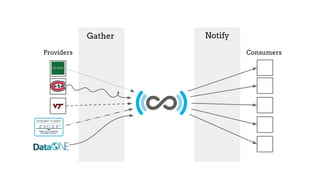













The SHARE initiative, led by Judy Ruttenberg and Jeff Spies, aims to create an open data set cataloging research activities across their life cycle, making it accessible and reusable for various stakeholders including researchers, universities, and funders. Key focus areas include improving metadata consistency, addressing the rights of providers, and promoting data-sharing policies while leveraging modular and scalable technology. Opportunities for participation exist in enhancing infrastructure and workflows to support effective data sharing.










































































