Downloaded 20 times









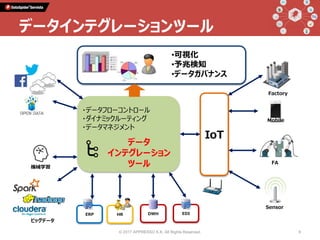
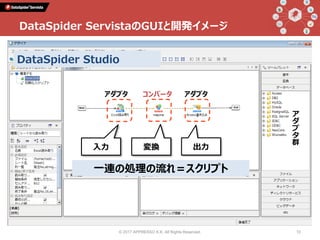
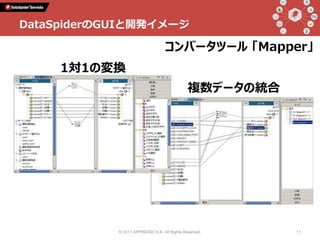
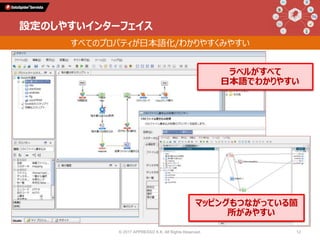



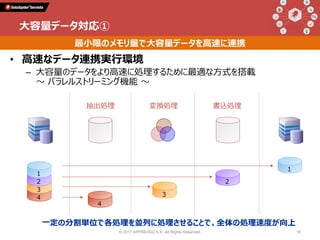
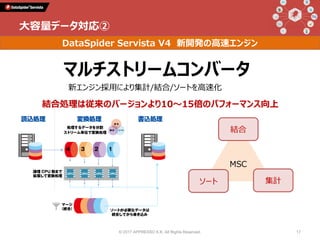
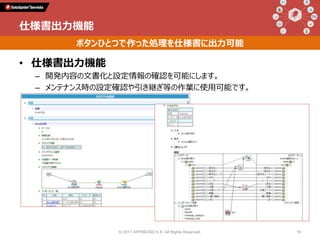





















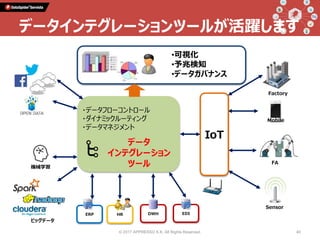






Talk 1: 「データインテグレーションとは何か」 小野和俊(セゾン情報システムズ / アプレッソ) 当時から今に至るまで一貫してプログラマーである私は、2000年に起業してDataSpiderという製品を作りました。データの連携に関する処理を担うこの分野の製品は、EAI、ETL、最近ではDI(Data Integration)と呼ばれていますが、そもそも一体どんなものなのか?そしてPythonとどのように組み合わせることができ、Pythonistaから見てどんな利点があるのか?等について紹介します。












![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)



![[第37回 Machine Learning 15minutes!] Microsoft AI - Build 2019 Updates ~ Azure ...](https://cdn.slidesharecdn.com/ss_thumbnails/20190629ml15azuremlbuild2019updates-190630053028-thumbnail.jpg?width=640&height=640&fit=bounds)


















































