Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takeshi Akutsu
PDF, PPTX
1,829 views
S06 t1 python学習奮闘記#4
みんなのPython勉強会#6 Talk 1:「私のPython学習奮闘記#4 〜機械学習編〜」 阿久津剛史(Start Python Club)
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 36
2
/ 36
3
/ 36
4
/ 36
5
/ 36
6
/ 36
7
/ 36
8
/ 36
9
/ 36
10
/ 36
11
/ 36
12
/ 36
13
/ 36
14
/ 36
15
/ 36
16
/ 36
17
/ 36
18
/ 36
19
/ 36
20
/ 36
21
/ 36
22
/ 36
23
/ 36
24
/ 36
25
/ 36
26
/ 36
27
/ 36
28
/ 36
29
/ 36
30
/ 36
31
/ 36
32
/ 36
33
/ 36
34
/ 36
35
/ 36
36
/ 36
More Related Content
PDF
S12 t1 python学習奮闘記#5
by
Takeshi Akutsu
PPTX
Pythonのプロファイリング
by
ysakaguchi
PDF
S10 t1 spc_by_nowfromnow
by
Takeshi Akutsu
PDF
S01 t1 tsuji_pylearn_ut_01
by
Takeshi Akutsu
PPTX
オリエンテーション
by
Takeshi Akutsu
PDF
S02 t0 get_started
by
Takeshi Akutsu
PDF
Introduction
by
Takeshi Akutsu
PDF
S01 t0 orientation
by
Takeshi Akutsu
S12 t1 python学習奮闘記#5
by
Takeshi Akutsu
Pythonのプロファイリング
by
ysakaguchi
S10 t1 spc_by_nowfromnow
by
Takeshi Akutsu
S01 t1 tsuji_pylearn_ut_01
by
Takeshi Akutsu
オリエンテーション
by
Takeshi Akutsu
S02 t0 get_started
by
Takeshi Akutsu
Introduction
by
Takeshi Akutsu
S01 t0 orientation
by
Takeshi Akutsu
What's hot
PDF
S09 t0 orientation
by
Takeshi Akutsu
PDF
S05_T0_orientation
by
Takeshi Akutsu
PDF
S03 t0 get_started
by
Takeshi Akutsu
PDF
S08 t0 orientation
by
Takeshi Akutsu
PDF
S06 t0 orientation
by
Takeshi Akutsu
PDF
まとめ
by
Takeshi Akutsu
PDF
S10 t0 orientation
by
Takeshi Akutsu
PDF
S01 t2 akutsu_my_pythonhistory
by
Takeshi Akutsu
PDF
S03 t1 python_learningdiary#3
by
Takeshi Akutsu
PPTX
Python入門者の集い #6 Lightning Talk
by
Katayanagi Nobuko
PDF
Python学習奮闘記#07 webapp
by
Takeshi Akutsu
PDF
Python札幌 2012/06/17
by
Shinya Okano
PDF
PyLadies Tokyo - 初心者向けPython体験ワークショップ開催の裏側
by
Katayanagi Nobuko
PDF
Pythonによるwebアプリケーション入門 - Django編-
by
Hironori Sekine
PDF
Python for Beginners ( #PyLadiesKyoto Meetup )
by
Ai Makabi
PDF
S20 t1 stapyのこれまでとこれから
by
Takeshi Akutsu
ODP
stapy#23 LT
by
NaoY-2501
PDF
「長野で語るStapyのビジョン」
by
Takeshi Akutsu
PDF
S16 t1 python学習奮闘記#6
by
Takeshi Akutsu
PPTX
ちょっと真面目にPython&Django・基礎編
by
OMEGA (@equal_001)
S09 t0 orientation
by
Takeshi Akutsu
S05_T0_orientation
by
Takeshi Akutsu
S03 t0 get_started
by
Takeshi Akutsu
S08 t0 orientation
by
Takeshi Akutsu
S06 t0 orientation
by
Takeshi Akutsu
まとめ
by
Takeshi Akutsu
S10 t0 orientation
by
Takeshi Akutsu
S01 t2 akutsu_my_pythonhistory
by
Takeshi Akutsu
S03 t1 python_learningdiary#3
by
Takeshi Akutsu
Python入門者の集い #6 Lightning Talk
by
Katayanagi Nobuko
Python学習奮闘記#07 webapp
by
Takeshi Akutsu
Python札幌 2012/06/17
by
Shinya Okano
PyLadies Tokyo - 初心者向けPython体験ワークショップ開催の裏側
by
Katayanagi Nobuko
Pythonによるwebアプリケーション入門 - Django編-
by
Hironori Sekine
Python for Beginners ( #PyLadiesKyoto Meetup )
by
Ai Makabi
S20 t1 stapyのこれまでとこれから
by
Takeshi Akutsu
stapy#23 LT
by
NaoY-2501
「長野で語るStapyのビジョン」
by
Takeshi Akutsu
S16 t1 python学習奮闘記#6
by
Takeshi Akutsu
ちょっと真面目にPython&Django・基礎編
by
OMEGA (@equal_001)
Viewers also liked
PDF
S01 t3 data_engineer
by
Takeshi Akutsu
PDF
相関マイニング(バスケット分析)
by
Katsuhiro Takata
PDF
S14 t0 introduction
by
Takeshi Akutsu
PDF
Pythonで画面付きのアプリを作成する
by
Jun Okazaki
PDF
Pythonで機械学習入門以前
by
Kimikazu Kato
PDF
bottleで始めるWEBアプリの最初の一歩
by
Satoshi Yamada
PPTX
Chainerで学ぶdeep learning
by
Retrieva inc.
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
S01 t3 data_engineer
by
Takeshi Akutsu
相関マイニング(バスケット分析)
by
Katsuhiro Takata
S14 t0 introduction
by
Takeshi Akutsu
Pythonで画面付きのアプリを作成する
by
Jun Okazaki
Pythonで機械学習入門以前
by
Kimikazu Kato
bottleで始めるWEBアプリの最初の一歩
by
Satoshi Yamada
Chainerで学ぶdeep learning
by
Retrieva inc.
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
Similar to S06 t1 python学習奮闘記#4
PDF
S02 t2 my_historyofpythonlearning
by
Takeshi Akutsu
PDF
Python初心者が4年で5000人のコミュニティに作ったエモい話
by
Takeshi Akutsu
PDF
モダンな独学の道。そうだ、オープンソースでいこう!
by
Takeshi Akutsu
PDF
全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PDF
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PDF
データ分析コンペでスキルアップしよう.pdf
by
H. K
PDF
python3 エンジニア認定データ分析試験を受けてみた
by
ssuserf94232
PDF
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
PDF
データ分析-の波乗り遅れた気がしてる人のための Python×データ分析の超基礎の基礎 v1.0-20160831
by
Yusaku Kinoshita
PDF
DS Exercise Course 2
by
大貴 末廣
PDF
OSS Study#19_LT
by
NaoY-2501
PDF
最速でデータサイエンティストになる方法を考えてみた
by
Seiya Kitazume
PPTX
Python基礎その1
by
大貴 末廣
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 第3版
by
Katsuhiro Morishita
PPTX
Study ml
by
卓馬 三浦卓馬
PDF
Casual data analysis_with_python_vol1
by
KazuhiroSato8
PDF
DATUM STUDIO PyCon2016 Turorial
by
Tatsuya Tojima
PDF
DS Exercise Course 1
by
大貴 末廣
PPTX
data science study group vol.5(Japanese)
by
Yusuke Ohira
PDF
stapy_fukuoka_01_akutsu
by
Takeshi Akutsu
S02 t2 my_historyofpythonlearning
by
Takeshi Akutsu
Python初心者が4年で5000人のコミュニティに作ったエモい話
by
Takeshi Akutsu
モダンな独学の道。そうだ、オープンソースでいこう!
by
Takeshi Akutsu
全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
データ分析コンペでスキルアップしよう.pdf
by
H. K
python3 エンジニア認定データ分析試験を受けてみた
by
ssuserf94232
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
データ分析-の波乗り遅れた気がしてる人のための Python×データ分析の超基礎の基礎 v1.0-20160831
by
Yusaku Kinoshita
DS Exercise Course 2
by
大貴 末廣
OSS Study#19_LT
by
NaoY-2501
最速でデータサイエンティストになる方法を考えてみた
by
Seiya Kitazume
Python基礎その1
by
大貴 末廣
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 第3版
by
Katsuhiro Morishita
Study ml
by
卓馬 三浦卓馬
Casual data analysis_with_python_vol1
by
KazuhiroSato8
DATUM STUDIO PyCon2016 Turorial
by
Tatsuya Tojima
DS Exercise Course 1
by
大貴 末廣
data science study group vol.5(Japanese)
by
Yusuke Ohira
stapy_fukuoka_01_akutsu
by
Takeshi Akutsu
More from Takeshi Akutsu
PDF
みんなのPython勉強会#111 LT資料 "AIとサステナビリティについて"
by
Takeshi Akutsu
PDF
万年ビギナーによるPythonプログラミングのリハビリ計画
by
Takeshi Akutsu
PPTX
Stapyの6年~本との出会いから生まれた技術コミュニティ~
by
Takeshi Akutsu
PPTX
Start Python Club 2020年活動報告
by
Takeshi Akutsu
PPTX
みんなのPython勉強会#59 Intro
by
Takeshi Akutsu
PDF
On the Necessity and Inapplicability of Python
by
Takeshi Akutsu
PDF
Stapyユーザーガイド
by
Takeshi Akutsu
PDF
Scipy Japan 2019参加レポート
by
Takeshi Akutsu
PDF
Scipy Japan 2019の紹介
by
Takeshi Akutsu
PDF
みんなのPython勉強会 in 長野 #3, Intro
by
Takeshi Akutsu
PDF
Introduction
by
Takeshi Akutsu
PPTX
みんなのPython勉強会#35 まとめ
by
Takeshi Akutsu
PDF
LT_by_Takeshi
by
Takeshi Akutsu
PDF
Orientation
by
Takeshi Akutsu
PDF
Introduction
by
Takeshi Akutsu
PDF
プログラミング『超入門書』から見るPythonと解説テクニック
by
Takeshi Akutsu
PPTX
We are OSS Communities: Introduction of Start Python Club
by
Takeshi Akutsu
PDF
ドコモAIエージェントAPIのご紹介
by
Takeshi Akutsu
PPTX
S28 t0 introduction
by
Takeshi Akutsu
PPTX
stapy_028_talk1
by
Takeshi Akutsu
みんなのPython勉強会#111 LT資料 "AIとサステナビリティについて"
by
Takeshi Akutsu
万年ビギナーによるPythonプログラミングのリハビリ計画
by
Takeshi Akutsu
Stapyの6年~本との出会いから生まれた技術コミュニティ~
by
Takeshi Akutsu
Start Python Club 2020年活動報告
by
Takeshi Akutsu
みんなのPython勉強会#59 Intro
by
Takeshi Akutsu
On the Necessity and Inapplicability of Python
by
Takeshi Akutsu
Stapyユーザーガイド
by
Takeshi Akutsu
Scipy Japan 2019参加レポート
by
Takeshi Akutsu
Scipy Japan 2019の紹介
by
Takeshi Akutsu
みんなのPython勉強会 in 長野 #3, Intro
by
Takeshi Akutsu
Introduction
by
Takeshi Akutsu
みんなのPython勉強会#35 まとめ
by
Takeshi Akutsu
LT_by_Takeshi
by
Takeshi Akutsu
Orientation
by
Takeshi Akutsu
Introduction
by
Takeshi Akutsu
プログラミング『超入門書』から見るPythonと解説テクニック
by
Takeshi Akutsu
We are OSS Communities: Introduction of Start Python Club
by
Takeshi Akutsu
ドコモAIエージェントAPIのご紹介
by
Takeshi Akutsu
S28 t0 introduction
by
Takeshi Akutsu
stapy_028_talk1
by
Takeshi Akutsu
S06 t1 python学習奮闘記#4
1.
みんなのPython勉強会 #6 Nov. 9, 2015 阿久津 剛史 1 私のPython学習奮闘記#4 〜機械学習編〜
2.
自己紹介 • 阿久津 剛史 Twi7er @akucchan_world • 某メーカー勤務 – 元光通信エンジニア – 現マーケティング担当 •
Python経験1年弱 – 趣味と実益に生かそうと勉強中 2
3.
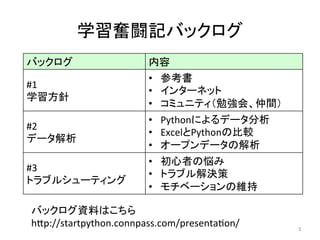
学習奮闘記バックログ 3 バックログ 内容 #1 学習方針 • 参考書 •
インターネット • コミュニティ(勉強会、仲間) #2 データ解析 • Pythonによるデータ分析 • ExcelとPythonの比較 • オープンデータの解析 #3 トラブルシューティング • 初心者の悩み • トラブル解決策 • モチベーションの維持 バックログ資料はこちら h7p://startpython.connpass.com/presentaJon/
4.
Contents 1. データサイエンスとの出会い 2. Python x 機械学習 3.
基本スキルの習得 4. Pythonによる実践 5. 今後の課題 6. まとめ 4
5.
Contents 1. データサイエンスとの出会い 2. Python x 機械学習 3.
基本スキルの習得 4. Pythonによる実践 5. 今後の課題 6. まとめ 5
6.
データサイエンスとの出会い Thomas H. Davenport and D.J. PaJl, “Data ScienJst: The Sexiest Job of the 21st Century”, HBR (2010, Oct.) • 「データサイエンティストは21世紀、 もっともセクシーな職業になる」 • ビッグデータとアナリティクスによる 新たなビジネスの可能性 6
7.
データサイエンスってなに? トーマス・H・ダベンポート、 『データ・アナリティクス3.0 』 • ビッグデータのインパクト • ビジネス事例(GE、UPSなど) •
関連技術 • Python • 機械学習 • 自然言語処理 7
8.
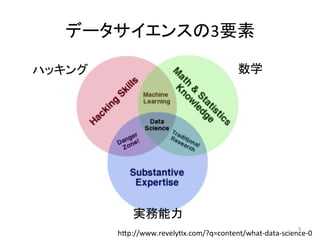
データサイエンスの3要素 h7p://www.revelyJx.com/?q=content/what-data-science-0 数学 ハッキング 実務能力 8
9.
Contents 1. データサイエンスとの出会い 2. Python x 機械学習 3.
基本スキルの習得 4. Pythonによる実践 5. 今後の課題 6. まとめ 9
10.
まずはPython! 10
11.
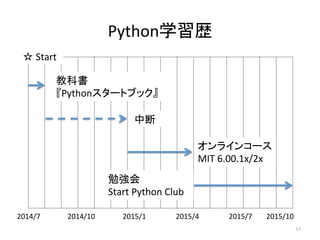
Python学習歴 11 2014/7 2014/10 2015/1
2015/4 2015/7 教科書 『Pythonスタートブック』 中断 オンラインコース MIT 6.00.1x/2x 勉強会 Start Python Club 2015/10 ☆ Start
12.
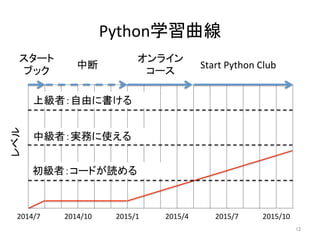
Python学習曲線 12 2014/7 2014/10 2015/1
2015/4 2015/7 スタート ブック 中断 オンライン コース Start Python Club 2015/10 レベル 初級者:コードが読める 中級者:実務に使える 上級者:自由に書ける
13.
つぎ、いってみよう〜! 13
14.
機械学習ってなに? 14 機械学習(きかいがくしゅう、英: machine learning) とは、人工知能における研究課題の一つで、人間 が自然に行っている学習能力と同様の機能をコン ピュータで実現しようとする技術・手法のことである。 Wikipedia, 「機械学習」 h7ps://ja.wikipedia.org/wiki/機械学習
15.
機械学習の実用例 15 Google自動運転プロジェクト カード不正利用の自動検出 PYMK (People You May Know) レコメンデーション
16.
機械学習の理論は難解 16 • テキストは豊富 – 『パターン認識と機械学習』 (通称:PRML) –
講談社、『機械学習プロフェッ ショナルシリーズ』 • 理解は難解 – 大学レベルの数学(線形代数、 解析、統計学) • 実務まで遠い – 初心者にはプログラミングも 課題
17.
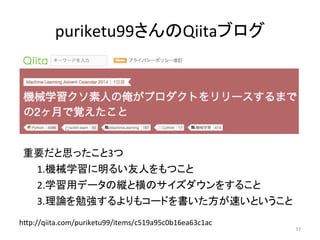
puriketu99さんのQiitaブログ 17 h7p://qiita.com/puriketu99/items/c519a95c0b16ea63c1ac 重要だと思ったこと3つ 1.機械学習に明るい友人をもつこと 2.学習用データの縦と横のサイズダウンをすること 3.理論を勉強するよりもコードを書いた方が速いということ
18.
私の学習戦略 • 方針 – 理論の基礎レベルはつかもう – コード実習を重視 18 理論基礎 • 参考書 •
オンライン学習 コード実習 • 参考書 • Scikit-learn公式サイト
19.
Contents 1. データサイエンスとの出会い 2. Python x 機械学習 3.
基本スキルの習得 4. Pythonによる実践 5. 今後の課題 6. まとめ 19
20.
『実践機械学習システム』 著者: Willi Richert, Luis Pedro Coelho • scikit-learnを中心とした Pythonによる機械学習 • 多くのコード例 •
原本はVer.2でPython 3.xに 対応。サンプルコードも大幅 改訂。 • ただしタイポなど多いので要 注意 20
21.
Scikit-learnホームページ 21 h7p://scikit-learn.org
22.
DAT203x: Data Science and Machine Learning EssenJals 22 h7ps://www.edx.org/course/data-science-machine-learning-essenJals-microsok-dat203x • Microsokが提供するオンラインコース • Azure MLを使いながら機械学習の基礎を学習 •
PythonとRの好きな方を選択
23.
Intro to Machine Learning 23 • Stanford Univ.の自動運転車の研究者が講師 • 約10週間のコース •
プログラミング(Python)、統計に関する基本的 な知識が履修要件 h7ps://www.udacity.com/course/intro-to-machine-learning--ud120
24.
Stanford University: Machine Learning 24 • Stanford Univ.の研究者、百度(Baidu)のチーフ サイエンティストが講師 • 11週間のコース •
機械学習の全般的なスキルを学習する h7ps://www.coursera.org/learn/machine-learning/
25.
Contents 1. データサイエンスとの出会い 2. Python x 機械学習 3.
基本スキルの習得 4. Pythonによる実践 5. 今後の課題 6. まとめ 25
26.
UCI Machine Learning Repository 26 h7ps://archive.ics.uci.edu/ml/index.html • UC Irvineが収集、管理している機械学習レポジトリ • 335件のデータセット •
分類、回帰、クラスタリングなど各種の機械学習に 適用可
27.
Iris Flower Data Set • 3種のアヤメ(Iris)の特徴量 を収集したデータセット • Ronald Fisherが1936年の論 文で紹介 •
線形判別分析(LDA)を適用 • UCI ML Repositoryに収録 • 150件のデータ • 機械学習の入門用データ セットとして利用されている 27 h7ps://en.wikipedia.org/wiki/Iris_flower_data_set Iris setosa Iris versicolor Iris virginica
28.
Irisデータセット 28 sepal length がく片 長さ sepal width がく片 幅 petal length 花弁 長さ petal width 花弁 幅 class 品種 5.1 3.5 1.4
0.2 Iris-setosa 4.9 3 1.4 0.2 Iris-setosa 4.7 3.2 1.3 0.2 Iris-setosa 4.6 3.1 1.5 0.2 Iris-setosa 5 3.6 1.4 0.2 Iris-setosa … … … … … h7p://sebasJanraschka.com/ ArJcles/2014_python_lda.html 特徴量 (Features) ラベル (Label)
29.
sca7er-matrix 29
30.
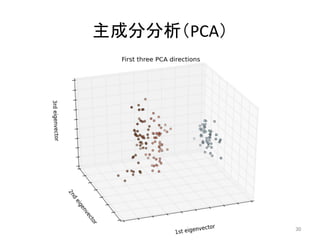
主成分分析(PCA) 30
31.
その他のデータセット 31 Method Contents load_boston() Boston市内の不動産価格のデータセット。 部屋の広さ、周辺の犯罪率などの特徴量が ある。回帰分析に用いる。 load_diabetes()
糖尿病患者のデータセット。年齢、入院履歴 などの特徴量がある。回帰分析に用いる。 load_digits() 0〜9の手書き文字の画像データ。8x8の画 像データ1797個で構成。分類に用いる。 load_linnerud() 重回帰用のデータセット。20個の3次元特徴 量と3次元の回帰対象のセット。
32.
Contents 1. データサイエンスとの出会い 2. Python x 機械学習 3.
基本スキルの習得 4. Pythonによる実践 5. 今後の課題 6. まとめ 32
33.
今後の課題 • 機械学習の学習の継続 – 機械学習の項目は理解しはじめた – まだまだ基本的な事項があやしい • 実際のビジネス課題への適用 – マーケティング分析 – IoTビジネス、etc 33
34.
データサイエンティストの需要 34 h7p://www.mckinsey.com/insights/business_technology/ big_data_the_next_fronJer_for_innovaJon • 2018年までにアメリカ国内 だけで高度な分析スキルを 有する専門家が 14〜19万人不足 • ビッグデータの分析ノウハ ウを有するマネージャや アナリストが150万人不足
35.
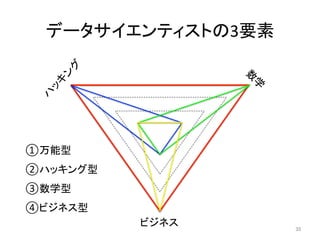
データサイエンティストの3要素 35 ビジネス ①万能型 ②ハッキング型 ③数学型 ④ビジネス型
36.
まとめ • Python x 機械学習 – 初心者はPythonコードの基本を覚えよう – 機械学習はコード実践重視が良さそう • 今後の課題 – 基本事項の習得 – ビジネス課題への適用 36
Download