Download as PDF, PPTX


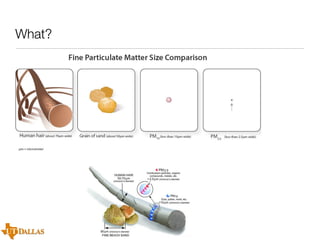


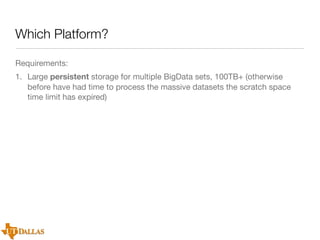
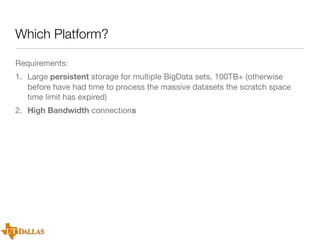
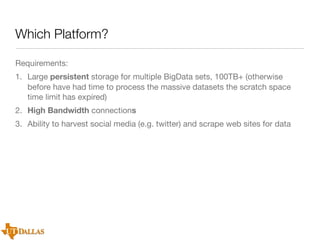
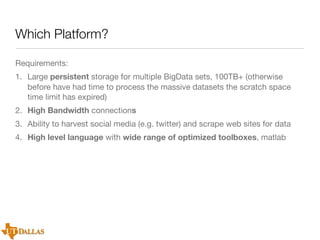
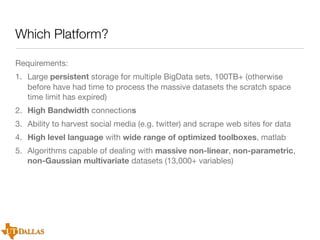
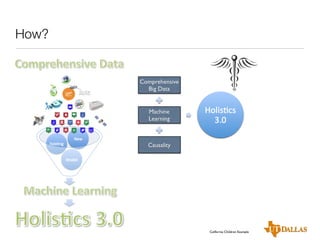


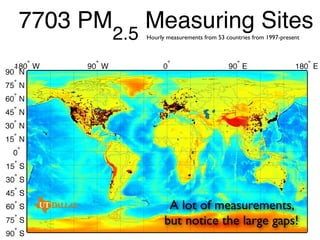





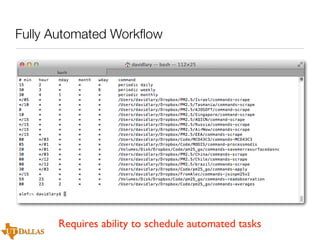
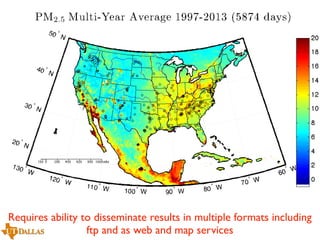
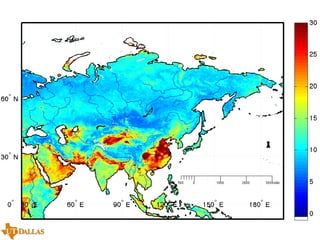
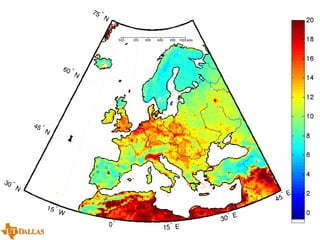
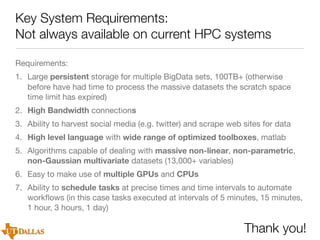

The document discusses a case study on utilizing large datasets and machine learning techniques to create a global particulate matter dataset, focusing on PM2.5 data collection methods, challenges, and required platforms. It outlines key system requirements for processing large datasets, including high storage capacity, bandwidth, and sophisticated algorithms. The study highlights the integration of various data sources, such as satellites and social media, to enhance air quality monitoring and improve health outcomes associated with particulate pollution.












































































