Download to read offline











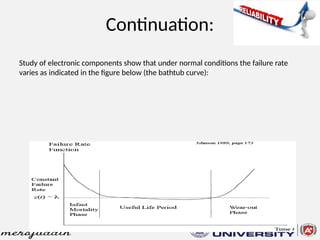























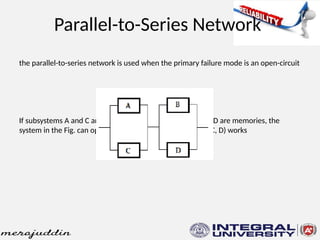

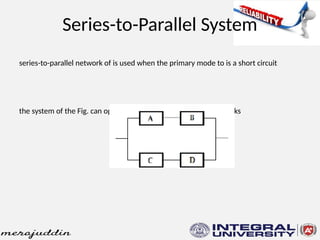


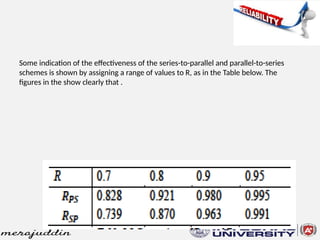






This document discusses the concepts of reliability, fault tolerance, and failure diagnosis in systems. It categorizes faults into transient, intermittent, and permanent, while outlining methods to achieve fault tolerance through redundancy and replication. Additionally, it covers reliability metrics, maintainability, and the impact of system design on overall reliability, detailing both series and parallel system configurations.















































