Download to read offline


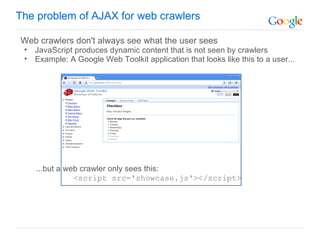
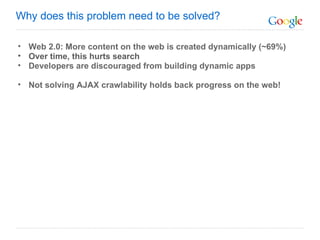
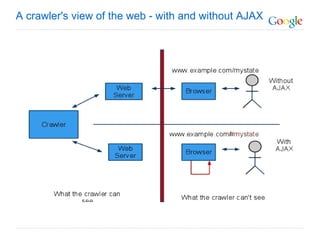
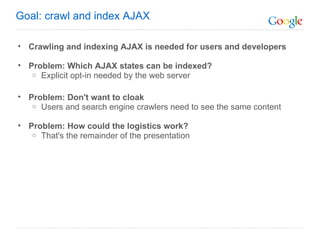
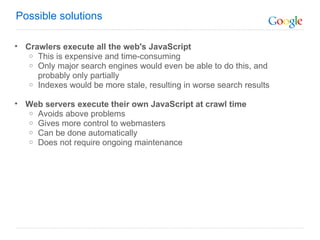
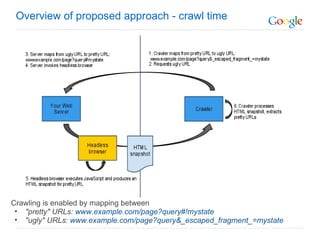
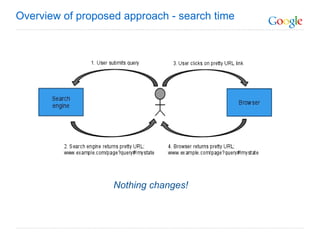

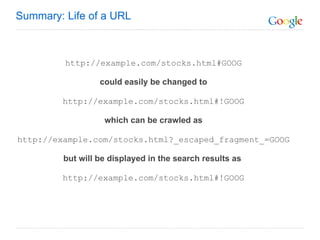

The document discusses the problem that web crawlers cannot see dynamic or AJAX content on websites that users see. It proposes a solution where web servers execute their JavaScript at crawl time and provide the same content to crawlers and users to make AJAX states crawlable and indexable. Major search engines and web servers would need to agree to adopt standards around modifying URLs and executing JavaScript at crawl time in order to solve this problem.































































