2
RPM 패키징의 장점I
IIRPM 패키징에 필요한 정보
III RPM 패키징 프로세스
IV 소스파일 준비 및 빌드환경 준비
목차
V SPEC 파일 정의
VI 패키징
3.
3
컴포넌트의 설명 /Version 관리 / 패키지 그룹 / Project URL 및 기타 정보 포함 가능
yum repository를 통하여 클라이언트가 쉽게 소프트웨어를 검색 가능
클라이언트가 yum / rpm / PackageKit 등을 이용하여 손쉽게 소프트웨어를 설치 가능
새로운 버전의 소프트웨어를 쉽게 업데이트 / 배포 / 삭제 가능
RPM 패키징의 장점
4.
4
RPM 커맨드 및옵션 / Text 에디터 사용 방법에 대한 지식이 필요
패키징 하고자 하는 소프트웨어의 설치 위치 / Documents / 구성 파일에 대한 지식 필요
각 파일에 대한 소유자 / 권한 등의 설정이 필요
의존성이 있는 파일이나 다른 패키지에 대한 정보
이전 / 신규 changeLog 정보
RPM 패키징에 필요한 정보
5.
5
RPM 패키징 프로세스
소스파일 준비
• *.tar.gz 등의 소스파일
• 컴파일 하기위한 소스 파일
• 기타 패키징에 필요한 파일 준비
SPEC 파일 작성 • SPEC 파일 작성 방법에 따라 작성
RPM 빌드 • rpmbuild 커맨드를 통하여 rpm 패키징 완료
빌드 환경 준비
• 빌드 유저 생성
• rpm-build 패키지 설치
6.
6
유저 생성 및rpm-build 패키지 설치
소스파일 준비 및 빌드환경 준비
# useradd builduser
# yum install rpm-build
빌드 디렉토리 생성
소스의 압축을 풀어서 컴파일 하는 디렉토리
소스 RPM이 만들어지는 디렉토리
SPEC 파일이 위치하는 디렉토리
패키징할 압축된 소스파일과 패치를 넣어두는 디렉토리
아키텍처별로 하위 디렉토리가 추가로 생성 되고 하위 디렉토리 및에 RPM 바이너리 파일이 생성 됨
# mkdir -p ~/rpmbuild/{BUILD, BUILDROOT, RPMS ,SOURCES ,SPECS ,SRPMS}
패키징하기전에 패키징할 파일들을 옮겨놓는 디렉토리
7.
7
SPEC 파일 정의– 매크로
%define version 1.0.0
%define name osc-repository
version 이라는 매크로를 정의
name 이라는 패크로를 정의
주로 최상단에 먼저 정의 함
매크로를 정의하면 spec 파일 내부에서 %{매크로명}과 같은 형식으로 참조 가능
상기 매크로에 기반하여 %{version} 이라는 항목이 spec 파일내에서 모두 1.0.0.으로 치환 됨
상기 매크로에 기반하여 %{name} 이라는 항목이 spec 파일내에서 모두 osc-repository로 치환 됨
8.
8
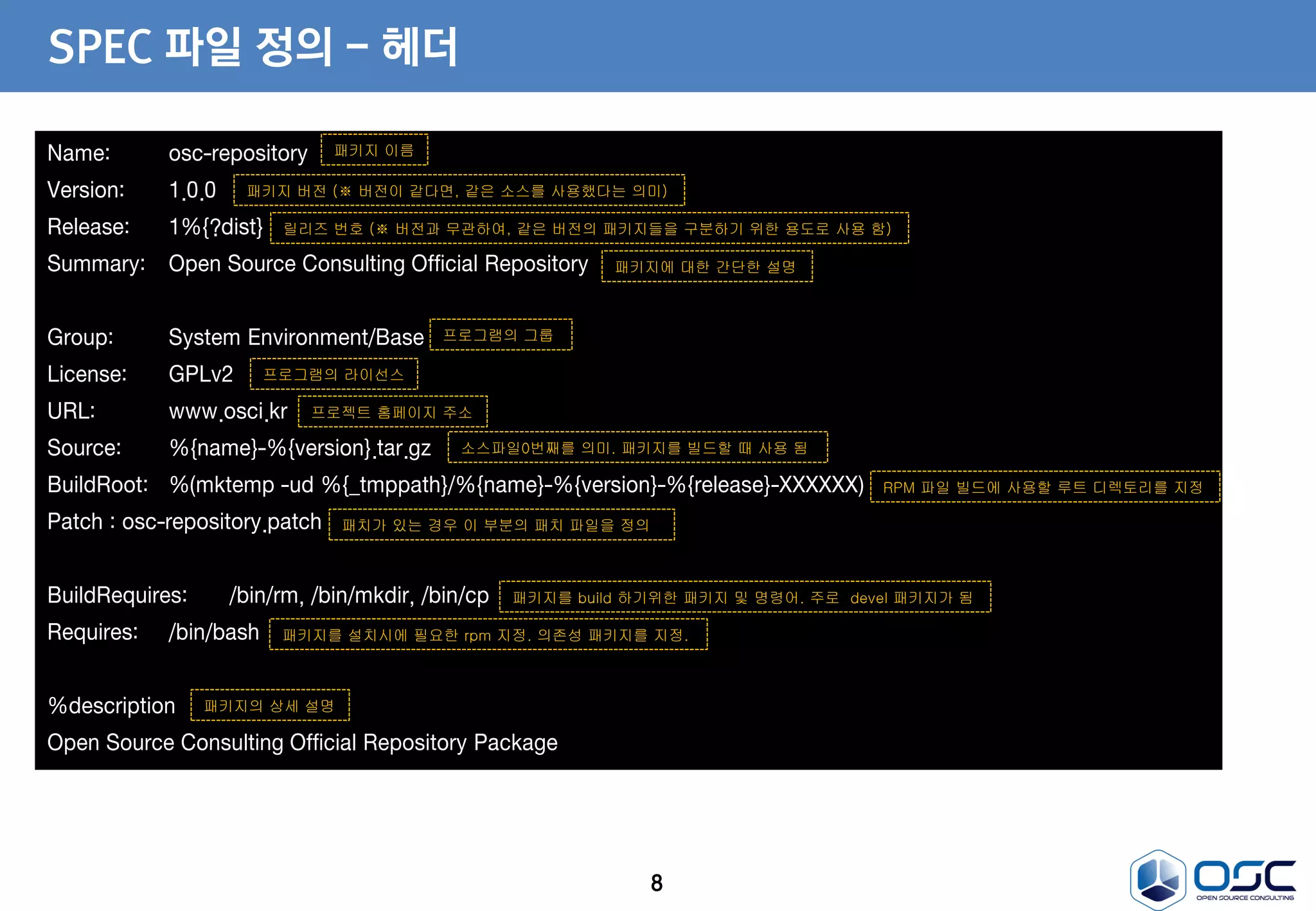
SPEC 파일 정의- 헤더
Name: osc-repository
Version: 1.0.0
Release: 1%{?dist}
Summary: Open Source Consulting Official Repository
Group: System Environment/Base
License: GPLv2
URL: www.osci.kr
Source: %{name}-%{version}.tar.gz
BuildRoot: %(mktemp -ud %{_tmppath}/%{name}-%{version}-%{release}-XXXXXX)
Patch : osc-repository.patch
BuildRequires: /bin/rm, /bin/mkdir, /bin/cp
Requires: /bin/bash
%description
Open Source Consulting Official Repository Package
패키지 이름
패키지 버전 (※ 버전이 같다면, 같은 소스를 사용했다는 의미)
릴리즈 번호 (※ 버전과 무관하여, 같은 버전의 패키지들을 구분하기 위한 용도로 사용 함)
패키지에 대한 간단한 설명
프로그램의 그룹
프로그램의 라이선스
프로젝트 홈페이지 주소
소스파일0번째를 의미. 패키지를 빌드할 때 사용 됨
RPM 파일 빌드에 사용할 루트 디렉토리를 지정
패치가 있는 경우 이 부분의 패치 파일을 정의
패키지를 build 하기위한 패키지 및 명령어. 주로 devel 패키지가 됨
패키지를 설치시에 필요한 rpm 지정. 의존성 패키지를 지정.
패키지의 상세 설명
9.
9
SPEC 파일 정의- 명령실행
%prep
%setup
%build
%install
install -Dpm 644 RPM-GPG-KEY-OSC-REPO $RPM_BUILD_ROOT%{_sysconfdir}/pki/rpm-gpg/RPM-GPG-KEY-OSC-
REPO
install -Dpm 644 osc.repo $RPM_BUILD_ROOT%{_sysconfdir}/yum.repos.d/osc.repo
%clean
rm -rf $RPM_BUILD_ROOT
%files
%{_sysconfdir}/pki/rpm-gpg/RPM-GPG-KEY-OSC-REPO
%{_sysconfdir}/yum.repos.d/osc.repo
압축을 풀고 압축 푼 디렉토리로 경로를 이동하기 위한 명령을 명시
%setup은 미리 명시된 내부 매크로이며 소스로 지정된 tar 파일의 압축을 풀고 해당 경로로 이동하는 작업 까지 진행
프로그램 빌드를 위한 명령을 기재. 컴파일이 필요한 경우 ./configure 커맨드를 비롯한 빌드 옵션을 기재 함
컴파일 된 프로그램을 설치하는 부분
RPM으로 패키징 될 파일을 하나씩 지정 하는 부분
RPM 패키지를 다 만들고 어떤 작업을 하는지 지정하는 부분
SPEC 파일에 명시되지 않은 %(_sysconfigdir}은 /usr/lib/rpm/macros 파일에 선언 됨
install 사용법은 install <옵션> <소스> <목적지> 이며 소스파일을 목적지로 파일을 복사하는 역할을 수행
%RPM_BUILD_ROOT 는 SPEC 파일에 BUILDROOT에 명시한 경로 이며, %{_sysconfdir}은 /usr/lib/rpm/macros에
명시된 /etc 이다.
10.
10
SPEC 파일 정의- ChangeLog
%changelog
* Tue Jan 26 2016 hipark <hipark@osci.kr> - 1-1
- First Release
RPM으로 패키징 될 파일을 하나씩 지정 하는 부분
changelog는 변경된 부분을 적는 곳
아래의 양식을 지켜서 기재할 것
%changelog
* [ 날짜 ] [ 이름 ] [e-mail]
- [ 바뀐 내용 1]
- [ 바뀐 내용 2]
11.
11
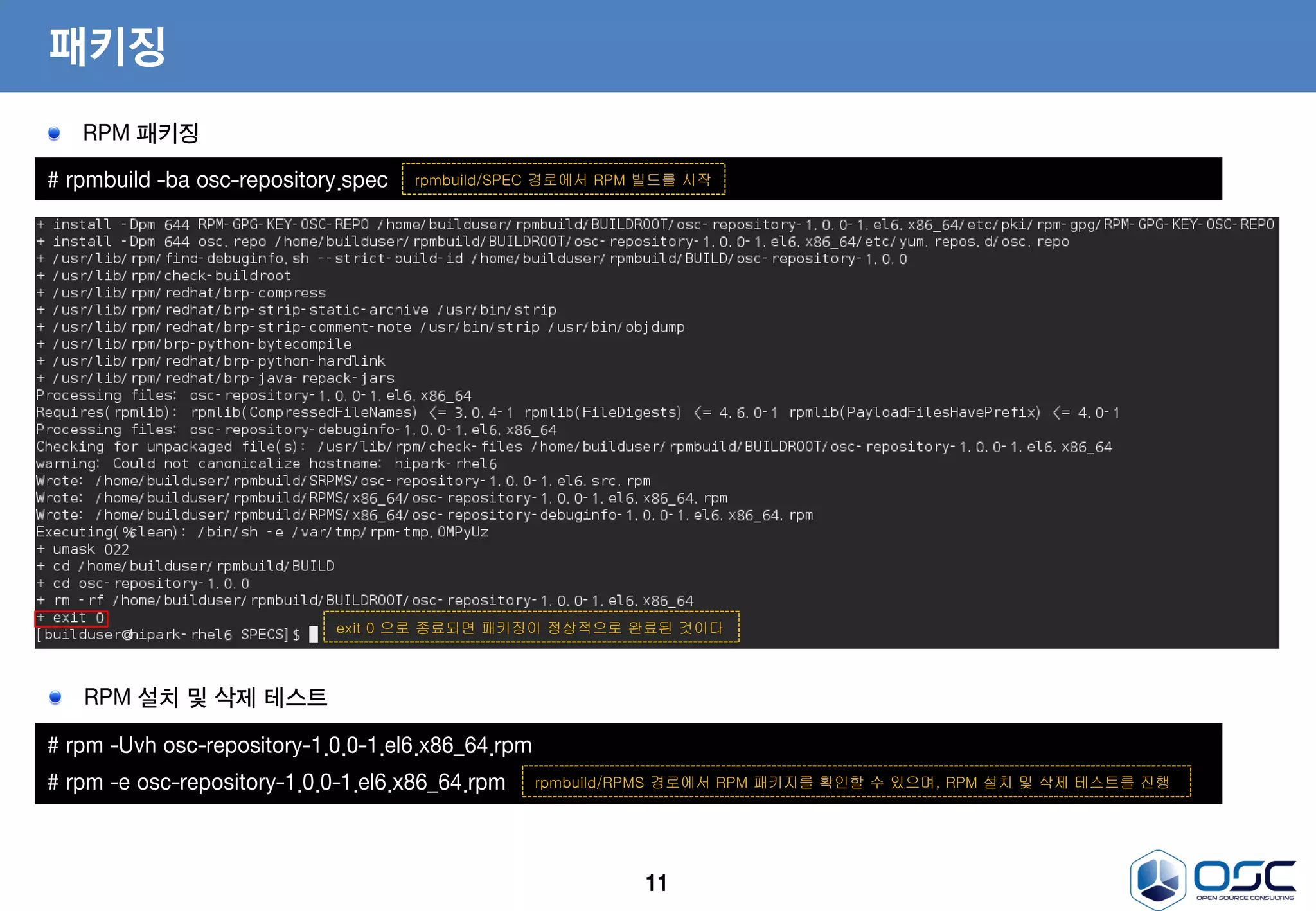
패키징
# rpmbuild -baosc-repository.spec rpmbuild/SPEC 경로에서 RPM 빌드를 시작
exit 0 으로 종료되면 패키징이 정상적으로 완료된 것이다
# rpm -Uvh osc-repository-1.0.0-1.el6.x86_64.rpm
# rpm -e osc-repository-1.0.0-1.el6.x86_64.rpm rpmbuild/RPMS 경로에서 RPM 패키지를 확인할 수 있으며, RPM 설치 및 삭제 테스트를 진행
RPM 설치 및 삭제 테스트
RPM 패키징








![10
SPEC 파일 정의 - ChangeLog
%changelog
* Tue Jan 26 2016 hipark <hipark@osci.kr> - 1-1
- First Release
RPM으로 패키징 될 파일을 하나씩 지정 하는 부분
changelog는 변경된 부분을 적는 곳
아래의 양식을 지켜서 기재할 것
%changelog
* [ 날짜 ] [ 이름 ] [e-mail]
- [ 바뀐 내용 1]
- [ 바뀐 내용 2]](https://image.slidesharecdn.com/rpm-160303232106/75/RPM-10-2048.jpg)






























![[오픈소스컨설팅]Zabbix Installation and Configuration Guide](https://cdn.slidesharecdn.com/ss_thumbnails/zabbixinstallationconfigurationguide-130702191713-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]systemd on RHEL7](https://cdn.slidesharecdn.com/ss_thumbnails/systemdrhel7-160405035049-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]레드햇계열리눅스7 운영자가이드 - 기초편](https://cdn.slidesharecdn.com/ss_thumbnails/rhel7-160406045643-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]Docker on Cloud(Digital Ocean)](https://cdn.slidesharecdn.com/ss_thumbnails/oscdockeronclouddigitalocean-151028115351-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅]Docker on Kubernetes v1](https://cdn.slidesharecdn.com/ss_thumbnails/dockeronkubernetesv1-160830033537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]RHEL7/CentOS7 Pacemaker기반-HA시스템구성-v1.0](https://cdn.slidesharecdn.com/ss_thumbnails/rhel-centos7-pacemaker-based-ha-admin-guidev1-151215000535-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]오픈스택에 대하여](https://cdn.slidesharecdn.com/ss_thumbnails/random-151125103039-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]오픈소스메일시스템](https://cdn.slidesharecdn.com/ss_thumbnails/random-150106005345-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]이기종 WAS 클러스터링 솔루션- Athena Dolly](https://cdn.slidesharecdn.com/ss_thumbnails/athena-dollyv3-150206074107-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]파일럿진행예제 on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/osconaws-151026093255-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]J boss6 7_교육자료](https://cdn.slidesharecdn.com/ss_thumbnails/jboss67-141228212447-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅]Scouter 설치 및 사용가이드(JBoss)](https://cdn.slidesharecdn.com/ss_thumbnails/scouterjboss-160310001021-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]소프트웨어 개발 준비 과정](https://cdn.slidesharecdn.com/ss_thumbnails/04-150820052522-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] Open Stack Ceph, Neutron, HA, Multi-Region](https://cdn.slidesharecdn.com/ss_thumbnails/openstackoscv0-160718105826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] Open stack kilo with DVR_CEPH_v1.1](https://cdn.slidesharecdn.com/ss_thumbnails/openstackkilowithdvrcephv1-150824033930-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]Atlassian JIRA Deep Dive](https://cdn.slidesharecdn.com/ss_thumbnails/atlassianjiradeepdive-160121020629-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]Java Performance Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/javaperformanetuning-150408192031-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]오픈소스 기반 솔루션 아키텍처 특징 및 사례](https://cdn.slidesharecdn.com/ss_thumbnails/05-150820053151-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[오픈소스컨설팅]Nginx 1.2.7 설치가이드__v1](https://cdn.slidesharecdn.com/ss_thumbnails/nginx1-2-7v1-130506223255-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















![[오픈소스컨설팅] Red Hat ReaR (relax and-recover) Quick Guide](https://cdn.slidesharecdn.com/ss_thumbnails/redhatrearrelax-and-recoverquickguidev1-170419093210-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]쿠버네티스를 활용한 개발환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsutingkubernetesv0-191010000815-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] 스카우터 사용자 가이드 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅] Docker를 활용한 Gitlab CI/CD 구성 테스트](https://cdn.slidesharecdn.com/ss_thumbnails/dockergitlabci-cd-180103202327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]Docker기초 실습 교육 20181113_v3](https://cdn.slidesharecdn.com/ss_thumbnails/oscdockereducation20181113hanv3-181113075418-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] 아파치톰캣 운영가이드 v1.3](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingtomcatoperationguidev1-181113020525-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] Ansible을 활용한 운영 자동화 교육](https://cdn.slidesharecdn.com/ss_thumbnails/ansibleautomationv1-190221013416-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]클라우드기반U2L마이그레이션 전략 및 고려사항](https://cdn.slidesharecdn.com/ss_thumbnails/u2l-171114134117-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅] 프로메테우스 모니터링 살펴보고 구성하기](https://cdn.slidesharecdn.com/ss_thumbnails/oscprometheus-190422050231-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] 오픈소스 기반 솔루션 방향성 잡기](https://cdn.slidesharecdn.com/ss_thumbnails/solutionidea-210226024013-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] 2019년 클라우드 생존전략](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingcloudstrategyv2-190109001332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]Atlassian JIRA Quick Guide](https://cdn.slidesharecdn.com/ss_thumbnails/jiraquickguidev2-160420123530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]ELK기반 장애예방시스템_구성_2016.12](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsulting-elkv2-180716032900-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅 뉴스레터] 2016년 1분기](https://cdn.slidesharecdn.com/ss_thumbnails/20161qv0-160308020148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅] AWS re:Invent 2018 기계학습(ML)부분 후기](https://cdn.slidesharecdn.com/ss_thumbnails/reinventreview-181218230336-thumbnail.jpg?width=640&height=640&fit=bounds)
