Download as PDF, PPTX





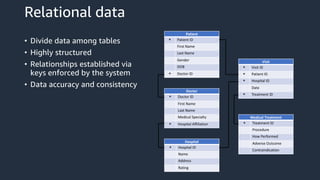
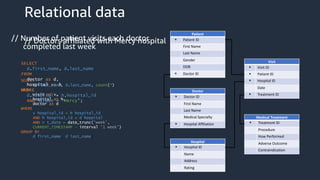
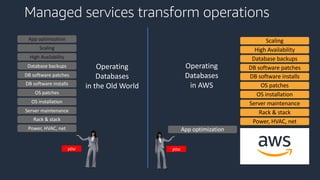


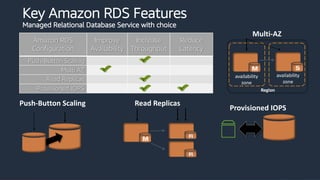
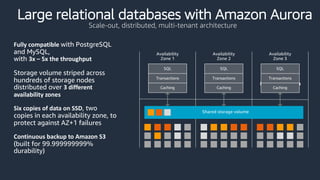
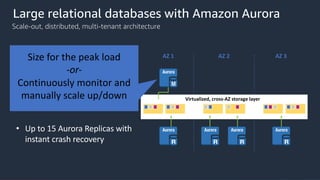


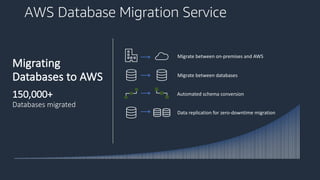


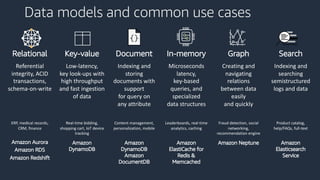





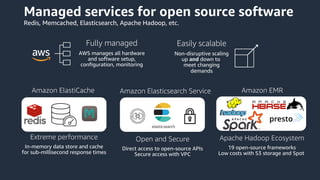
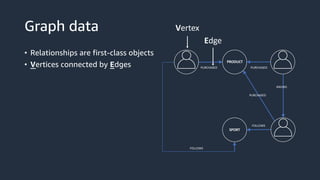
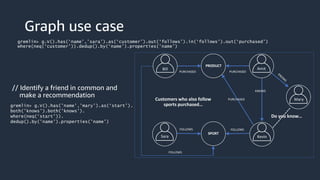
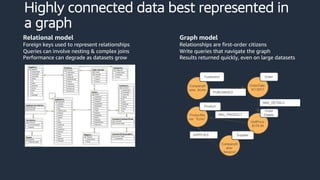


This document provides an overview of AWS databases and analytics services. It discusses AWS's broad portfolio of purpose-built databases including relational databases like RDS and Aurora, non-relational databases like DynamoDB and Neptune, data lakes with S3 and Glue, data movement services, and analytics services like Redshift, EMR, and Athena. It also covers key concepts around relational and non-relational data models and provides examples of common use cases for different database types.























![Introduction to AWS Cloud Databases [Apr 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontoawsclouddatabasesapr2020-240904112416-f4009f50-thumbnail.jpg?width=640&height=640&fit=bounds)




































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






