The document discusses Yum Brands potentially expanding into India. It analyzes cultural differences between American and Indian culture such as family relationships, hierarchies, time orientation, and communication styles. It recommends ways for Yum Brands to exchange culture effectively, such as being aware of religious holidays, learning local language phrases, and understanding gestures and hierarchies. It also suggests that direct distribution would be the best method for Yum Brands to use in India, as it does not involve intermediaries and allows direct contact between the company and customers.



































































![(http://illimine.cs.uiuc.edu).
Sample assignments, exams, and course projects. A set of
sample assignments,
exams, and course projects is available to instructors from the
publisher’s web site.
Figures from the book. This may help you to make your own
slides for your
classroom teaching.
Contents of the book in PDF format.
Errata on the different printings of the book. We encourage you
to point out any
errors in this book. Once the error is confirmed, we will update
the errata list and
include acknowledgment of your contribution.
Comments or suggestions can be sent to [email protected] We
would be happy to hear
from you.
EDELKAMP 19-ch15-671-700-9780123725127 2011/5/28 14:50
Page 672 #2
This page intentionally left blank
HAN 06-ack-xxxi-xxxiv-9780123814791 2011/6/1 3:36 Page
xxxi #1
Acknowledgments](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-68-320.jpg)











![aggregated. Using aggre-
gated Google search data, Flu Trends can estimate flu activity
up to two weeks faster
than traditional systems can.2 This example shows how data
mining can turn a large
collection of data into knowledge that can help meet a current
global challenge.
1.1.2 Data Mining as the Evolution of Information Technology
Data mining can be viewed as a result of the natural evolution
of information tech-
nology. The database and data management industry evolved in
the development of
2This is reported in [GMP+09].
HAN 08-ch01-001-038-9780123814791 2011/6/1 3:12 Page 3 #3
1.1 Why Data Mining? 3
Data Collection and Database Creation
(1960s and earlier)
Primitive file processing
Database Management Systems
(1970s to early 1980s)
Hierarchical and network database systems
Relational database systems
Data modeling: entity-relationship models, etc.
Indexing and accessing methods
Query languages: SQL, etc.
User interfaces, forms, and reports](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-80-320.jpg)

































![that customers, tend to purchase first a laptop, followed by a
digital camera, and then
a memory card, is a (frequent) sequential pattern. A
substructure can refer to different
structural forms (e.g., graphs, trees, or lattices) that may be
combined with itemsets
or subsequences. If a substructure occurs frequently, it is called
a (frequent ) structured
pattern. Mining frequent patterns leads to the discovery of
interesting associations and
correlations within data.
Example 1.7 Association analysis. Suppose that, as a marketing
manager at AllElectronics, you want
to know which items are frequently purchased together (i.e.,
within the same transac-
tion). An example of such a rule, mined from the AllElectronics
transactional database, is
buys(X , “computer”) ⇒ buys(X , “software”) [support = 1%,
confidence = 50%],
where X is a variable representing a customer. A confidence, or
certainty, of 50%
means that if a customer buys a computer, there is a 50% chance
that she will buy
software as well. A 1% support means that 1% of all the
transactions under analysis
show that computer and software are purchased together. This
association rule involves
a single attribute or predicate (i.e., buys) that repeats.
Association rules that contain a
single predicate are referred to as single-dimensional
association rules. Dropping the
predicate notation, the rule can be written simply as “computer
⇒ software [1%, 50%].”](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-114-320.jpg)
![Suppose, instead, that we are given the AllElectronics relational
database related to
purchases. A data mining system may find association rules like
age(X , “20..29”)∧ income(X , “40K..49K”) ⇒ buys(X ,
“laptop”)
[support = 2%, confidence = 60%].
The rule indicates that of the AllElectronics customers under
study, 2% are 20 to 29 years
old with an income of $40,000 to $49,000 and have purchased a
laptop (computer)
at AllElectronics. There is a 60% probability that a customer in
this age and income
group will purchase a laptop. Note that this is an association
involving more than one
attribute or predicate (i.e., age, income, and buys). Adopting the
terminology used in
multidimensional databases, where each attribute is referred to
as a dimension, the
above rule can be referred to as a multidimensional association
rule.
HAN 08-ch01-001-038-9780123814791 2011/6/1 3:12 Page 18
#18
18 Chapter 1 Introduction
Typically, association rules are discarded as uninteresting if
they do not satisfy both a
minimum support threshold and a minimum confidence
threshold. Additional anal-](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-115-320.jpg)








































![1.8 Describe three challenges to data mining regarding data
mining methodology and user
interaction issues.
1.9 What are the major challenges of mining a huge amount of
data (e.g., billions of tuples)
in comparison with mining a small amount of data (e.g., data set
of a few hundred
tuple)?
1.10 Outline the major research challenges of data mining in
one specific application domain,
such as stream/sensor data analysis, spatiotemporal data
analysis, or bioinformatics.
1.10 Bibliographic Notes
The book Knowledge Discovery in Databases, edited by
Piatetsky-Shapiro and Frawley
[P-SF91], is an early collection of research papers on
knowledge discovery from data.
The book Advances in Knowledge Discovery and Data Mining,
edited by Fayyad,
Piatetsky-Shapiro, Smyth, and Uthurusamy [FPSS+96], is a
collection of later research
results on knowledge discovery and data mining. There have
been many data min-
ing books published in recent years, including The Elements of
Statistical Learning
by Hastie, Tibshirani, and Friedman [HTF09]; Introduction to
Data Mining by Tan,
Steinbach, and Kumar [TSK05]; Data Mining: Practical
Machine Learning Tools and
Techniques with Java Implementations by Witten, Frank, and
Hall [WFH11]; Predic-
tive Data Mining by Weiss and Indurkhya [WI98]; Mastering](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-156-320.jpg)
![Data Mining: The Art
and Science of Customer Relationship Management by Berry
and Linoff [BL99]; Prin-
ciples of Data Mining (Adaptive Computation and Machine
Learning) by Hand, Mannila,
and Smyth [HMS01]; Mining the Web: Discovering Knowledge
from Hypertext Data by
Chakrabarti [Cha03a]; Web Data Mining: Exploring Hyperlinks,
Contents, and Usage
HAN 08-ch01-001-038-9780123814791 2011/6/1 3:12 Page 36
#36
36 Chapter 1 Introduction
Data by Liu [Liu06]; Data Mining: Introductory and Advanced
Topics by Dunham
[Dun03]; and Data Mining: Multimedia, Soft Computing, and
Bioinformatics by Mitra
and Acharya [MA03].
There are also books that contain collections of papers or
chapters on particular
aspects of knowledge discovery—for example, Relational Data
Mining edited by Dze-
roski and Lavrac [De01]; Mining Graph Data edited by Cook
and Holder [CH07]; Data
Streams: Models and Algorithms edited by Aggarwal [Agg06];
Next Generation of Data
Mining edited by Kargupta, Han, Yu, et al. [KHY+08];
Multimedia Data Mining: A Sys-
tematic Introduction to Concepts and Theory edited by Z. Zhang
and R. Zhang [ZZ09];
Geographic Data Mining and Knowledge Discovery edited by](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-157-320.jpg)
![Miller and Han [MH09];
and Link Mining: Models, Algorithms and Applications edited
by Yu, Han, and Falout-
sos [YHF10]. There are many tutorial notes on data mining in
major databases, data
mining, machine learning, statistics, and Web technology
conferences.
KDNuggets is a regular electronic newsletter containing
information relevant to
knowledge discovery and data mining, moderated by Piatetsky-
Shapiro since 1991.
The Internet site KDNuggets (www.kdnuggets.com) contains a
good collection of KDD-
related information.
The data mining community started its first international
conference on knowledge
discovery and data mining in 1995. The conference evolved
from the four inter-
national workshops on knowledge discovery in databases, held
from 1989 to 1994.
ACM-SIGKDD, a Special Interest Group on Knowledge
Discovery in Databases was
set up under ACM in 1998 and has been organizing the
international conferences on
knowledge discovery and data mining since 1999. IEEE
Computer Science Society has
organized its annual data mining conference, International
Conference on Data Min-
ing (ICDM), since 2001. SIAM (Society on Industrial and
Applied Mathematics) has
organized its annual data mining conference, SIAM Data
Mining Conference (SDM),
since 2002. A dedicated journal, Data Mining and Knowledge
Discovery, published by](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-158-320.jpg)
![Kluwers Publishers, has been available since 1997. An ACM
journal, ACM Transactions
on Knowledge Discovery from Data, published its first volume
in 2007.
ACM-SIGKDD also publishes a bi-annual newsletter, SIGKDD
Explorations. There
are a few other international or regional conferences on data
mining, such as the
European Conference on Machine Learning and Principles and
Practice of Knowledge
Discovery in Databases (ECML PKDD), the Pacific-Asia
Conference on Knowledge
Discovery and Data Mining (PAKDD), and the International
Conference on Data
Warehousing and Knowledge Discovery (DaWaK).
Research in data mining has also been published in books,
conferences, and jour-
nals on databases, statistics, machine learning, and data
visualization. References to such
sources are listed at the end of the book.
Popular textbooks on database systems include Database
Systems: The Complete Book
by Garcia-Molina, Ullman, and Widom [GMUW08]; Database
Management Systems by
Ramakrishnan and Gehrke [RG03]; Database System Concepts
by Silberschatz, Korth,
and Sudarshan [SKS10]; and Fundamentals of Database Systems
by Elmasri and Navathe
[EN10]. For an edited collection of seminal articles on database
systems, see Readings in
Database Systems by Hellerstein and Stonebraker [HS05].](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-159-320.jpg)
![HAN 08-ch01-001-038-9780123814791 2011/6/1 3:12 Page 37
#37
1.10 Bibliographic Notes 37
There are also many books on data warehouse technology,
systems, and applica-
tions, such as The Data Warehouse Toolkit: The Complete
Guide to Dimensional Modeling
by Kimball and Ross [KR02]; The Data Warehouse Lifecycle
Toolkit by Kimball, Ross,
Thornthwaite, and Mundy [KRTM08]; Mastering Data
Warehouse Design: Relational
and Dimensional Techniques by Imhoff, Galemmo, and Geiger
[IGG03]; and Building
the Data Warehouse by Inmon [Inm96]. A set of research papers
on materialized views
and data warehouse implementations were collected in
Materialized Views: Techniques,
Implementations, and Applications by Gupta and Mumick
[GM99]. Chaudhuri and
Dayal [CD97] present an early comprehensive overview of data
warehouse technology.
Research results relating to data mining and data warehousing
have been pub-
lished in the proceedings of many international database
conferences, including the
ACM-SIGMOD International Conference on Management of
Data (SIGMOD), the
International Conference on Very Large Data Bases (VLDB),
the ACM SIGACT-
SIGMOD-SIGART Symposium on Principles of Database
Systems (PODS), the Inter-
national Conference on Data Engineering (ICDE), the](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-160-320.jpg)
![International Conference on
Extending Database Technology (EDBT), the International
Conference on Database
Theory (ICDT), the International Conference on Information
and Knowledge Man-
agement (CIKM), the International Conference on Database and
Expert Systems Appli-
cations (DEXA), and the International Symposium on Database
Systems for Advanced
Applications (DASFAA). Research in data mining is also
published in major database
journals, such as IEEE Transactions on Knowledge and Data
Engineering (TKDE), ACM
Transactions on Database Systems (TODS), Information
Systems, The VLDB Journal,
Data and Knowledge Engineering, International Journal of
Intelligent Information Systems
(JIIS), and Knowledge and Information Systems (KAIS).
Many effective data mining methods have been developed by
statisticians and intro-
duced in a rich set of textbooks. An overview of classification
from a statistical pattern
recognition perspective can be found in Pattern Classification
by Duda, Hart, and Stork
[DHS01]. There are also many textbooks covering regression
and other topics in statis-
tical analysis, such as Mathematical Statistics: Basic Ideas and
Selected Topics by Bickel
and Doksum [BD01]; The Statistical Sleuth: A Course in
Methods of Data Analysis by
Ramsey and Schafer [RS01]; Applied Linear Statistical Models
by Neter, Kutner, Nacht-
sheim, and Wasserman [NKNW96]; An Introduction to
Generalized Linear Models by
Dobson [Dob90]; Applied Statistical Time Series Analysis by](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-161-320.jpg)
![Shumway [Shu88]; and
Applied Multivariate Statistical Analysis by Johnson and
Wichern [JW92].
Research in statistics is published in the proceedings of several
major statistical con-
ferences, including Joint Statistical Meetings, International
Conference of the Royal
Statistical Society and Symposium on the Interface: Computing
Science and Statistics.
Other sources of publication include the Journal of the Royal
Statistical Society, The
Annals of Statistics, the Journal of American Statistical
Association, Technometrics, and
Biometrika.
Textbooks and reference books on machine learning and pattern
recognition include
Machine Learning by Mitchell [Mit97]; Pattern Recognition and
Machine Learning by
Bishop [Bis06]; Pattern Recognition by Theodoridis and
Koutroumbas [TK08]; Introduc-
tion to Machine Learning by Alpaydin [Alp11]; Probabilistic
Graphical Models: Principles
HAN 08-ch01-001-038-9780123814791 2011/6/1 3:12 Page 38
#38
38 Chapter 1 Introduction
and Techniques by Koller and Friedman [KF09]; and Machine
Learning: An Algorithmic
Perspective by Marsland [Mar09]. For an edited collection of
seminal articles on machine](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-162-320.jpg)
![learning, see Machine Learning, An Artificial Intelligence
Approach, Volumes 1 through 4,
edited by Michalski et al. [MCM83, MCM86, KM90, MT94],
and Readings in Machine
Learning by Shavlik and Dietterich [SD90].
Machine learning and pattern recognition research is published
in the proceed-
ings of several major machine learning, artificial intelligence,
and pattern recognition
conferences, including the International Conference on Machine
Learning (ML), the
ACM Conference on Computational Learning Theory (COLT),
the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), the
International Conference
on Pattern Recognition (ICPR), the International Joint
Conference on Artificial Intel-
ligence (IJCAI), and the American Association of Artificial
Intelligence Conference
(AAAI). Other sources of publication include major machine
learning, artificial intel-
ligence, pattern recognition, and knowledge system journals,
some of which have been
mentioned before. Others include Machine Learning (ML),
Pattern Recognition (PR),
Artificial Intelligence Journal (AI), IEEE Transactions on
Pattern Analysis and Machine
Intelligence (PAMI), and Cognitive Science.
Textbooks and reference books on information retrieval include
Introduction to
Information Retrieval by Manning, Raghavan, and Schutz
[MRS08]; Information
Retrieval: Implementing and Evaluating Search Engines by
Büttcher, Clarke, and Cormack](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-163-320.jpg)
![[BCC10]; Search Engines: Information Retrieval in Practice by
Croft, Metzler, and
Strohman [CMS09]; Modern Information Retrieval: The
Concepts and Technology Behind
Search by Baeza-Yates and Ribeiro-Neto [BYRN11]; and
Information Retrieval: Algo-
rithms and Heuristics by Grossman and Frieder [GR04].
Information retrieval research is published in the proceedings of
several informa-
tion retrieval and Web search and mining conferences, including
the International
ACM SIGIR Conference on Research and Development in
Information Retrieval
(SIGIR), the International World Wide Web Conference
(WWW), the ACM Interna-
tional Conference on Web Search and Data Mining (WSDM),
the ACM Conference on
Information and Knowledge Management (CIKM), the European
Conference on Infor-
mation Retrieval (ECIR), the Text Retrieval Conference
(TREC), and the ACM/IEEE
Joint Conference on Digital Libraries (JCDL). Other sources of
publication include
major information retrieval, information systems, and Web
journals, such as Journal
of Information Retrieval, ACM Transactions on Information
Systems (TOIS), Informa-
tion Processing and Management, Knowledge and Information
Systems (KAIS), and IEEE
Transactions on Knowledge and Data Engineering (TKDE).
HAN 09-ch02-039-082-9780123814791 2011/6/1 3:15 Page 39
#1](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-164-320.jpg)











































































![2.4.4 Dissimilarity of Numeric Data: Minkowski Distance
In this section, we describe distance measures that are
commonly used for computing
the dissimilarity of objects described by numeric attributes.
These measures include the
Euclidean, Manhattan, and Minkowski distances.
In some cases, the data are normalized before applying distance
calculations. This
involves transforming the data to fall within a smaller or
common range, such as [−1, 1]
or [0.0, 1.0]. Consider a height attribute, for example, which
could be measured in either
meters or inches. In general, expressing an attribute in smaller
units will lead to a larger
range for that attribute, and thus tend to give such attributes
greater effect or “weight.”
Normalizing the data attempts to give all attributes an equal
weight. It may or may not be
useful in a particular application. Methods for normalizing data
are discussed in detail
in Chapter 3 on data preprocessing.
The most popular distance measure is Euclidean distance (i.e.,
straight line or
“as the crow flies”). Let i = (xi1, xi2,..., xip) and j = (xj1,
xj2,..., xjp) be two objects
described by p numeric attributes. The Euclidean distance
between objects i and j is
defined as
d(i, j)=
√
(xi1 −xj1)2 +(xi2 −xj2)2 +···+(xip −xjp)2. (2.16)](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-240-320.jpg)





![attributes is
quite similar to that of numeric attributes when computing
dissimilarity between
objects. Suppose that f is an attribute from a set of ordinal
attributes describing
n objects. The dissimilarity computation with respect to f
involves the following
steps:
1. The value of f for the ith object is xif , and f has Mf ordered
states, representing the
ranking 1,..., Mf . Replace each xif by its corresponding rank,
rif ∈ {1,..., Mf }.
2. Since each ordinal attribute can have a different number of
states, it is often
necessary to map the range of each attribute onto [0.0, 1.0] so
that each attribute
has equal weight. We perform such data normalization by
replacing the rank rif
of the ith object in the f th attribute by
zif =
rif −1
Mf −1
. (2.21)
3. Dissimilarity can then be computed using any of the distance
measures described
in Section 2.4.4 for numeric attributes, using zif to represent the
f value for the ith
object.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-246-320.jpg)


![a common scale of the
interval [0.0, 1.0].
Suppose that the data set contains p attributes of mixed type.
The dissimilarity d(i, j)
between objects i and j is defined as
d(i, j)=
∑p
f =1 δ
(f )
ij d
(f )
ij∑p
f =1 δ
(f )
ij
, (2.22)
HAN 09-ch02-039-082-9780123814791 2011/6/1 3:15 Page 76
#38
76 Chapter 2 Getting to Know Your Data
where the indicator δ
(f )
ij = 0 if either (1) xif or xjf is missing (i.e., there is no mea-
surement of attribute f for object i or object j), or (2) xif = xjf =](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-249-320.jpg)

![attribute types. The only difference is for numeric attributes,
where we normalize so
that the values map to the interval [0.0, 1.0]. Thus, the
dissimilarity between objects
can be computed even when the attributes describing the objects
are of different
types.
Example 2.22 Dissimilarity between attributes of mixed type.
Let’s compute a dissimilarity matrix
for the objects in Table 2.2. Now we will consider all of the
attributes, which are of
different types. In Examples 2.17 and 2.21, we worked out the
dissimilarity matrices
for each of the individual attributes. The procedures we
followed for test-1 (which is
nominal) and test-2 (which is ordinal) are the same as outlined
earlier for processing
attributes of mixed types. Therefore, we can use the
dissimilarity matrices obtained for
test-1 and test-2 later when we compute Eq. (2.22). First,
however, we need to compute
the dissimilarity matrix for the third attribute, test-3 (which is
numeric). That is, we
must compute d
(3)
ij . Following the case for numeric attributes, we let maxhxh =
64 and
minhxh = 22. The difference between the two is used in Eq.
(2.22) to normalize the
values of the dissimilarity matrix. The resulting dissimilarity
matrix for test-3 is](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-251-320.jpg)












![2.7 Bibliographic Notes
Methods for descriptive data summarization have been studied
in the statistics literature
long before the onset of computers. Good summaries of
statistical descriptive data min-
ing methods include Freedman, Pisani, and Purves [FPP07] and
Devore [Dev95]. For
HAN 09-ch02-039-082-9780123814791 2011/6/1 3:15 Page 82
#44
82 Chapter 2 Getting to Know Your Data
statistics-based visualization of data using boxplots, quantile
plots, quantile–quantile
plots, scatter plots, and loess curves, see Cleveland [Cle93].
Pioneering work on data visualization techniques is described in
The Visual Dis-
play of Quantitative Information [Tuf83], Envisioning
Information [Tuf90], and Visual
Explanations: Images and Quantities, Evidence and Narrative
[Tuf97], all by Tufte, in
addition to Graphics and Graphic Information Processing by
Bertin [Ber81], Visualizing
Data by Cleveland [Cle93], and Information Visualization in
Data Mining and Knowledge
Discovery edited by Fayyad, Grinstein, and Wierse [FGW01].
Major conferences and symposiums on visualization include
ACM Human Factors
in Computing Systems (CHI), Visualization, and the
International Symposium on Infor-](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-264-320.jpg)
![mation Visualization. Research on visualization is also
published in Transactions on
Visualization and Computer Graphics, Journal of Computational
and Graphical Statistics,
and IEEE Computer Graphics and Applications.
Many graphical user interfaces and visualization tools have
been developed and can
be found in various data mining products. Several books on data
mining (e.g., Data
Mining
Solution
s by Westphal and Blaxton [WB98]) present many good
examples and
visual snapshots. For a survey of visualization techniques, see
“Visual techniques for
exploring databases” by Keim [Kei97].
Similarity and distance measures among various variables have
been introduced in
many textbooks that study cluster analysis, including Hartigan
[Har75]; Jain and Dubes
[JD88]; Kaufman and Rousseeuw [KR90]; and Arabie, Hubert,
and de Soete [AHS96].
Methods for combining attributes of different types into a single
dissimilarity matrix](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-265-320.jpg)
![were introduced by Kaufman and Rousseeuw [KR90].
HAN 10-ch03-083-124-9780123814791 2011/6/1 3:16 Page 83
#1
3Data Preprocessing
Today’s real-world databases are highly susceptible to noisy,
missing, and inconsistent data
due to their typically huge size (often several gigabytes or
more) and their likely origin
from multiple, heterogenous sources. Low-quality data will lead
to low-quality mining
results. “How can the data be preprocessed in order to help
improve the quality of the data
and, consequently, of the mining results? How can the data be
preprocessed so as to improve
the efficiency and ease of the mining process?”
There are several data preprocessing techniques. Data cleaning
can be applied to
remove noise and correct inconsistencies in data. Data
integration merges data from](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-266-320.jpg)











![tions using parametric models (e.g., regression or log-linear
models) or nonparametric
models (e.g., histograms, clusters, sampling, or data
aggregation). Data reduction is the
topic of Section 3.4.
Getting back to your data, you have decided, say, that you
would like to use a distance-
based mining algorithm for your analysis, such as neural
networks, nearest-neighbor
classifiers, or clustering.1 Such methods provide better results
if the data to be ana-
lyzed have been normalized, that is, scaled to a smaller range
such as [0.0, 1.0]. Your
customer data, for example, contain the attributes age and
annual salary. The annual
salary attribute usually takes much larger values than age.
Therefore, if the attributes
are left unnormalized, the distance measurements taken on
annual salary will generally
outweigh distance measurements taken on age. Discretization
and concept hierarchy gen-
eration can also be useful, where raw data values for attributes
are replaced by ranges or
higher conceptual levels. For example, raw values for age may](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-278-320.jpg)





































































![Several software packages exist to solve regression problems.
Examples include SAS
(www.sas.com), SPSS (www.spss.com), and S-Plus
(www.insightful.com). Another useful
resource is the book Numerical Recipes in C, by Press,
Teukolsky, Vetterling, and Flannery
[PTVF07], and its associated source code.
3.4.6 Histograms
Histograms use binning to approximate data distributions and
are a popular form
of data reduction. Histograms were introduced in Section 2.2.3.
A histogram for an
attribute, A, partitions the data distribution of A into disjoint
subsets, referred to as
buckets or bins. If each bucket represents only a single
attribute–value/frequency pair, the
buckets are called singleton buckets. Often, buckets instead
represent continuous ranges
for the given attribute.
Example 3.3 Histograms. The following data are a list of
AllElectronics prices for commonly sold
items (rounded to the nearest dollar). The numbers have been
sorted: 1, 1, 5, 5, 5,](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-348-320.jpg)


















![for the attribute price. More than one concept hierarchy can be
defined for the same
attribute to accommodate the needs of various users.
6. Concept hierarchy generation for nominal data, where
attributes such as street can
be generalized to higher-level concepts, like city or country.
Many hierarchies for
nominal attributes are implicit within the database schema and
can be automatically
defined at the schema definition level.
Recall that there is much overlap between the major data
preprocessing tasks. The first
three of these strategies were discussed earlier in this chapter.
Smoothing is a form of
($600...$800]
($800...$1000]($400...$600]($200...$400]($0...$200]
($0...$1000]
($900...
$1000]](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-368-320.jpg)
![($800...
$900]
($700...
$800]
($600...
$700]
($500...
$600]
($100...
$200]
($400...
$500]
($0...
$100]
($200...
$300]
($300...](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-369-320.jpg)
![$400]
Figure 3.12 A concept hierarchy for the attribute price, where
an interval ($X ...$Y ] denotes the range
from $X (exclusive) to $Y (inclusive).
HAN 10-ch03-083-124-9780123814791 2011/6/1 3:16 Page 113
#31
3.5 Data Transformation and Data Discretization 113
data cleaning and was addressed in Section 3.2.2. Section 3.2.3
on the data cleaning
process also discussed ETL tools, where users specify
transformations to correct data
inconsistencies. Attribute construction and aggregation were
discussed in Section 3.4
on data reduction. In this section, we therefore concentrate on
the latter three strategies.
Discretization techniques can be categorized based on how the
discretization is per-
formed, such as whether it uses class information or which](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-370-320.jpg)


![effect or “weight.” To help avoid dependence on the choice of
measurement units, the
data should be normalized or standardized. This involves
transforming the data to fall
within a smaller or common range such as [−1, 1] or [0.0, 1.0].
(The terms standardize
and normalize are used interchangeably in data preprocessing,
although in statistics, the
latter term also has other connotations.)
Normalizing the data attempts to give all attributes an equal
weight. Normaliza-
tion is particularly useful for classification algorithms involving
neural networks or
distance measurements such as nearest-neighbor classification
and clustering. If using
the neural network backpropagation algorithm for classification
mining (Chapter 9),
normalizing the input values for each attribute measured in the
training tuples will help
speed up the learning phase. For distance-based methods,
normalization helps prevent](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-373-320.jpg)

![i in the range [new minA, new maxA]
by computing
v′i =
vi −minA
maxA −minA
(new maxA −new minA)+new minA. (3.8)
Min-max normalization preserves the relationships among the
original data values. It
will encounter an “out-of-bounds” error if a future input case
for normalization falls
outside of the original data range for A.
Example 3.4 Min-max normalization. Suppose that the minimum
and maximum values for the
attribute income are $12,000 and $98,000, respectively. We
would like to map income
to the range [0.0, 1.0]. By min-max normalization, a value of
$73,600 for income is
transformed to 73,600−12,00098,000−12,000(1.0−0)+0 = 0.716.
In z-score normalization (or zero-mean normalization), the
values for an attribute,](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-375-320.jpg)

























![following:
(a) Use min-max normalization to transform the value 35 for
age onto the range
[0.0, 1.0].
(b) Use z-score normalization to transform the value 35 for age,
where the standard
deviation of age is 12.94 years.
(c) Use normalization by decimal scaling to transform the value
35 for age.
(d) Comment on which method you would prefer to use for the
given data, giving
reasons as to why.
HAN 10-ch03-083-124-9780123814791 2011/6/1 3:16 Page 122
#40
122 Chapter 3 Data Preprocessing
3.8 Using the data for age and body fat given in Exercise 2.4,](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-401-320.jpg)

![(a) stepwise forward selection
(b) stepwise backward elimination
(c) a combination of forward selection and backward
elimination
3.11 Using the data for age given in Exercise 3.3,
(a) Plot an equal-width histogram of width 10.
(b) Sketch examples of each of the following sampling
techniques: SRSWOR, SRSWR,
cluster sampling, and stratified sampling. Use samples of size 5
and the strata
“youth,” “middle-aged,” and “senior.”
3.12 ChiMerge [Ker92] is a supervised, bottom-up (i.e., merge-
based) data discretization
method. It relies on χ2 analysis: Adjacent intervals with the
least χ2 values are merged
together until the chosen stopping criterion satisfies.
(a) Briefly describe how ChiMerge works.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-403-320.jpg)


![Data preprocessing is discussed in a number of textbooks,
including English [Eng99],
Pyle [Pyl99], Loshin [Los01], Redman [Red01], and Dasu and
Johnson [DJ03]. More
specific references to individual preprocessing techniques are
given later.
For discussion regarding data quality, see Redman [Red92];
Wang, Storey, and
Firth [WSF95]; Wand and Wang [WW96]; Ballou and Tayi
[BT99]; and Olson [Ols03].
Potter’s Wheel (control.cx.berkely.edu/abc), the interactive data
cleaning tool described in
Section 3.2.3, is presented in Raman and Hellerstein [RH01].
An example of the devel-
opment of declarative languages for the specification of data
transformation operators is
given in Galhardas et al. [GFS+01]. The handling of missing
attribute values is discussed
in Friedman [Fri77]; Breiman, Friedman, Olshen, and Stone
[BFOS84]; and Quinlan
[Qui89]. Hua and Pei [HP07] presented a heuristic approach to
cleaning disguised miss-
ing data, where such data are captured when users falsely select
default values on forms](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-406-320.jpg)
![(e.g., “January 1” for birthdate) when they do not want to
disclose personal information.
A method for the detection of outlier or “garbage” patterns in a
handwritten char-
acter database is given in Guyon, Matic, and Vapnik [GMV96].
Binning and data
normalization are treated in many texts, including Kennedy et
al. [KLV+98], Weiss
and Indurkhya [WI98], and Pyle [Pyl99]. Systems that include
attribute (or feature)
construction include BACON by Langley, Simon, Bradshaw,
and Zytkow [LSBZ87];
Stagger by Schlimmer [Sch86]; FRINGE by Pagallo [Pag89];
and AQ17-DCI by Bloe-
dorn and Michalski [BM98]. Attribute construction is also
described in Liu and Motoda
[LM98a, LM98b]. Dasu et al. built a BELLMAN system and
proposed a set of interesting
methods for building a data quality browser by mining database
structures [DJMS02].
A good survey of data reduction techniques can be found in
Barbará et al. [BDF+97].
For algorithms on data cubes and their precomputation, see](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-407-320.jpg)
![Sarawagi and Stonebraker
[SS94]; Agarwal et al. [AAD+96]; Harinarayan, Rajaraman, and
Ullman [HRU96]; Ross
and Srivastava [RS97]; and Zhao, Deshpande, and Naughton
[ZDN97]. Attribute sub-
set selection (or feature subset selection) is described in many
texts such as Neter, Kutner,
Nachtsheim, and Wasserman [NKNW96]; Dash and Liu [DL97];
and Liu and Motoda
[LM98a, LM98b]. A combination forward selection and
backward elimination method
HAN 10-ch03-083-124-9780123814791 2011/6/1 3:16 Page 124
#42
124 Chapter 3 Data Preprocessing
was proposed in Siedlecki and Sklansky [SS88]. A wrapper
approach to attribute selec-
tion is described in Kohavi and John [KJ97]. Unsupervised
attribute subset selection is
described in Dash, Liu, and Yao [DLY97].](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-408-320.jpg)
![For a description of wavelets for dimensionality reduction, see
Press, Teukolosky, Vet-
terling, and Flannery [PTVF07]. A general account of wavelets
can be found in Hubbard
[Hub96]. For a list of wavelet software packages, see Bruce,
Donoho, and Gao [BDG96].
Daubechies transforms are described in Daubechies [Dau92].
The book by Press et al.
[PTVF07] includes an introduction to singular value
decomposition for principal com-
ponents analysis. Routines for PCA are included in most
statistical software packages
such as SAS (www.sas.com/SASHome.html).
An introduction to regression and log-linear models can be
found in several
textbooks such as James [Jam85]; Dobson [Dob90]; Johnson and
Wichern [JW92];
Devore [Dev95]; and Neter, Kutner, Nachtsheim, and
Wasserman [NKNW96]. For log-
linear models (known as multiplicative models in the computer
science literature), see
Pearl [Pea88]. For a general introduction to histograms, see
Barbará et al. [BDF+97]
and Devore and Peck [DP97]. For extensions of single-attribute](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-409-320.jpg)
![histograms to multiple
attributes, see Muralikrishna and DeWitt [MD88] and Poosala
and Ioannidis [PI97].
Several references to clustering algorithms are given in
Chapters 10 and 11 of this book,
which are devoted to the topic.
A survey of multidimensional indexing structures is given in
Gaede and Günther
[GG98]. The use of multidimensional index trees for data
aggregation is discussed in
Aoki [Aok98]. Index trees include R-trees (Guttman [Gut84]),
quad-trees (Finkel and
Bentley [FB74]), and their variations. For discussion on
sampling and data mining, see
Kivinen and Mannila [KM94] and John and Langley [JL96].
There are many methods for assessing attribute relevance. Each
has its own bias. The
information gain measure is biased toward attributes with many
values. Many alterna-
tives have been proposed, such as gain ratio (Quinlan [Qui93]),
which considers the
probability of each attribute value. Other relevance measures
include the Gini index](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-410-320.jpg)
![(Breiman, Friedman, Olshen, and Stone [BFOS84]), the χ2
contingency table statis-
tic, and the uncertainty coefficient (Johnson and Wichern
[JW92]). For a comparison
of attribute selection measures for decision tree induction, see
Buntine and Niblett
[BN92]. For additional methods, see Liu and Motoda [LM98a],
Dash and Liu [DL97],
and Almuallim and Dietterich [AD91].
Liu et al. [LHTD02] performed a comprehensive survey of data
discretization
methods. Entropy-based discretization with the C4.5 algorithm
is described in Quin-
lan [Qui93]. In Catlett [Cat91], the D-2 system binarizes a
numeric feature recursively.
ChiMerge by Kerber [Ker92] and Chi2 by Liu and Setiono
[LS95] are methods for the
automatic discretization of numeric attributes that both employ
the χ2 statistic. Fayyad
and Irani [FI93] apply the minimum description length principle
to determine the num-
ber of intervals for numeric discretization. Concept hierarchies
and their automatic
generation from categorical data are described in Han and Fu](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-411-320.jpg)
![[HF94].
HAN 11-ch04-125-186-9780123814791 2011/6/1 3:17 Page 125
#1
4Data Warehousing and OnlineAnalytical Processing
Data warehouses generalize and consolidate data in
multidimensional space. The construction
of data warehouses involves data cleaning, data integration, and
data transformation,
and can be viewed as an important preprocessing step for data
mining. Moreover, data
warehouses provide online analytical processing (OLAP) tools
for the interactive analysis
of multidimensional data of varied granularities, which
facilitates effective data gene-
ralization and data mining. Many other data mining functions,
such as association,
classification, prediction, and clustering, can be integrated with
OLAP operations to
enhance interactive mining of knowledge at multiple levels of
abstraction. Hence, the](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-412-320.jpg)




![decision making pro-
cess” [Inm96]. This short but comprehensive definition presents
the major features of
a data warehouse. The four keywords—subject-oriented,
integrated, time-variant, and
nonvolatile—distinguish data warehouses from other data
repository systems, such as
relational database systems, transaction processing systems, and
file systems.
Let’s take a closer look at each of these key features.
Subject-oriented: A data warehouse is organized around major
subjects such as cus-
tomer, supplier, product, and sales. Rather than concentrating
on the day-to-day
operations and transaction processing of an organization, a data
warehouse focuses
on the modeling and analysis of data for decision makers.
Hence, data warehouses
typically provide a simple and concise view of particular
subject issues by excluding
data that are not useful in the decision support process.
Integrated: A data warehouse is usually constructed by](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-417-320.jpg)













![DB size GB to high-order GB ≥ TB
Priority high performance, high availability high flexibility,
end-user autonomy
Metric transaction throughput query throughput, response time
Note: Table is partially based on Chaudhuri and Dayal [CD97].
support requires historic data, whereas operational databases do
not typically maintain
historic data. In this context, the data in operational databases,
though abundant, are
usually far from complete for decision making. Decision
support requires consolidation
(e.g., aggregation and summarization) of data from
heterogeneous sources, resulting
in high-quality, clean, integrated data. In contrast, operational
databases contain only
detailed raw data, such as transactions, which need to be
consolidated before analy-
sis. Because the two systems provide quite different
functionalities and require different
kinds of data, it is presently necessary to maintain separate
databases. However, many](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-431-320.jpg)



















































![144 Chapter 4 Data Warehousing and Online Analytical
Processing
($0 $1000]
($800 $1000]
($0 …
$100]
($100…
$200]
($800…
$900]
($900…
$1000]
($600…
$700]
($700…
$800]](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-483-320.jpg)
![($200…
$300]
($300…
$400]
($400…
$500]
($500…
$600]
($600 $800]($400 $600]($200 $400]($0 $200]
Figure 4.11 A concept hierarchy for price.
be organized in a partial order, forming a lattice. An example of
a partial order for the
time dimension based on the attributes day, week, month,
quarter, and year is “day <
{month < quarter; week} < year.”1 This lattice structure is
shown in Figure 4.10(b).
A concept hierarchy that is a total or partial order among
attributes in a database schema
is called a schema hierarchy. Concept hierarchies that are](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-484-320.jpg)
![common to many applica-
tions (e.g., for time) may be predefined in the data mining
system. Data mining systems
should provide users with the flexibility to tailor predefined
hierarchies according to
their particular needs. For example, users may want to define a
fiscal year starting on
April 1 or an academic year starting on September 1.
Concept hierarchies may also be defined by discretizing or
grouping values for a
given dimension or attribute, resulting in a set-grouping
hierarchy. A total or partial
order can be defined among groups of values. An example of a
set-grouping hierarchy is
shown in Figure 4.11 for the dimension price, where an interval
($X . . . $Y ] denotes the
range from $X (exclusive) to $Y (inclusive).
There may be more than one concept hierarchy for a given
attribute or dimension,
based on different user viewpoints. For instance, a user may
prefer to organize price by
defining ranges for inexpensive, moderately priced, and
expensive.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-485-320.jpg)























































![of total sales”) is a zero-
dimensional operation. An SQL query containing one group-by
(e.g., “compute the sum
of sales, group-by city”) is a one-dimensional operation. A cube
operator on n dimensions
is equivalent to a collection of group-by statements, one for
each subset of the n dimen-
sions. Therefore, the cube operator is the n-dimensional
generalization of the group-by
operator.
Similar to the SQL syntax, the data cube in Example 4.1 could
be defined as
define cube sales cube [city, item, year]: sum(sales in dollars)
For a cube with n dimensions, there are a total of 2n cuboids,
including the base cuboid.
A statement such as
compute cube sales cube
would explicitly instruct the system to compute the sales
aggregate cuboids for all eight
subsets of the set {city, item, year}, including the empty subset.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-542-320.jpg)
![A cube computation
operator was first proposed and studied by Gray et al.
[GCB+97].
Online analytical processing may need to access different
cuboids for different
queries. Therefore, it may seem like a good idea to compute in
advance all or at least
some of the cuboids in a data cube. Precomputation leads to fast
response time and
avoids some redundant computation. Most, if not all, OLAP
products resort to some
degree of precomputation of multidimensional aggregates.
A major challenge related to this precomputation, however, is
that the required stor-
age space may explode if all the cuboids in a data cube are
precomputed, especially when
the cube has many dimensions. The storage requirements are
even more excessive when
many of the dimensions have associated concept hierarchies,
each with multiple levels.
This problem is referred to as the curse of dimensionality. The
extent of the curse of
dimensionality is illustrated here.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-543-320.jpg)















![HAN 11-ch04-125-186-9780123814791 2011/6/1 3:17 Page 162
#38
162 Chapter 4 Data Warehousing and Online Analytical
Processing
indexing maintains relationships between attribute values of a
dimension (e.g., within
a dimension table) and the corresponding rows in the fact table.
Join indices may span
multiple dimensions to form composite join indices. We can use
join indices to identify
subcubes that are of interest.
Example 4.8 Join indexing. In Example 3.4, we defined a star
schema for AllElectronics of the form
“sales star [time, item, branch, location]: dollars sold = sum
(sales in dollars).” An exam-
ple of a join index relationship between the sales fact table and
the location and item
dimension tables is shown in Figure 4.16. For example, the
“Main Street” value in the
location dimension table joins with tuples T57, T238, and T884](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-559-320.jpg)




![knowledge of “domi-
nance” relationships among the cuboids, estimating the costs of
using the remaining
materialized cuboids, and selecting the cuboid with the least
cost.
Example 4.9 OLAP query processing. Suppose that we define a
data cube for AllElectronics of the
form “sales cube [time, item, location]: sum(sales in dollars).”
The dimension hierarchies
used are “day < month < quarter < year” for time; “item name <
brand < type” for
item; and “street < city < province or state < country” for
location.
Suppose that the query to be processed is on {brand, province or
state}, with the
selection constant “year = 2010.” Also, suppose that there are
four materialized cuboids
available, as follows:
cuboid 1: {year, item name, city}
cuboid 2: {year, brand, country}](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-564-320.jpg)




























































![(a) Enumerate three classes of schemas that are popularly used
for modeling data
warehouses.
(b) Draw a schema diagram for the above data warehouse using
one of the schema
classes listed in (a).
HAN 11-ch04-125-186-9780123814791 2011/6/1 3:17 Page 181
#57
4.7 Exercises 181
(c) Starting with the base cuboid [day, doctor, patient ], what
specific OLAP operations
should be performed in order to list the total fee collected by
each doctor in 2010?
(d) To obtain the same list, write an SQL query assuming the
data are stored in a rela-
tional database with the schema fee (day, month, year, doctor,
hospital, patient, count,](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-625-320.jpg)
![charge).
4.4 Suppose that a data warehouse for Big University consists
of the four dimensions stu-
dent, course, semester, and instructor, and two measures count
and avg grade. At the
lowest conceptual level (e.g., for a given student, course,
semester, and instructor com-
bination), the avg grade measure stores the actual course grade
of the student. At higher
conceptual levels, avg grade stores the average grade for the
given combination.
(a) Draw a snowflake schema diagram for the data warehouse.
(b) Starting with the base cuboid [student , course, semester,
instructor], what specific
OLAP operations (e.g., roll-up from semester to year) should
you perform in order
to list the average grade of CS courses for each Big University
student.
(c) If each dimension has five levels (including all), such as
“student < major < status <
university < all”, how many cuboids will this cube contain](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-626-320.jpg)
![(including the base and
apex cuboids)?
4.5 Suppose that a data warehouse consists of the four
dimensions date, spectator, location,
and game, and the two measures count and charge, where charge
is the fare that a spec-
tator pays when watching a game on a given date. Spectators
may be students, adults, or
seniors, with each category having its own charge rate.
(a) Draw a star schema diagram for the data warehouse.
(b) Starting with the base cuboid [date, spectator, location,
game], what specific OLAP
operations should you perform in order to list the total charge
paid by student
spectators at GM Place in 2010?
(c) Bitmap indexing is useful in data warehousing. Taking this
cube as an example,
briefly discuss advantages and problems of using a bitmap index
structure.
4.6 A data warehouse can be modeled by either a star schema or](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-627-320.jpg)









![(b) What is the minimum number of cells possible in the base
cuboid?
(c) What is the maximum number of cells possible (including
both base cells and
aggregate cells) in the C data cube?
(d) What is the minimum number of cells possible in C?
4.17 What are the differences between the three main types of
data warehouse usage: infor-
mation processing, analytical processing, and data mining ?
Discuss the motivation behind
OLAP mining (OLAM).
4.8 Bibliographic Notes
There are a good number of introductory-level textbooks on
data warehousing and
OLAP technology—for example, Kimball, Ross, Thornthwaite,
et al. [KRTM08];
Imhoff, Galemmo, and Geiger [IGG03]; and Inmon [Inm96].
Chaudhuri and Dayal
[CD97] provide an early overview of data warehousing and
OLAP technology. A set of](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-637-320.jpg)
![research papers on materialized views and data warehouse
implementations were col-
lected in Materialized Views: Techniques, Implementations, and
Applications by Gupta
and Mumick [GM99].
The history of decision support systems can be traced back to
the 1960s. However,
the proposal to construct large data warehouses for
multidimensional data analysis is
credited to Codd [CCS93] who coined the term OLAP for online
analytical processing.
The OLAP Council was established in 1995. Widom [Wid95]
identified several research
problems in data warehousing. Kimball and Ross [KR02]
provide an overview of the
deficiencies of SQL regarding the ability to support
comparisons that are common in the
business world, and present a good set of application cases that
require data warehousing
and OLAP technology. For an overview of OLAP systems
versus statistical databases, see
Shoshani [Sho97].
Gray et al. [GCB+97] proposed the data cube as a relational](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-638-320.jpg)
![aggregation operator
generalizing group-by, crosstabs, and subtotals. Harinarayan,
Rajaraman, and Ullman
[HRU96] proposed a greedy algorithm for the partial
materialization of cuboids in the
computation of a data cube. Data cube computation methods
have been investigated by
numerous studies such as Sarawagi and Stonebraker [SS94];
Agarwal et al. [AAD+96];
Zhao, Deshpande, and Naughton [ZDN97]; Ross and Srivastava
[RS97]; Beyer and
Ramakrishnan [BR99]; Han, Pei, Dong, and Wang [HPDW01];
and Xin, Han, Li, and
Wah [XHLW03]. These methods are discussed in depth in
Chapter 5.
The concept of iceberg queries was first introduced in Fang,
Shivakumar, Garcia-
Molina et al. [FSGM+98]. The use of join indices to speed up
relational query processing
was proposed by Valduriez [Val87]. O’Neil and Graefe [OG95]
proposed a bitmapped](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-639-320.jpg)
![HAN 11-ch04-125-186-9780123814791 2011/6/1 3:17 Page 185
#61
4.8 Bibliographic Notes 185
join index method to speed up OLAP-based query processing. A
discussion of the per-
formance of bitmapping and other nontraditional index
techniques is given in O’Neil
and Quass [OQ97].
For work regarding the selection of materialized cuboids for
efficient OLAP query
processing, see, for example, Chaudhuri and Dayal [CD97];
Harinarayan, Rajaraman,
and Ullman [HRU96]; and Sristava et al. [SDJL96]. Methods for
cube size estimation
can be found in Deshpande et al. [DNR+97], Ross and
Srivastava [RS97], and Beyer and
Ramakrishnan [BR99]. Agrawal, Gupta, and Sarawagi [AGS97]
proposed operations for
modeling multidimensional databases. Methods for answering
queries quickly by online
aggregation are described in Hellerstein, Haas, and Wang
[HHW97] and Hellerstein](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-640-320.jpg)
![et al. [HAC+99]. Techniques for estimating the top N queries
are proposed in Carey
and Kossman [CK98] and Donjerkovic and Ramakrishnan
[DR99]. Further studies on
intelligent OLAP and discovery-driven exploration of data
cubes are presented in the
bibliographic notes in Chapter 5.
EDELKAMP 19-ch15-671-700-9780123725127 2011/5/28 14:50
Page 672 #2
This page intentionally left blank
HAN 12-ch05-187-242-9780123814791 2011/6/1 3:19 Page 187
#1
5Data Cube Technology
Data warehouse systems provide online analytical processing
(OLAP) tools for interactive
analysis of multidimensional data at varied granularity levels.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-641-320.jpg)

























![computes iceberg cubes from
the apex cuboid downward. Section 5.2.3 describes the Star-
Cubing method, which
integrates top-down and bottom-up computation.
Finally, Section 5.2.4 describes a shell-fragment cubing
approach that computes shell
fragments for efficient high-dimensional OLAP. To simplify our
discussion, we exclude
3The Apriori property was proposed in the Apriori algorithm for
association rule mining by Agrawal
and Srikant [AS94b]. Many algorithms in association rule
mining have adopted this property (see
Chapter 6).
4 Antimonotone is based on condition violation. This differs
from monotone, which is based on
condition satisfaction.
HAN 12-ch05-187-242-9780123814791 2011/6/1 3:19 Page 195
#9
5.2 Data Cube Computation Methods 195](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-667-320.jpg)




























![HAN 12-ch05-187-242-9780123814791 2011/6/1 3:19 Page 202
#16
202 Chapter 5 Data Cube Technology
Algorithm: BUC. Algorithm for the computation of sparse and
iceberg cubes.
Input:
input : the relation to aggregate;
dim: the starting dimension for this iteration.
Globals:
constant numDims: the total number of dimensions;
constant cardinality[numDims]: the cardinality of each
dimension;
constant min sup: the minimum number of tuples in a partition
for it to be output;
outputRec: the current output record;](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-696-320.jpg)
![dataCount[numDims]: stores the size of each partition.
dataCount[i] is a list of integers
of size cardinality[i].
Output: Recursively output the iceberg cube cells satisfying the
minimum support.
Method:
(1) Aggregate(input); // Scan input to compute measure, e.g.,
count. Place result in outputRec.
(2) if input.count() == 1 then // Optimization
WriteDescendants(input[0], dim); return;
endif
(3) write outputRec;
(4) for (d = dim; d < numDims; d ++) do //Partition each
dimension
(5) C = cardinality[d];
(6) Partition(input, d, C, dataCount[d]); //create C partitions of
data for dimension d
(7) k = 0;
(8) for (i = 0; i < C; i++) do // for each partition (each value of](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-697-320.jpg)
![dimension d)
(9) c = dataCount[d][i];
(10) if c >= min sup then // test the iceberg condition
(11) outputRec.dim[d] = input[k].dim[d];
(12) BUC(input[k..k +c −1], d +1); // aggregate on next
dimension
(13) endif
(14) k +=c;
(15) endfor
(16) outputRec.dim[d] = all;
(17) endfor
Figure 5.6 BUC algorithm for sparse or iceberg cube
computation. Source: Beyer and Ramakrishnan
[BR99].
Suppose (a1, ∗ , ∗ , ∗ ) satisfies the minimum support, in
which case a recursive call is
made on the partition for a1. BUC partitions a1 on the
dimension B. It checks the count
of (a1, b1, ∗ , ∗ ) to see if it satisfies the minimum support. If it
does, it outputs the aggre-
gated tuple to the AB group-by and recurses on (a1, b1, ∗ , ∗ )
to partition on C, starting](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-698-320.jpg)

























































































![which no concept hierarchy has been defined (e.g., gender,
salary). Let Y be the class-
label attribute (e.g., valued customer), and Z be the set of
multilevel attributes, that is,
attributes for which concept hierarchies have been defined (e.g.,
time, location). Let V
be the set of attributes for which we would like to define their
predictiveness. In our
example, this set is {gender}. The predictiveness of V on a data
subset can be quantified
by the difference in accuracy between the model built on that
subset using X to predict Y
and the model built on that subset using X−V (e.g., {salary}) to
predict Y. The intuition
is that, if the difference is large, V must play an important role
in the prediction of class
label Y.
Given a set of attributes, V, and a learning algorithm, the
prediction cube at granular-
ity 〈l1,..., ld〉 (e.g., 〈year, state〉) is a d-dimensional array, in
which the value in each cell
(e.g., [2010, Illinois]) is the predictiveness of V evaluated on
the subset defined by the
cell (e.g., the records in the customer table with time in 2010](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-788-320.jpg)





























![d is a specialization of
cell c (i.e., d is obtained by replacing a ∗ in c by a non-∗
value) and d has the same
measure value as c. A closed cube is a data cube consisting of
only closed cells. How
many closed cells are in the full cube?
5.2 There are several typical cube computation methods, such as
MultiWay [ZDN97], BUC
[BR99], and Star-Cubing [XHLW03]. Briefly describe these
three methods (i.e., use one
or two lines to outline the key points), and compare their
feasibility and performance
under the following conditions:
(a) Computing a dense full cube of low dimensionality (e.g.,
less than eight
dimensions).
(b) Computing an iceberg cube of around 10 dimensions with a
highly skewed data
distribution.
(c) Computing a sparse iceberg cube of high dimensionality
(e.g., over 100 dimensions).](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-824-320.jpg)





![(city), departure time, arrival, arrival time, and flight; and two
measures: count( ) and
avg fare( ), where avg fare( ) stores the concrete fare at the
lowest level but the average fare
at other levels.
(a) Suppose the cube is fully materialized. Starting with the
base cuboid [traveler, depar-
ture, departure time, arrival, arrival time, flight ], what specific
OLAP operations
(e.g., roll-up flight to airline) should one perform to list the
average fare per month
for each business traveler who flies American Airlines (AA)
from Los Angeles in 2009?
HAN 12-ch05-187-242-9780123814791 2011/6/1 3:19 Page 238
#52
238 Chapter 5 Data Cube Technology
(b) Suppose we want to compute a data cube where the
condition is that the minimum
number of records is 10 and the average fare is over $500.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-830-320.jpg)
![Outline an efficient cube
computation method (based on common sense about flight data
distribution).
5.11 (Implementation project) There are four typical data cube
computation methods: Mul-
tiWay [ZDN97], BUC [BR99], H-Cubing [HPDW01], and Star-
Cubing [XHLW03].
(a) Implement any one of these cube computation algorithms
and describe your
implementation, experimentation, and performance. Find
another student who has
implemented a different algorithm on the same platform (e.g.,
C++ on Linux) and
compare your algorithm performance with his or hers.
Input:
i. An n-dimensional base cuboid table (for n < 20), which is
essentially a relational
table with n attributes.
ii. An iceberg condition: count (C)≥ k, where k is a positive
integer as a parameter.
Output:](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-831-320.jpg)







![whether a point should be considered interesting enough to be
marked. Suppose one
would like to mark those objects of which the absolute value of
z score is over 2 in every
row and column in a d-dimensional plane.
(a) Derive an efficient computation method to identify such
points during the data cube
computation.
(b) Suppose a partially materialized cube has (d −1)-
dimensional and (d +1)-
dimensional cuboids materialized but not the d-dimensional one.
Derive an efficient
method to mark those (d −1)-dimensional cells with d-
dimensional children that
contain such marked points.
5.7 Bibliographic Notes
Efficient computation of multidimensional aggregates in data
cubes has been studied
by many researchers. Gray, Chaudhuri, Bosworth, et al.
[GCB+97] proposed cube-by as
a relational aggregation operator generalizing group-by,
crosstabs, and subtotals, and](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-839-320.jpg)
![categorized data cube measures into three categories:
distributive, algebraic, and holis-
tic. Harinarayan, Rajaraman, and Ullman [HRU96] proposed a
greedy algorithm for
the partial materialization of cuboids in the computation of a
data cube. Sarawagi and
Stonebraker [SS94] developed a chunk-based computation
technique for the efficient
organization of large multidimensional arrays. Agarwal,
Agrawal, Deshpande, et al.
[AAD+96] proposed several guidelines for efficient
computation of multidimensional
aggregates for ROLAP servers.
The chunk-based MultiWay array aggregation method for data
cube computation in
MOLAP was proposed in Zhao, Deshpande, and Naughton
[ZDN97]. Ross and Srivas-
tava [RS97] developed a method for computing sparse data
cubes. Iceberg queries are
first described in Fang, Shivakumar, Garcia-Molina, et al.
[FSGM+98]. BUC, a scalable
method that computes iceberg cubes from the apex cuboid
downwards, was introduced
by Beyer and Ramakrishnan [BR99]. Han, Pei, Dong, and Wang](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-840-320.jpg)
![[HPDW01] introduced
an H-Cubing method for computing iceberg cubes with complex
measures using an
H-tree structure.
The Star-Cubing method for computing iceberg cubes with a
dynamic star-tree struc-
ture was introduced by Xin, Han, Li, and Wah [XHLW03]. MM-
Cubing, an efficient
HAN 12-ch05-187-242-9780123814791 2011/6/1 3:19 Page 241
#55
5.7 Bibliographic Notes 241
iceberg cube computation method that factorizes the lattice
space was developed by
Shao, Han, and Xin [SHX04]. The shell-fragment-based cubing
approach for efficient
high-dimensional OLAP was proposed by Li, Han, and Gonzalez
[LHG04].
Aside from computing iceberg cubes, another way to reduce](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-841-320.jpg)
![data cube computa-
tion is to materialize condensed, dwarf, or quotient cubes,
which are variants of closed
cubes. Wang, Feng, Lu, and Yu proposed computing a reduced
data cube, called a con-
densed cube [WLFY02]. Sismanis, Deligiannakis,
Roussopoulos, and Kotids proposed
computing a compressed data cube, called a dwarf cube
[SDRK02]. Lakeshmanan,
Pei, and Han proposed a quotient cube structure to summarize a
data cube’s seman-
tics [LPH02], which has been further extended to a qc-tree
structure by Lakshmanan,
Pei, and Zhao [LPZ03]. An aggregation-based approach, called
C-Cubing (i.e., Closed-
Cubing ), has been developed by Xin, Han, Shao, and Liu
[XHSL06], which performs
efficient closed-cube computation by taking advantage of a new
algebraic measure
closedness.
There are also various studies on the computation of
compressed data cubes by
approximation, such as quasi-cubes by Barbara and Sullivan
[BS97]; wavelet cubes by](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-842-320.jpg)
![Vitter, Wang, and Iyer [VWI98]; compressed cubes for query
approximation on continu-
ous dimensions by Shanmugasundaram, Fayyad, and Bradley
[SFB99]; using log-linear
models to compress data cubes by Barbara and Wu [BW00]; and
OLAP over uncertain
and imprecise data by Burdick, Deshpande, Jayram, et al.
[BDJ+05].
For works regarding the selection of materialized cuboids for
efficient OLAP query
processing, see Chaudhuri and Dayal [CD97]; Harinarayan,
Rajaraman, and Ullman
[HRU96]; Srivastava, Dar, Jagadish, and Levy [SDJL96]; Gupta
[Gup97], Baralis,
Paraboschi, and Teniente [BPT97]; and Shukla, Deshpande, and
Naughton [SDN98].
Methods for cube size estimation can be found in Deshpande,
Naughton, Ramasamy,
et al. [DNR+97], Ross and Srivastava [RS97], and Beyer and
Ramakrishnan [BR99].
Agrawal, Gupta, and Sarawagi [AGS97] proposed operations for
modeling multidimen-
sional databases.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-843-320.jpg)
![Data cube modeling and computation have been extended well
beyond relational
data. Computation of stream cubes for multidimensional stream
data analysis has been
studied by Chen, Dong, Han, et al. [CDH+02]. Efficient
computation of spatial data
cubes was examined by Stefanovic, Han, and Koperski
[SHK00], efficient OLAP in spa-
tial data warehouses was studied by Papadias, Kalnis, Zhang,
and Tao [PKZT01], and a
map cube for visualizing spatial data warehouses was proposed
by Shekhar, Lu, Tan, et al.
[SLT+01]. A multimedia data cube was constructed in
MultiMediaMiner by Zaiane,
Han, Li, et al. [ZHL+98]. For analysis of multidimensional text
databases, TextCube,
based on the vector space model, was proposed by Lin, Ding,
Han, et al. [LDH+08],
and TopicCube, based on a topic modeling approach, was
proposed by Zhang, Zhai, and
Han [ZZH09]. RFID Cube and FlowCube for analyzing RFID
data were proposed by
Gonzalez, Han, Li, et al. [GHLK06, GHL06].
The sampling cube was introduced for analyzing sampling data](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-844-320.jpg)
![by Li, Han, Yin, et al.
[LHY+08]. The ranking cube was proposed by Xin, Han, Cheng,
and Li [XHCL06]
for efficient processing of ranking (top-k) queries in databases.
This methodology has
been extended by Wu, Xin, and Han [WXH08] to ARCube,
which supports the ranking
of aggregate queries in partially materialized data cubes. It has
also been extended by
HAN 12-ch05-187-242-9780123814791 2011/6/1 3:19 Page 242
#56
242 Chapter 5 Data Cube Technology
Wu, Xin, Mei, and Han [WXMH09] to PromoCube, which
supports promotion query
analysis in multidimensional space.
The discovery-driven exploration of OLAP data cubes was
proposed by Sarawagi,
Agrawal, and Megiddo [SAM98]. Further studies on integration
of OLAP with data min-](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-845-320.jpg)
![ing capabilities for intelligent exploration of multidimensional
OLAP data were done by
Sarawagi and Sathe [SS01]. The construction of multifeature
data cubes is described by
Ross, Srivastava, and Chatziantoniou [RSC98]. Methods for
answering queries quickly
by online aggregation are described by Hellerstein, Haas, and
Wang [HHW97] and
Hellerstein, Avnur, Chou, et al. [HAC+99]. A cube-gradient
analysis problem, called
cubegrade, was first proposed by Imielinski, Khachiyan, and
Abdulghani [IKA02]. An
efficient method for multidimensional constrained gradient
analysis in data cubes was
studied by Dong, Han, Lam, et al. [DHL+01].
Mining cube space, or integration of knowledge discovery and
OLAP cubes, has
been studied by many researchers. The concept of online
analytical mining (OLAM),
or OLAP mining, was introduced by Han [Han98]. Chen, Dong,
Han, et al. devel-
oped a regression cube for regression-based multidimensional
analysis of time-series data
[CDH+02, CDH+06]. Fagin, Guha, Kumar, et al. [FGK+05]](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-846-320.jpg)
![studied data mining in
multistructured databases. B.-C. Chen, L. Chen, Lin, and
Ramakrishnan [CCLR05] pro-
posed prediction cubes, which integrate prediction models with
data cubes to discover
interesting data subspaces for facilitated prediction. Chen,
Ramakrishnan, Shavlik, and
Tamma [CRST06] studied the use of data mining models as
building blocks in a multi-
step mining process, and the use of cube space to intuitively
define the space of interest
for predicting global aggregates from local regions.
Ramakrishnan and Chen [RC07]
presented an organized picture of exploratory mining in cube
space.
HAN 13-ch06-243-278-9780123814791 2011/6/1 3:20 Page 243
#1
6Mining Frequent Patterns,Associations, and Correlations:Basic
Concepts and Methods
Imagine that you are a sales manager at AllElectronics, and you
are talking to a customer who](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-847-320.jpg)








![computer ⇒ antivirus software [support = 2%, confidence =
60%]. (6.1)
Rule support and confidence are two measures of rule
interestingness. They respec-
tively reflect the usefulness and certainty of discovered rules. A
support of 2% for
Rule (6.1) means that 2% of all the transactions under analysis
show that computer
and antivirus software are purchased together. A confidence of
60% means that 60% of
the customers who purchased a computer also bought the
software. Typically, associa-
tion rules are considered interesting if they satisfy both a
minimum support threshold
and a minimum confidence threshold. These thresholds can be a
set by users or
domain experts. Additional analysis can be performed to
discover interesting statistical
correlations between associated items.
HAN 13-ch06-243-278-9780123814791 2011/6/1 3:20 Page 246
#4](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-856-320.jpg)












![Section 6.1.1. We begin by
presenting Apriori, the basic algorithm for finding frequent
itemsets (Section 6.2.1). In
Section 6.2.2, we look at how to generate strong association
rules from frequent item-
sets. Section 6.2.3 describes several variations to the Apriori
algorithm for improved
efficiency and scalability. Section 6.2.4 presents pattern-growth
methods for mining
frequent itemsets that confine the subsequent search space to
only the data sets contain-
ing the current frequent itemsets. Section 6.2.5 presents
methods for mining frequent
itemsets that take advantage of the vertical data format.
6.2.1 Apriori Algorithm: Finding Frequent Itemsets
by Confined Candidate Generation
Apriori is a seminal algorithm proposed by R. Agrawal and R.
Srikant in 1994 for min-
ing frequent itemsets for Boolean association rules [AS94b].
The name of the algorithm
is based on the fact that the algorithm uses prior knowledge of
frequent itemset prop-
erties, as we shall see later. Apriori employs an iterative](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-869-320.jpg)


![followed, consisting of join
and prune actions.
1. The join step: To find Lk , a set of candidate k-itemsets is
generated by joining
Lk−1 with itself. This set of candidates is denoted Ck . Let l1
and l2 be itemsets
in Lk−1. The notation li [j] refers to the jth item in li (e.g., l1[k
−2] refers to
the second to the last item in l1). For efficient implementation,
Apriori assumes
that items within a transaction or itemset are sorted in
lexicographic order. For
the (k −1)-itemset, li , this means that the items are sorted such
that li [1] < li [2]
< ···< li [k −1]. The join, Lk−1 1 Lk−1, is performed, where
members of Lk−1 are
joinable if their first (k −2) items are in common. That is,
members l1 and l2
of Lk−1 are joined if (l1[1] = l2[1])∧ (l1[2] = l2[2])∧ ···∧ (l1[k
−2] = l2[k −2])
∧ (l1[k −1] < l2[k −1]). The condition l1[k −1] < l2[k −1]
simply ensures that
no duplicates are generated. The resulting itemset formed by
joining l1 and l2 is](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-872-320.jpg)
![{l1[1], l1[2],..., l1[k −2], l1[k −1], l2[k −1]}.
2. The prune step: Ck is a superset of Lk , that is, its members
may or may not be
frequent, but all of the frequent k-itemsets are included in Ck .
A database scan to
determine the count of each candidate in Ck would result in the
determination of
Lk (i.e., all candidates having a count no less than the minimum
support count are
frequent by definition, and therefore belong to Lk ). Ck ,
however, can be huge, and so
this could involve heavy computation. To reduce the size of Ck
, the Apriori property
6The Apriori property has many applications. For example, it
can also be used to prune search during
data cube computation (Chapter 5).
SUUSER
Highlight
SUUSER
Highlight](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-873-320.jpg)










![(1) for each itemset l1 ∈ Lk−1
(2) for each itemset l2 ∈ Lk−1
(3) if (l1[1] = l2[1])∧ (l1[2] = l2[2])
∧ ...∧ (l1[k −2] = l2[k −2])∧ (l1[k −1] < l2[k −1]) then {
(4) c = l1 1 l2; // join step: generate candidates
(5) if has infrequent subset(c, Lk−1) then
(6) delete c; // prune step: remove unfruitful candidate
(7) else add c to Ck ;
(8) }
(9) return Ck ;
procedure has infrequent subset(c: candidate k-itemset;
Lk−1: frequent (k −1)-itemsets); // use prior knowledge
(1) for each (k −1)-subset s of c
(2) if s 6∈ Lk−1 then
(3) return TRUE;
(4) return FALSE;
Figure 6.4 Apriori algorithm for discovering frequent itemsets
for mining Boolean association rules.
A procedure can then be called to generate association rules
from the frequent itemsets.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-884-320.jpg)


























![Output: The complete set of frequent patterns.
Method:
1. The FP-tree is constructed in the following steps:
(a) Scan the transaction database D once. Collect F , the set of
frequent items, and their
support counts. Sort F in support count descending order as L,
the list of frequent items.
(b) Create the root of an FP-tree, and label it as “null.” For each
transaction Trans in D do the
following.
Select and sort the frequent items in Trans according to the
order of L. Let the sorted
frequent item list in Trans be [p|P], where p is the first element
and P is the remaining
list. Call insert tree([p|P], T), which is performed as follows. If
T has a child N such that
N.item-name = p.item-name, then increment N ’s count by 1;
else create a new node N ,
and let its count be 1, its parent link be linked to T , and its
node-link to the nodes with
the same item-name via the node-link structure. If P is](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-911-320.jpg)

















![minimum support of, say, 30%
and a minimum confidence of 60%. The following association
rule is discovered:
buys(X , “computer games”)⇒ buys(X , “videos”)
[support = 40%, confidence = 66%]. (6.6)
Rule (6.6) is a strong association rule and would therefore be
reported, since its support
value of 400010,000 = 40% and confidence value of
4000
6000 = 66% satisfy the minimum support
and minimum confidence thresholds, respectively. However,
Rule (6.6) is misleading
because the probability of purchasing videos is 75%, which is
even larger than 66%. In
fact, computer games and videos are negatively associated
because the purchase of one
of these items actually decreases the likelihood of purchasing
the other. Without fully
understanding this phenomenon, we could easily make unwise
business decisions based](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-929-320.jpg)
![on Rule (6.6).
Example 6.7 also illustrates that the confidence of a rule A ⇒ B
can be deceiving. It
does not measure the real strength (or lack of strength) of the
correlation and implica-
tion between A and B. Hence, alternatives to the support–
confidence framework can be
useful in mining interesting data relationships.
6.3.2 From Association Analysis to Correlation Analysis
As we have seen so far, the support and confidence measures
are insufficient at filtering
out uninteresting association rules. To tackle this weakness, a
correlation measure can
be used to augment the support–confidence framework for
association rules. This leads
to correlation rules of the form
A ⇒ B [support, confidence, correlation]. (6.7)
That is, a correlation rule is measured not only by its support
and confidence but also
by the correlation between itemsets A and B. There are many
different correlation mea-](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-930-320.jpg)






























![item3) [s, c]
6.7 (Implementation project) Using a programming language
that you are familiar
with, such as C++ or Java, implement three frequent itemset
mining algorithms
introduced in this chapter: (1) Apriori [AS94b], (2) FP-growth
[HPY00], and
(3) Eclat [Zak00] (mining using the vertical data format).
Compare the perfor-
mance of each algorithm with various kinds of large data sets.
Write a report to
analyze the situations (e.g., data size, data distribution, minimal
support thresh-
old setting, and pattern density) where one algorithm may
perform better than the
others, and state why.
6.8 A database has four transactions. Let min sup = 60% and
min conf = 80%.
cust ID TID items bought (in the form of brand-item category)
01 T100 {King’s-Crab, Sunset-Milk, Dairyland-Cheese, Best-
Bread}](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-961-320.jpg)
![02 T200 {Best-Cheese, Dairyland-Milk, Goldenfarm-Apple,
Tasty-Pie, Wonder-Bread}
01 T300 {Westcoast-Apple, Dairyland-Milk, Wonder-Bread,
Tasty-Pie}
03 T400 {Wonder-Bread, Sunset-Milk, Dairyland-Cheese}
(a) At the granularity of item category (e.g., itemi could be
“Milk”), for the rule
template,
∀ X ∈ transaction, buys(X , item1)∧ buys(X , item2)⇒ buys(X ,
item3) [s, c],
list the frequent k-itemset for the largest k, and all the strong
association rules
(with their support s and confidence c) containing the frequent
k-itemset for the
largest k.
(b) At the granularity of brand-item category (e.g., itemi could
be “Sunset-Milk”),
for the rule template,](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-962-320.jpg)






![are a good number of authors that have coauthor relationships.
(a) Propose a method to efficiently mine a set of coauthor
relationships that are
closely correlated (e.g., often coauthoring papers together).
(b) Based on the mining results and the pattern evaluation
measures discussed in
this chapter, discuss which measure may convincingly uncover
close collabora-
tion patterns better than others.
(c) Based on the study in (a), develop a method that can roughly
predict advi-
sor and advisee relationships and the approximate period for
such advisory
supervision.
6.6 Bibliographic Notes
Association rule mining was first proposed by Agrawal,
Imielinski, and Swami [AIS93].
The Apriori algorithm discussed in Section 6.2.1 for frequent
itemset mining was pre-
sented in Agrawal and Srikant [AS94b]. A variation of the
algorithm using a similar](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-969-320.jpg)
![pruning heuristic was developed independently by Mannila,
Tiovonen, and Verkamo
HAN 13-ch06-243-278-9780123814791 2011/6/1 3:20 Page 277
#35
6.6 Bibliographic Notes 277
[MTV94]. A joint publication combining these works later
appeared in Agrawal,
Mannila, Srikant et al. [AMS+96]. A method for generating
association rules from
frequent itemsets is described in Agrawal and Srikant [AS94a].
References for the variations of Apriori described in Section
6.2.3 include the
following. The use of hash tables to improve association mining
efficiency was stud-
ied by Park, Chen, and Yu [PCY95a]. The partitioning
technique was proposed by
Savasere, Omiecinski, and Navathe [SON95]. The sampling
approach is discussed in
Toivonen [Toi96]. A dynamic itemset counting approach is](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-970-320.jpg)
![given in Brin, Motwani,
Ullman, and Tsur [BMUT97]. An efficient incremental updating
of mined association
rules was proposed by Cheung, Han, Ng, and Wong [CHNW96].
Parallel and dis-
tributed association data mining under the Apriori framework
was studied by Park,
Chen, and Yu [PCY95b]; Agrawal and Shafer [AS96]; and
Cheung, Han, Ng, et al.
[CHN+96]. Another parallel association mining method, which
explores itemset clus-
tering using a vertical database layout, was proposed in Zaki,
Parthasarathy, Ogihara,
and Li [ZPOL97].
Other scalable frequent itemset mining methods have been
proposed as alterna-
tives to the Apriori-based approach. FP-growth, a pattern-
growth approach for mining
frequent itemsets without candidate generation, was proposed
by Han, Pei, and Yin
[HPY00] (Section 6.2.4). An exploration of hyper structure
mining of frequent patterns,
called H-Mine, was proposed by Pei, Han, Lu, et al. [PHL+01].
A method that integrates](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-971-320.jpg)
![top-down and bottom-up traversal of FP-trees in pattern-growth
mining was proposed
by Liu, Pan, Wang, and Han [LPWH02]. An array-based
implementation of prefix-
tree structure for efficient pattern growth mining was proposed
by Grahne and Zhu
[GZ03b]. Eclat, an approach for mining frequent itemsets by
exploring the vertical data
format, was proposed by Zaki [Zak00]. A depth-first generation
of frequent itemsets by
a tree projection technique was proposed by Agarwal,
Aggarwal, and Prasad [AAP01].
An integration of association mining with relational database
systems was studied by
Sarawagi, Thomas, and Agrawal [STA98].
The mining of frequent closed itemsets was proposed in
Pasquier, Bastide, Taouil,
and Lakhal [PBTL99], where an Apriori-based algorithm called
A-Close for such min-
ing was presented. CLOSET, an efficient closed itemset mining
algorithm based on
the frequent pattern growth method, was proposed by Pei, Han,
and Mao [PHM00].
CHARM by Zaki and Hsiao [ZH02] developed a compact](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-972-320.jpg)
![vertical TID list structure
called diffset, which records only the difference in the TID list
of a candidate pattern
from its prefix pattern. A fast hash-based approach is also used
in CHARM to prune
nonclosed patterns. CLOSET+ by Wang, Han, and Pei [WHP03]
integrates previously
proposed effective strategies as well as newly developed
techniques such as hybrid tree-
projection and item skipping. AFOPT, a method that explores a
right push operation on
FP-trees during the mining process, was proposed by Liu, Lu,
Lou, and Yu [LLLY03].
Grahne and Zhu [GZ03b] proposed a prefix-tree–based
algorithm integrated with
array representation, called FPClose, for mining closed itemsets
using a pattern-growth
approach.
Pan, Cong, Tung, et al. [PCT+03] proposed CARPENTER, a
method for finding
closed patterns in long biological data sets, which integrates the
advantages of vertical](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-973-320.jpg)
![HAN 13-ch06-243-278-9780123814791 2011/6/1 3:20 Page 278
#36
278 Chapter 6 Mining Frequent Patterns, Associations, and
Correlations
data formats and pattern growth methods. Mining max-patterns
was first studied by
Bayardo [Bay98], where MaxMiner, an Apriori-based, level-
wise, breadth-first search
method, was proposed to find max-itemset by performing
superset frequency pruning
and subset infrequency pruning for search space reduction.
Another efficient method,
MAFIA, developed by Burdick, Calimlim, and Gehrke [BCG01],
uses vertical bitmaps
to compress TID lists, thus improving the counting efficiency.
A FIMI (Frequent Itemset
Mining Implementation) workshop dedicated to implementation
methods for frequent
itemset mining was reported by Goethals and Zaki [GZ03a].
The problem of mining interesting rules has been studied by
many researchers.](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-974-320.jpg)
![The statistical independence of rules in data mining was studied
by Piatetski-Shapiro
[P-S91]. The interestingness problem of strong association rules
is discussed in Chen,
Han, and Yu [CHY96]; Brin, Motwani, and Silverstein
[BMS97]; and Aggarwal and
Yu [AY99], which cover several interestingness measures,
including lift. An efficient
method for generalizing associations to correlations is given in
Brin, Motwani, and
Silverstein [BMS97]. Other alternatives to the support–
confidence framework for assess-
ing the interestingness of association rules are proposed in Brin,
Motwani, Ullman, and
Tsur [BMUT97] and Ahmed, El-Makky, and Taha [AEMT00].
A method for mining strong gradient relationships among
itemsets was proposed
by Imielinski, Khachiyan, and Abdulghani [IKA02]. Silverstein,
Brin, Motwani, and
Ullman [SBMU98] studied the problem of mining causal
structures over transaction
databases. Some comparative studies of different interestingness
measures were done by
Hilderman and Hamilton [HH01]. The notion of null transaction](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-975-320.jpg)
![invariance was intro-
duced, together with a comparative analysis of interestingness
measures, by Tan, Kumar,
and Srivastava [TKS02]. The use of all confidence as a
correlation measure for generating
interesting association rules was studied by Omiecinski [Omi03]
and by Lee, Kim, Cai,
and Han [LKCH03]. Wu, Chen, and Han [WCH10] introduced
the Kulczynski measure
for associative patterns and performed a comparative analysis of
a set of measures for
pattern evaluation.
HAN 14-ch07-279-326-9780123814791 2011/6/1 3:21 Page 279
#1
7Advanced Pattern Mining
Frequent pattern mining has reached far beyond the basics due
to substantial research, numer-
ous extensions of the problem scope, and broad application
studies. In this chapter, you
will learn methods for advanced pattern mining. We begin by](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-976-320.jpg)






















![computer”). Both “computer”
and “laptop computer” are found to be frequent, whereas
“desktop computer” is not.
When a uniform minimum support threshold is used, the search
procedure is
simplified. The method is also simple in that users are required
to specify only
computer [support = 10%]
laptop computer [support = 6%]
Level 1
min_sup = 5%
Level 2
min_sup = 5%
desktop computer [support = 4%]
Figure 7.3 Multilevel mining with uniform support.
computer [support = 10%]](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-999-320.jpg)
![laptop computer [support = 6%]
Level 1
min_sup = 5%
Level 2
min_sup = 3%
desktop computer [support = 4%]
Figure 7.4 Multilevel mining with reduced support.
HAN 14-ch07-279-326-9780123814791 2011/6/1 3:21 Page 286
#8
286 Chapter 7 Advanced Pattern Mining
one minimum support threshold. An Apriori-like optimization
technique can be
adopted, based on the knowledge that an ancestor is a superset
of its descendants:
The search avoids examining itemsets containing any item of
which the ancestors do](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1000-320.jpg)



![HAN 14-ch07-279-326-9780123814791 2011/6/1 3:21 Page 287
#9
7.2 Pattern Mining in Multilevel, Multidimensional Space 287
where X is a variable representing customers who purchased
items in AllElectronics
transactions.
buys(X , “laptop computer”)⇒ buys(X , “HP printer”)
[support = 8%, confidence = 70%] (7.4)
buys(X , “Dell laptop computer”)⇒ buys(X , “HP printer”)
[support = 2%, confidence = 72%] (7.5)
“If Rules (7.4) and (7.5) are both mined, then how useful is
Rule (7.5)? Does it really
provide any novel information?” If the latter, less general rule
does not provide new infor-
mation, then it should be removed. Let’s look at how this may
be determined. A rule R1](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1004-320.jpg)





























































































































![possible, such as by
utilizing type information. In the DBLP data set, for example,
authors, conferences,
terms, and papers form multi-typed data. Develop a method for
automated semantic
pattern annotation that makes good use of typed information.
7.9 Bibliographic Notes
This chapter described various ways in which the basic
techniques of frequent itemset
mining (presented in Chapter 6) have been extended. One line
of extension is mining
multilevel and multidimensional association rules. Multilevel
association mining was
studied in Srikant and Agrawal [SA95] and Han and Fu [HF95].
In Srikant and Agrawal
[SA95], such mining was studied in the context of generalized
association rules, and an R-
interest measure was proposed for removing redundant rules.
Mining multidimensional
association rules using static discretization of quantitative
attributes and data cubes was
studied by Kamber, Han, and Chiang [KHC97].
Another line of extension is to mine patterns on numeric](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1130-320.jpg)
![attributes. Srikant and
Agrawal [SA96] proposed a nongrid-based technique for mining
quantitative associa-
tion rules, which uses a measure of partial completeness.
Mining quantitative association
rules based on rule clustering was proposed by Lent, Swami,
and Widom [LSW97].
Techniques for mining quantitative rules based on x-monotone
and rectilinear regions
were presented by Fukuda, Morimoto, Morishita, and Tokuyama
[FMMT96] and Yoda,
Fukuda, Morimoto, et al. [YFM+97]. Mining (distance-based)
association rules over
interval data was proposed by Miller and Yang [MY97].
Aumann and Lindell [AL99]
studied the mining of quantitative association rules based on a
statistical theory to
present only those rules that deviate substantially from normal
data.
Mining rare patterns by pushing group-based constraints was
proposed by Wang,
He, and Han [WHH00]. Mining negative association rules was
discussed by Savasere,
Omiecinski, and Navathe [SON98] and by Tan, Steinbach, and](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1131-320.jpg)
![Kumar [TSK05].
Constraint-based mining directs the mining process toward
patterns that are likely
of interest to the user. The use of metarules as syntactic or
semantic filters defining the
form of interesting single-dimensional association rules was
proposed in Klemettinen,
Mannila, Ronkainen, et al. [KMR+94]. Metarule-guided mining,
where the metarule
consequent specifies an action (e.g., Bayesian clustering or
plotting) to be applied to
the data satisfying the metarule antecedent, was proposed in
Shen, Ong, Mitbander,
HAN 14-ch07-279-326-9780123814791 2011/6/1 3:21 Page 324
#46
324 Chapter 7 Advanced Pattern Mining
and Zaniolo [SOMZ96]. A relation-based approach to metarule-
guided mining of
association rules was studied in Fu and Han [FH95].](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1132-320.jpg)
![Methods for constraint-based mining using pattern pruning
constraints were stud-
ied by Ng, Lakshmanan, Han, and Pang [NLHP98];
Lakshmanan, Ng, Han, and Pang
[LNHP99]; and Pei, Han, and Lakshmanan [PHL01]. Constraint-
based pattern min-
ing by data reduction using data pruning constraints was studied
by Bonchi, Giannotti,
Mazzanti, and Pedreschi [BGMP03] and Zhu, Yan, Han, and Yu
[ZYHY07]. An efficient
method for mining constrained correlated sets was given in
Grahne, Lakshmanan, and
Wang [GLW00]. A dual mining approach was proposed by
Bucila, Gehrke, Kifer, and
White [BGKW03]. Other ideas involving the use of templates or
predicate constraints
in mining have been discussed in Anand and Kahn [AK93];
Dhar and Tuzhilin [DT93];
Hoschka and Klösgen [HK91]; Liu, Hsu, and Chen [LHC97];
Silberschatz and Tuzhilin
[ST96]; and Srikant, Vu, and Agrawal [SVA97].
Traditional pattern mining methods encounter challenges when
mining high-](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1133-320.jpg)
![dimensional patterns, with applications like bioinformatics. Pan,
Cong, Tung, et al.
[PCT+03] proposed CARPENTER, a method for finding closed
patterns in high-
dimensional biological data sets, which integrates the
advantages of vertical data formats
and pattern growth methods. Pan, Tung, Cong, and Xu
[PTCX04] proposed COBBLER,
which finds frequent closed itemsets by integrating row
enumeration with column enu-
meration. Liu, Han, Xin, and Shao [LHXS06] proposed TDClose
to mine frequent
closed patterns in high-dimensional data by starting from the
maximal rowset, inte-
grated with a row-enumeration tree. It uses the pruning power
of the minimum support
threshold to reduce the search space. For mining rather long
patterns, called colossal
patterns, Zhu, Yan, Han, et al. [ZYH+07] developed a core
Pattern-Fusion method that
leaps over an exponential number of intermediate patterns to
reach colossal patterns.
To generate a reduced set of patterns, recent studies have
focused on mining com-](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1134-320.jpg)
![pressed sets of frequent patterns. Closed patterns can be viewed
as a lossless compression
of frequent patterns, whereas maximal patterns can be viewed as
a simple lossy com-
pression of frequent patterns. Top-k patterns, such as by Wang,
Han, Lu, and Tsvetkov
[WHLT05], and error-tolerant patterns, such as by Yang,
Fayyad, and Bradley [YFB01],
are alternative forms of interesting patterns. Afrati, Gionis, and
Mannila [AGM04] pro-
posed to use k-itemsets to cover a collection of frequent
itemsets. For frequent itemset
compression, Yan, Cheng, Han, and Xin [YCHX05] proposed a
profile-based approach,
and Xin, Han, Yan, and Cheng [XHYC05] proposed a
clustering-based approach. By
taking into consideration both pattern significance and pattern
redundancy, Xin, Cheng,
Yan, and Han [XCYH06] proposed a method for extracting
redundancy-aware top-k
patterns.
Automated semantic annotation of frequent patterns is useful
for explaining the
meaning of patterns. Mei, Xin, Cheng, et al. [MXC+07] studied](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1135-320.jpg)
![methods for semantic
annotation of frequent patterns.
An important extension to frequent itemset mining is mining
sequence and struc-
tural data. This includes mining sequential patterns (Agrawal
and Srikant [AS95];
Pei, Han, Mortazavi-Asl, et al. [PHM-A+01, PHM-A+04]; and
Zaki [Zak01]); min-
ing frequent espisodes (Mannila, Toivonen, and Verkamo
[MTV97]); mining structural
HAN 14-ch07-279-326-9780123814791 2011/6/1 3:21 Page 325
#47
7.9 Bibliographic Notes 325
patterns (Inokuchi, Washio, and Motoda [IWM98]; Kuramochi
and Karypis [KK01];
and Yan and Han [YH02]); mining cyclic association rules
(Özden, Ramaswamy, and
Silberschatz [ORS98]); intertransaction association rule mining
(Lu, Han, and Feng](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1136-320.jpg)
![[LHF98]); and calendric market basket analysis (Ramaswamy,
Mahajan, and Silber-
schatz [RMS98]). Mining such patterns is considered an
advanced topic and readers
are referred to these sources.
Pattern mining has been extended to help effective data
classification and cluster-
ing. Pattern-based classification (Liu, Hsu, and Ma [LHM98]
and Cheng, Yan, Han,
and Hsu [CYHH07]) is discussed in Chapter 9. Pattern-based
cluster analysis (Agrawal,
Gehrke, Gunopulos, and Raghavan [AGGR98] and H. Wang, W.
Wang, Yang, and Yu
[WWYY02]) is discussed in Chapter 11.
Pattern mining also helps many other data analysis and
processing tasks such as
cube gradient mining and discriminative analysis (Imielinski,
Khachiyan, and Abdul-
ghani [IKA02]; Dong, Han, Lam, et al. [DHL+04]; Ji, Bailey,
and Dong [JBD05]),
discriminative pattern-based indexing (Yan, Yu, and Han
[YYH05]), and discriminative
pattern-based similarity search (Yan, Zhu, Yu, and Han](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1137-320.jpg)
![[YZYH06]).
Pattern mining has been extended to mining spatial, temporal,
time-series, and
multimedia data, and data streams. Mining spatial association
rules or spatial collo-
cation rules was studied by Koperski and Han [KH95]; Xiong,
Shekhar, Huang, et al.
[XSH+04]; and Cao, Mamoulis, and Cheung [CMC05]. Pattern-
based mining of time-
series data is discussed in Shieh and Keogh [SK08] and Ye and
Keogh [YK09]. There
are many studies on pattern-based mining of multimedia data
such as Zaı̈ ane, Han, and
Zhu [ZHZ00] and Yuan, Wu, and Yang [YWY07]. Methods for
mining frequent pat-
terns on stream data have been proposed by many researchers,
including Manku and
Motwani [MM02]; Karp, Papadimitriou, and Shenker [KPS03];
and Metwally, Agrawal,
and El Abbadi [MAE05]. These pattern mining methods are
considered advanced topics.
Pattern mining has broad applications. Application areas
include computer science](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1138-320.jpg)
![such as software bug analysis, sensor network mining, and
performance improvement
of operating systems. For example, CP-Miner by Li, Lu,
Myagmar, and Zhou [LLMZ04]
uses pattern mining to identify copy-pasted code for bug
isolation. PR-Miner by Li and
Zhou [LZ05] uses pattern mining to extract application-specific
programming rules
from source code. Discriminative pattern mining is used for
program failure detection to
classify software behaviors (Lo, Cheng, Han, et al. [LCH+09])
and for troubleshooting
in sensor networks (Khan, Le, Ahmadi, et al. [KLA+08]).
EDELKAMP 19-ch15-671-700-9780123725127 2011/5/28 14:50
Page 672 #2
This page intentionally left blank
HAN 15-ch08-327-392-9780123814791 2011/6/1 3:21 Page 327
#1](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1139-320.jpg)








































![13 middle aged high yes fair yes
14 senior medium no excellent no
Example 8.1 Induction of a decision tree using information
gain. Table 8.1 presents a training set,
D, of class-labeled tuples randomly selected from the
AllElectronics customer database.
(The data are adapted from Quinlan [Qui86]. In this example,
each attribute is discrete-
valued. Continuous-valued attributes have been generalized.)
The class label attribute,
buys computer, has two distinct values (namely, {yes, no});
therefore, there are two dis-
tinct classes (i.e., m = 2). Let class C1 correspond to yes and
class C2 correspond to no.
There are nine tuples of class yes and five tuples of class no. A
(root) node N is created
for the tuples in D. To find the splitting criterion for these
tuples, we must compute
the information gain of each attribute. We first use Eq. (8.1) to
compute the expected
information needed to classify a tuple in D:](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1180-320.jpg)
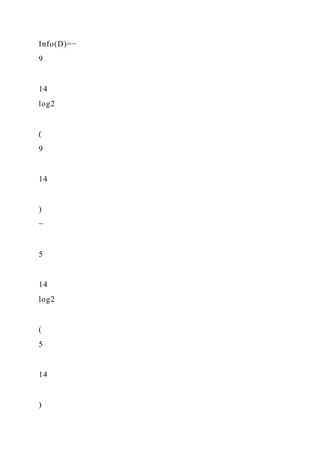



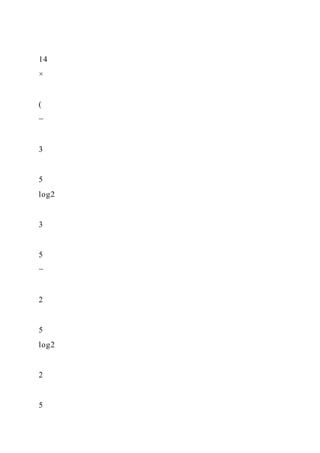









































![window displays the decision tree constructed so far. Initially,
the complete training set
is visualized in the Data Interaction window, while the
Knowledge Interaction window
displays an empty decision tree.
Traditional decision tree algorithms allow only binary splits for
numeric attributes.
PBC, however, allows the user to specify multiple split-points,
resulting in multiple
branches to be grown from a single tree node.
Figure 8.9 A screenshot of PBC, a system for interactive
decision tree construction. Multidimensional
training data are viewed as circle segments in the Data
Interaction window (left ). The Know-
ledge Interaction window (right ) displays the current decision
tree. Source: From Ankerst,
Elsen, Ester, and Kriegel [AEEK99].
HAN 15-ch08-327-392-9780123814791 2011/6/1 3:21 Page 350
#24](https://image.slidesharecdn.com/runningheadcapstoneprojectpart31capstoneprojectpart-221019033340-d734ac60/85/Running-head-CAPSTONE-PROJECT-PART-31CAPSTONE-PROJECT-PART-docx-1227-320.jpg)