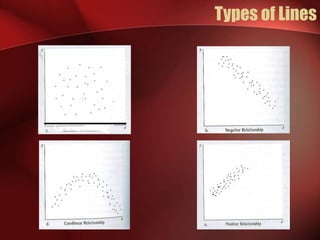
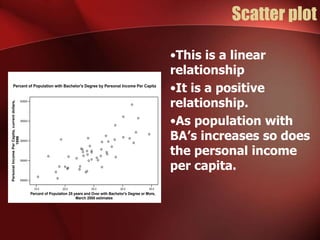
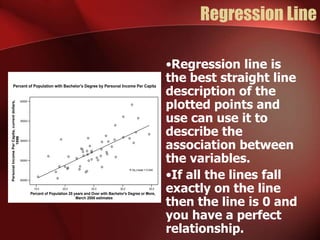
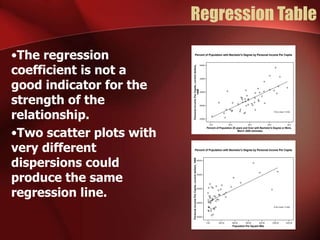
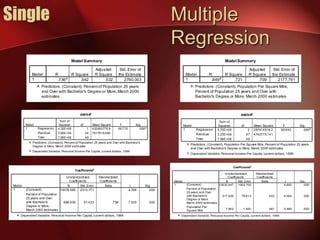
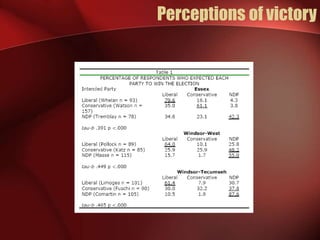
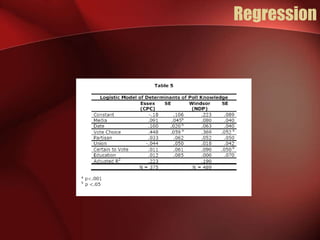
Regression analysis can be used to analyze the relationship between variables. A scatter plot should first be created to determine if the variables have a linear relationship required for regression analysis. A regression line is fitted to best describe the linear relationship between the variables, with an R-squared value indicating how well it fits the data. Multiple regression allows for analysis of the relationship between a dependent variable and multiple independent variables and their individual contributions to explaining the variance in the dependent variable.























































![ppt1221[1][1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ppt122111-230603111304-030afe29-thumbnail.jpg?width=640&height=640&fit=bounds)




















