Download as PDF, PPTX














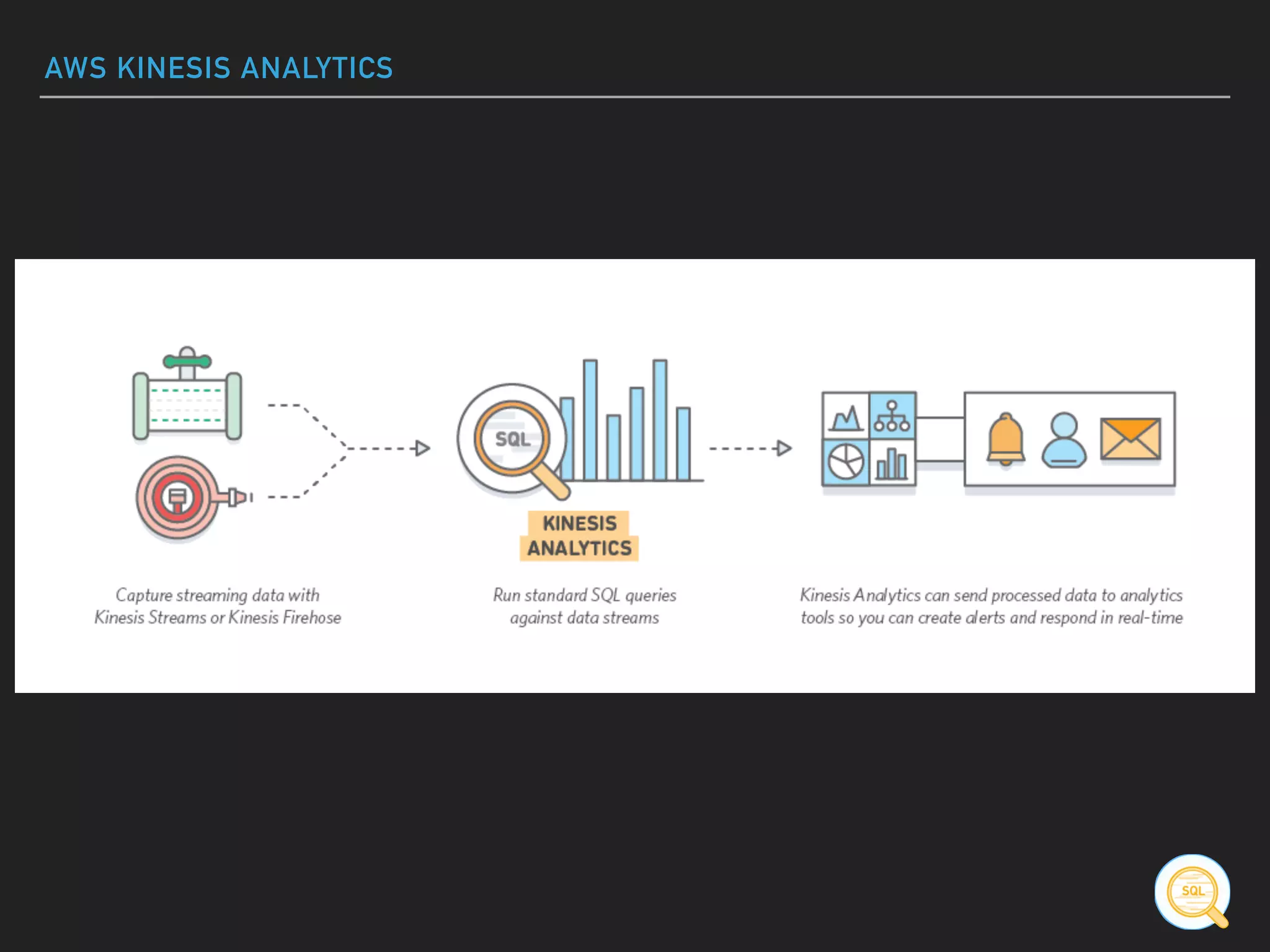
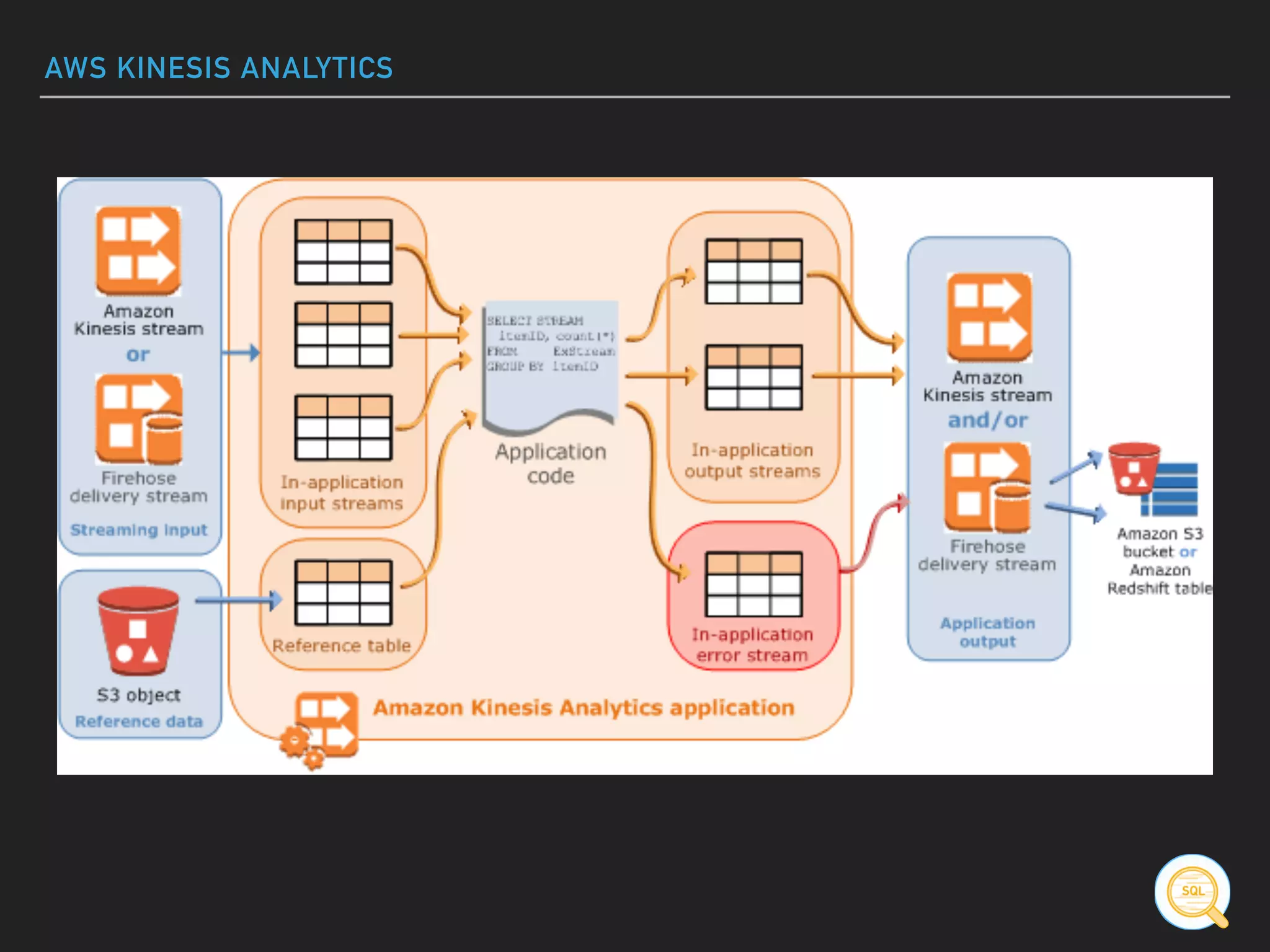

![AWS KINESIS ANALYTICS
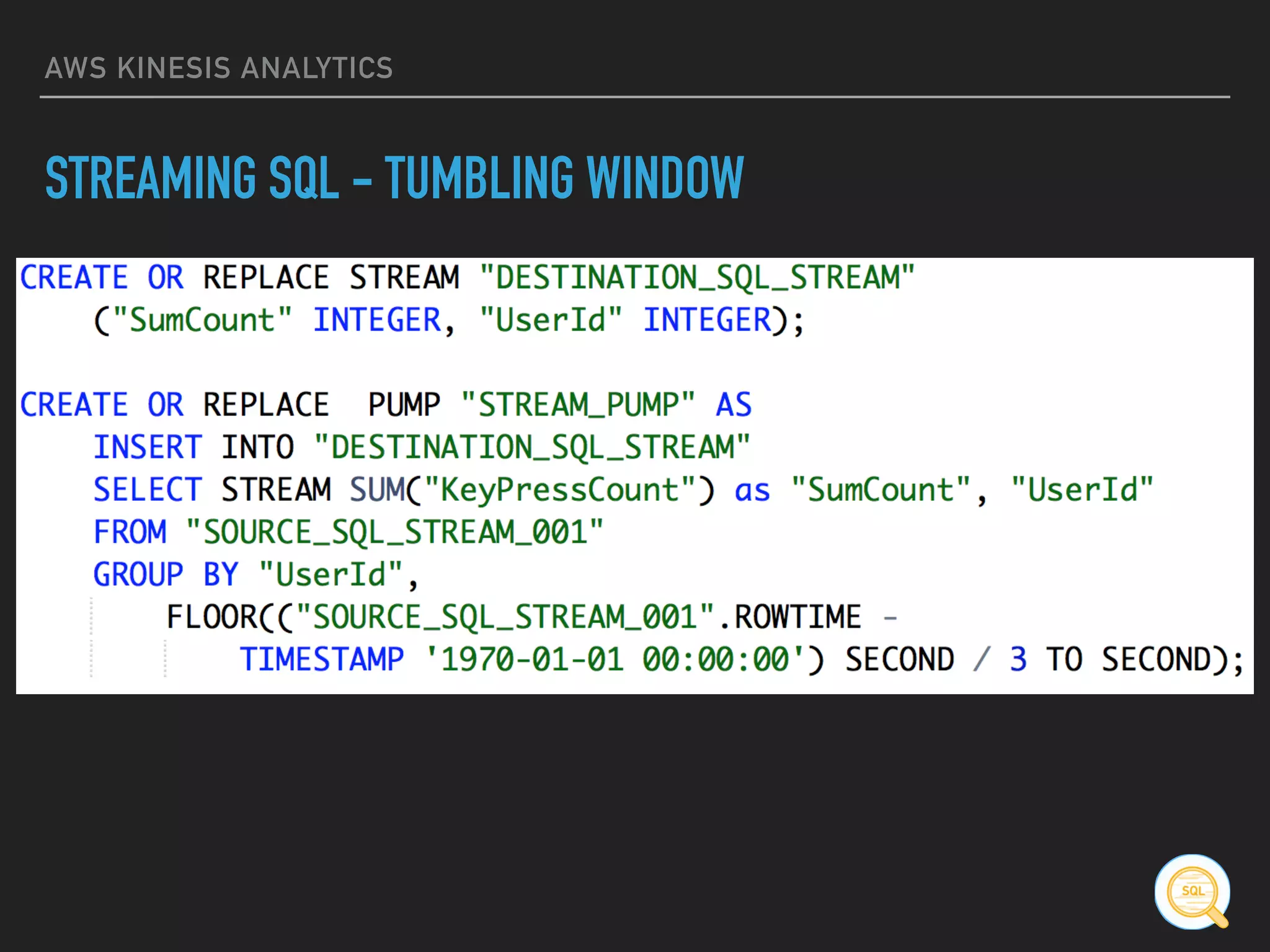
STREAMING SQL
▸ Tumbling Window
[...] GROUP BY
FLOOR((“SOURCE_SQL_STREAM_001”.ROWTIME – TIMESTAMP
‘1970-01-01 00:00:00’) SECOND / 10 TO SECOND)
▸ Sliding Window
SELECT AVG(change) OVER W1 as avg_change
FROM "SOURCE_SQL_STREAM_001"
WINDOW W1 AS (PARTITION BY ticker_symbol RANGE INTERVAL
'10' SECOND PRECEDING)](https://image.slidesharecdn.com/awsbigdatastack-170612103317/75/Big-Data-on-AWS-26-2048.jpg)



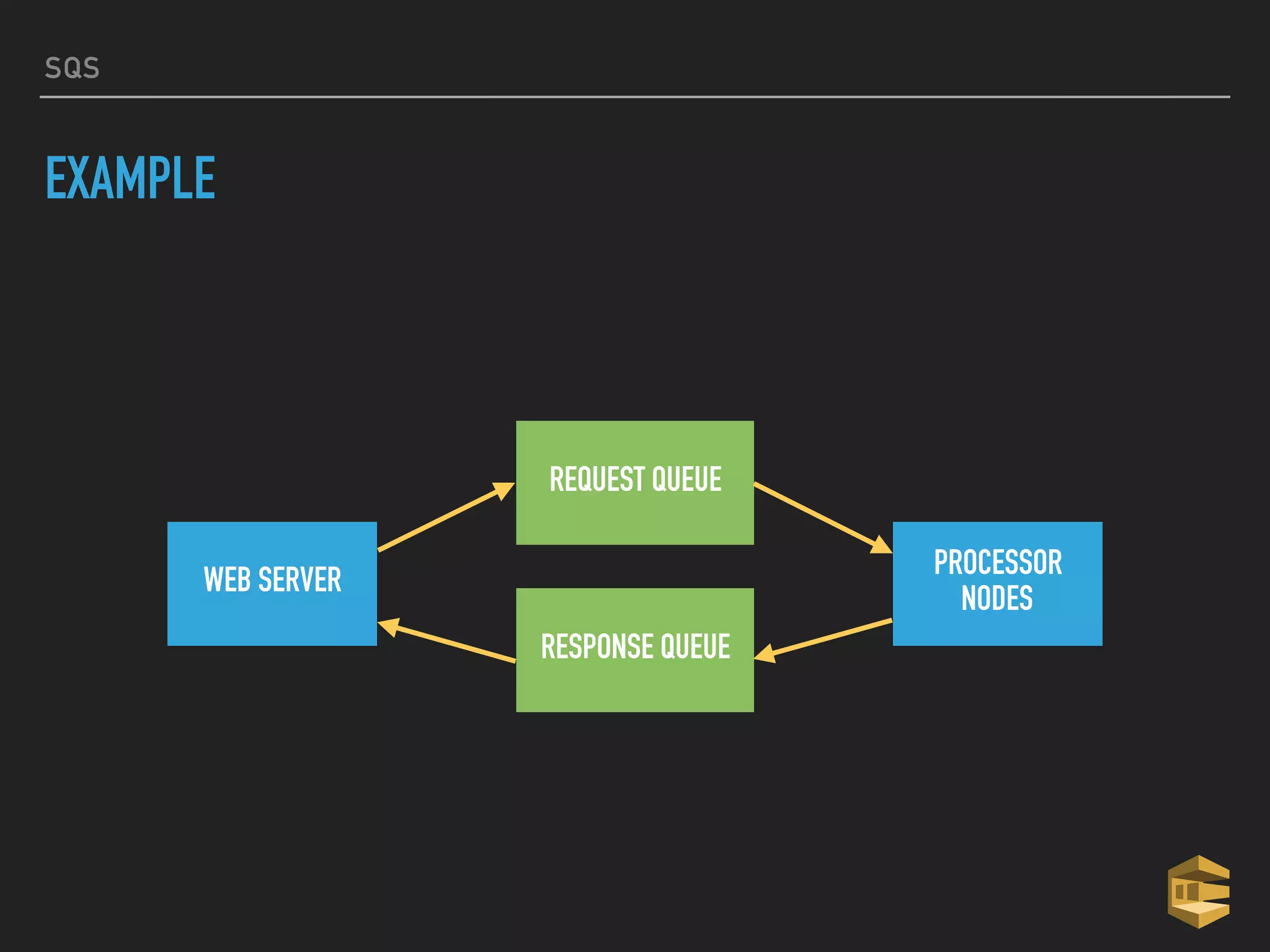




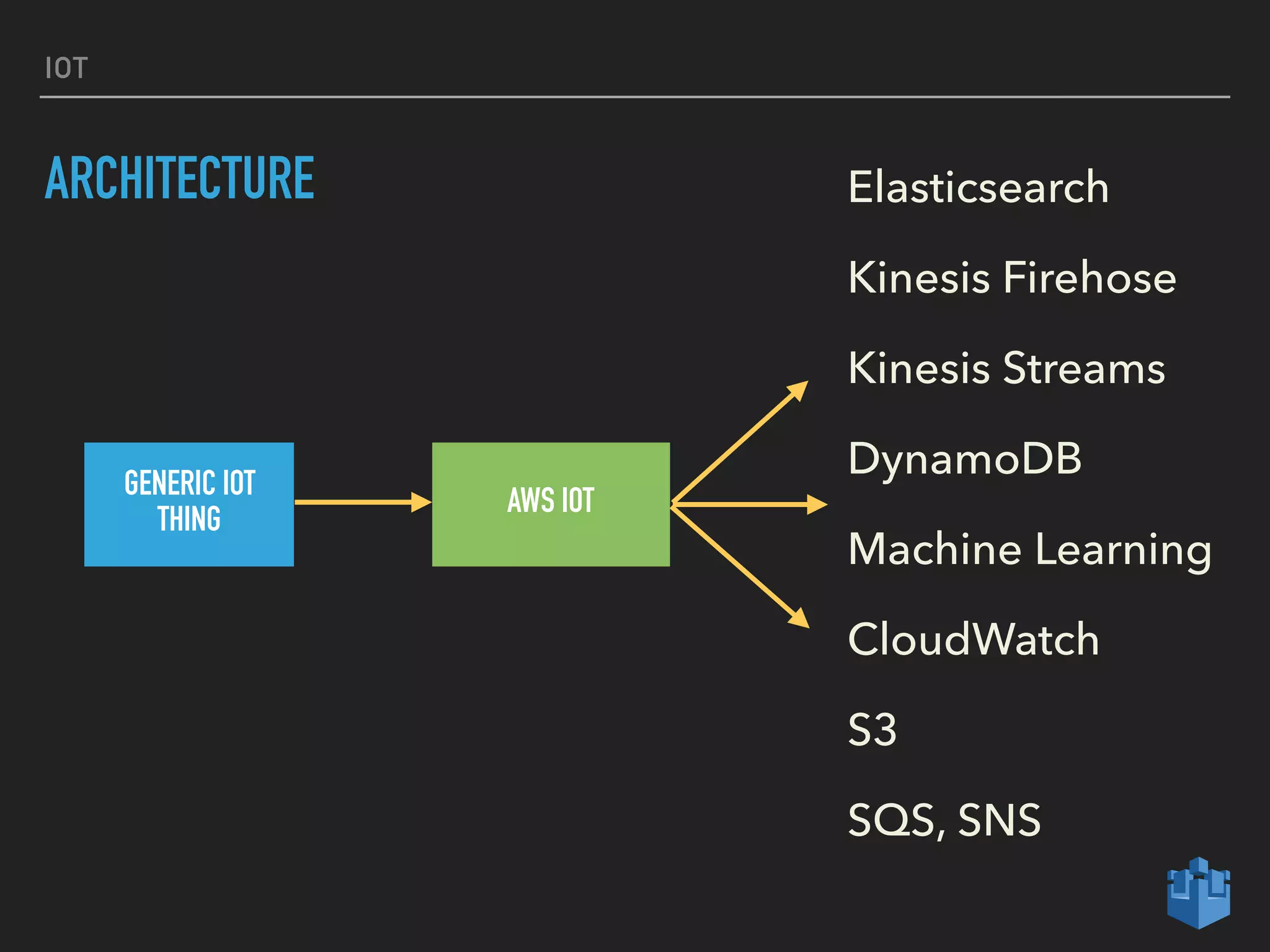
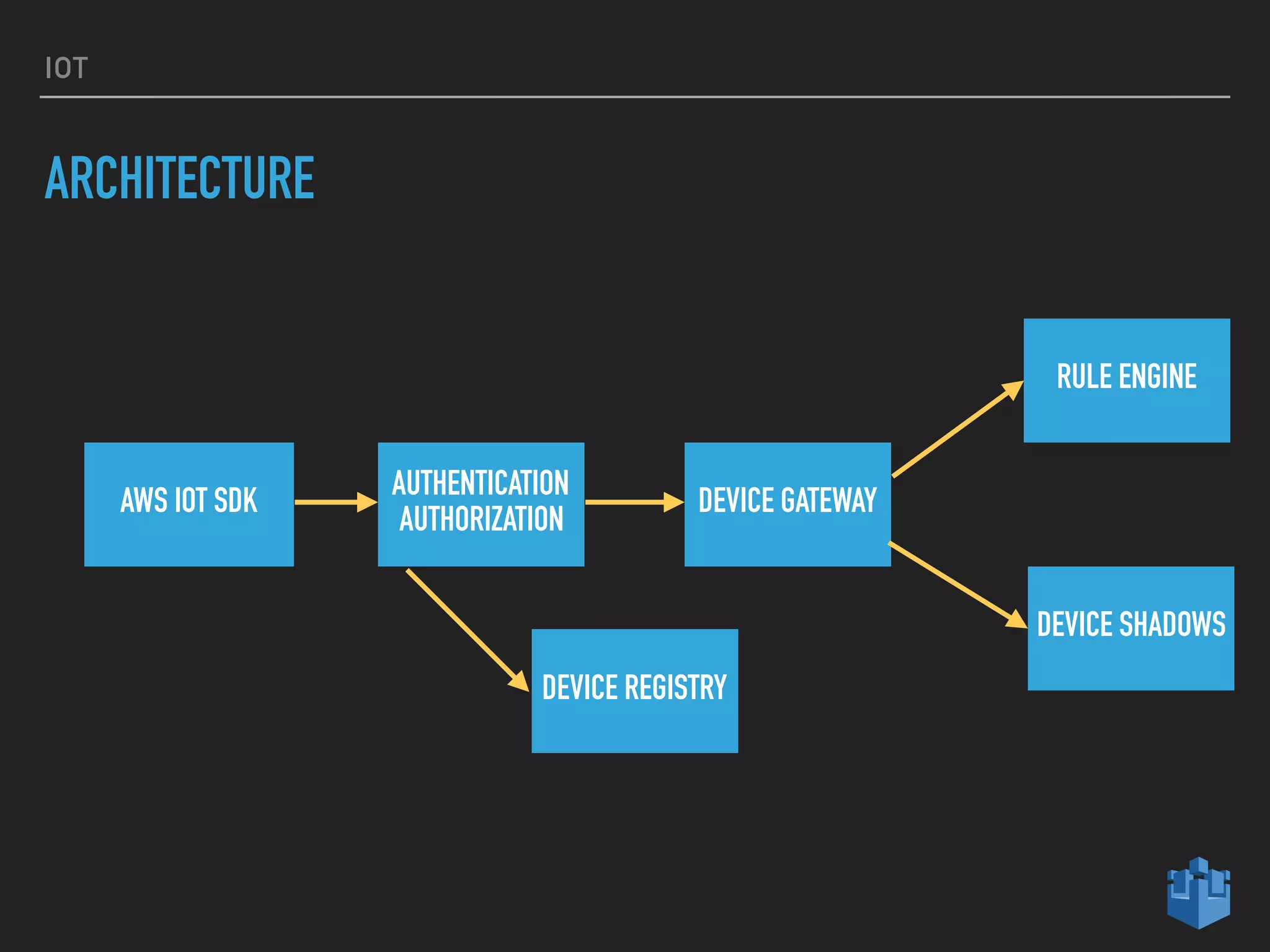



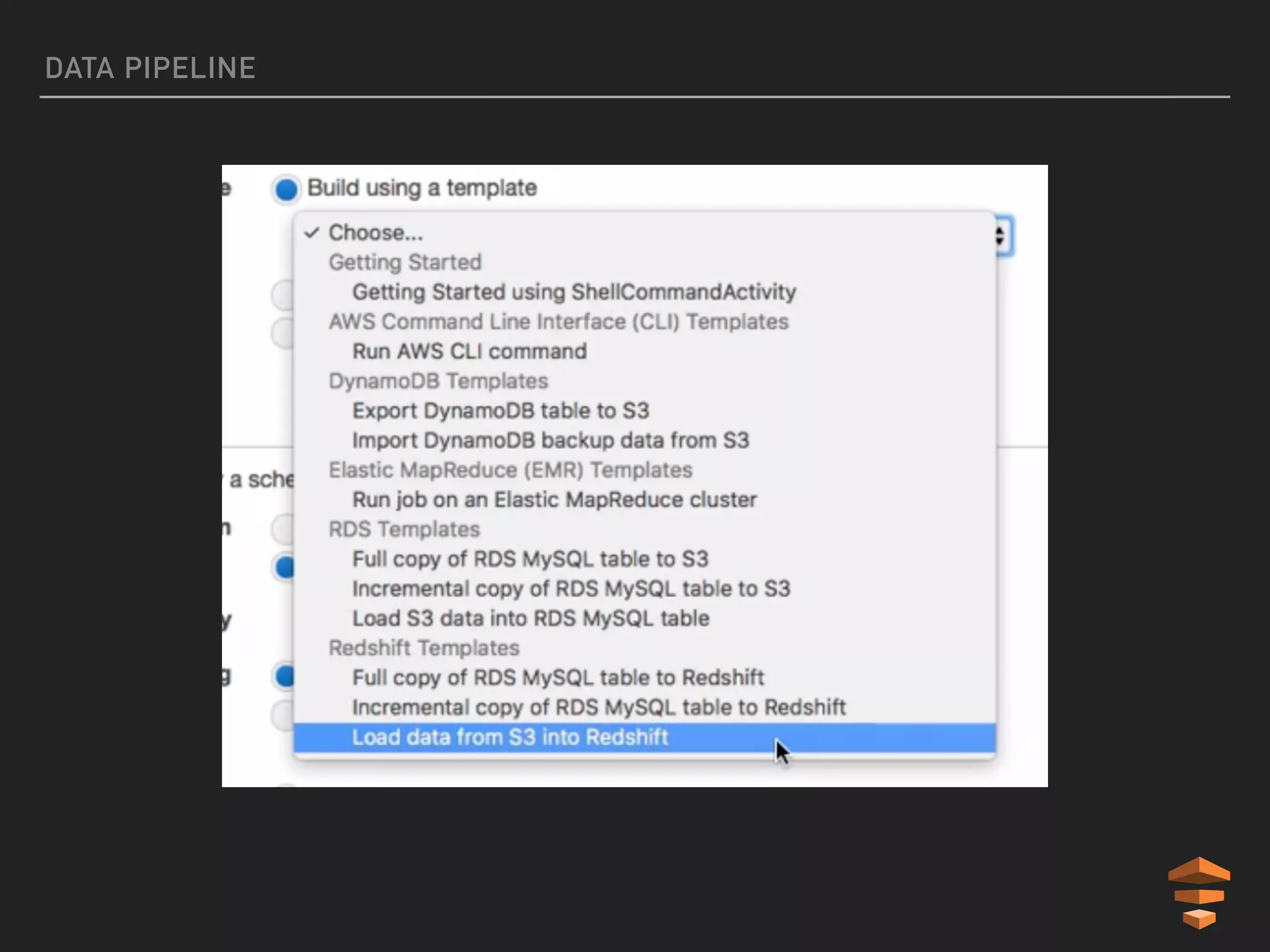










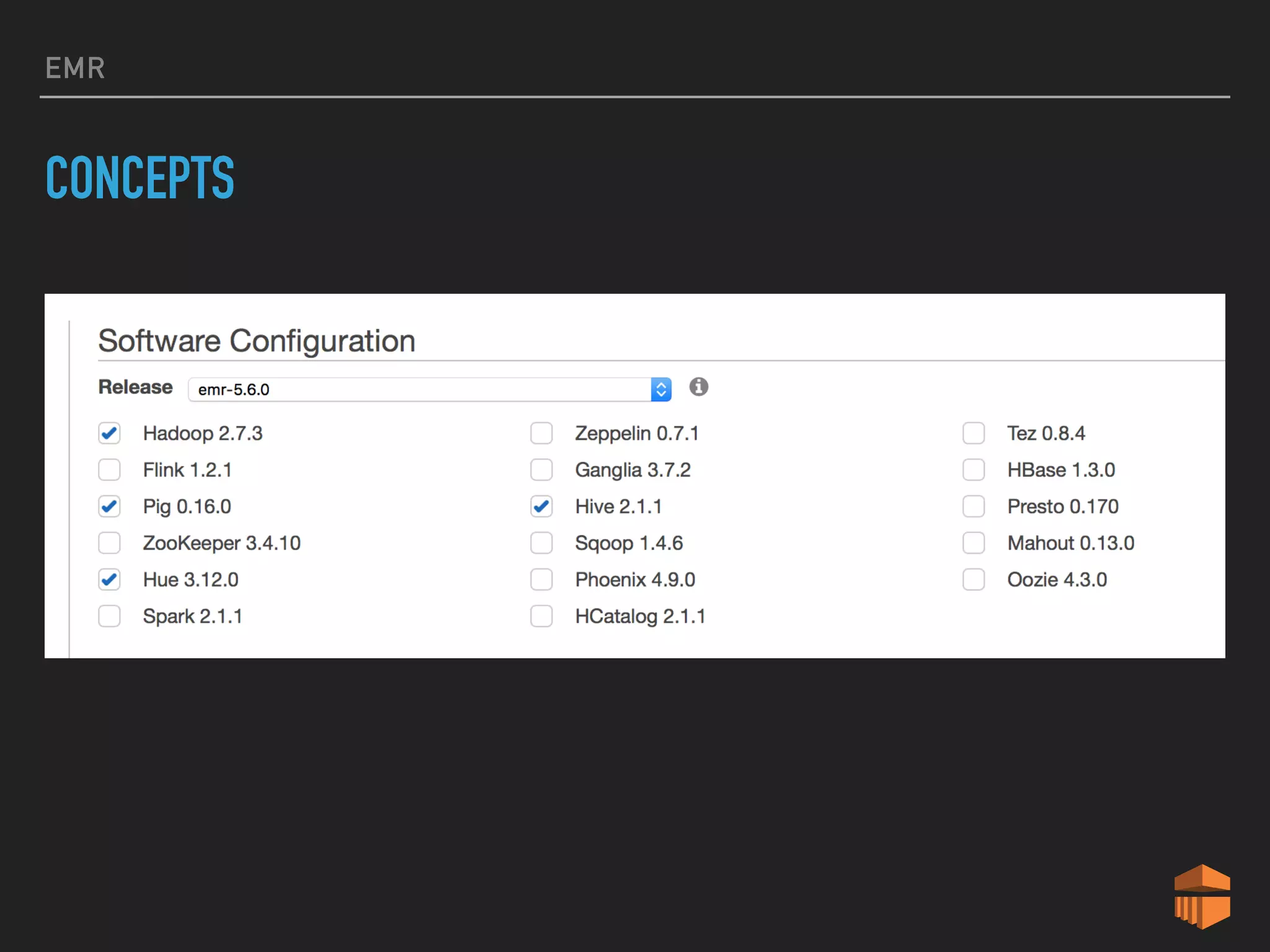
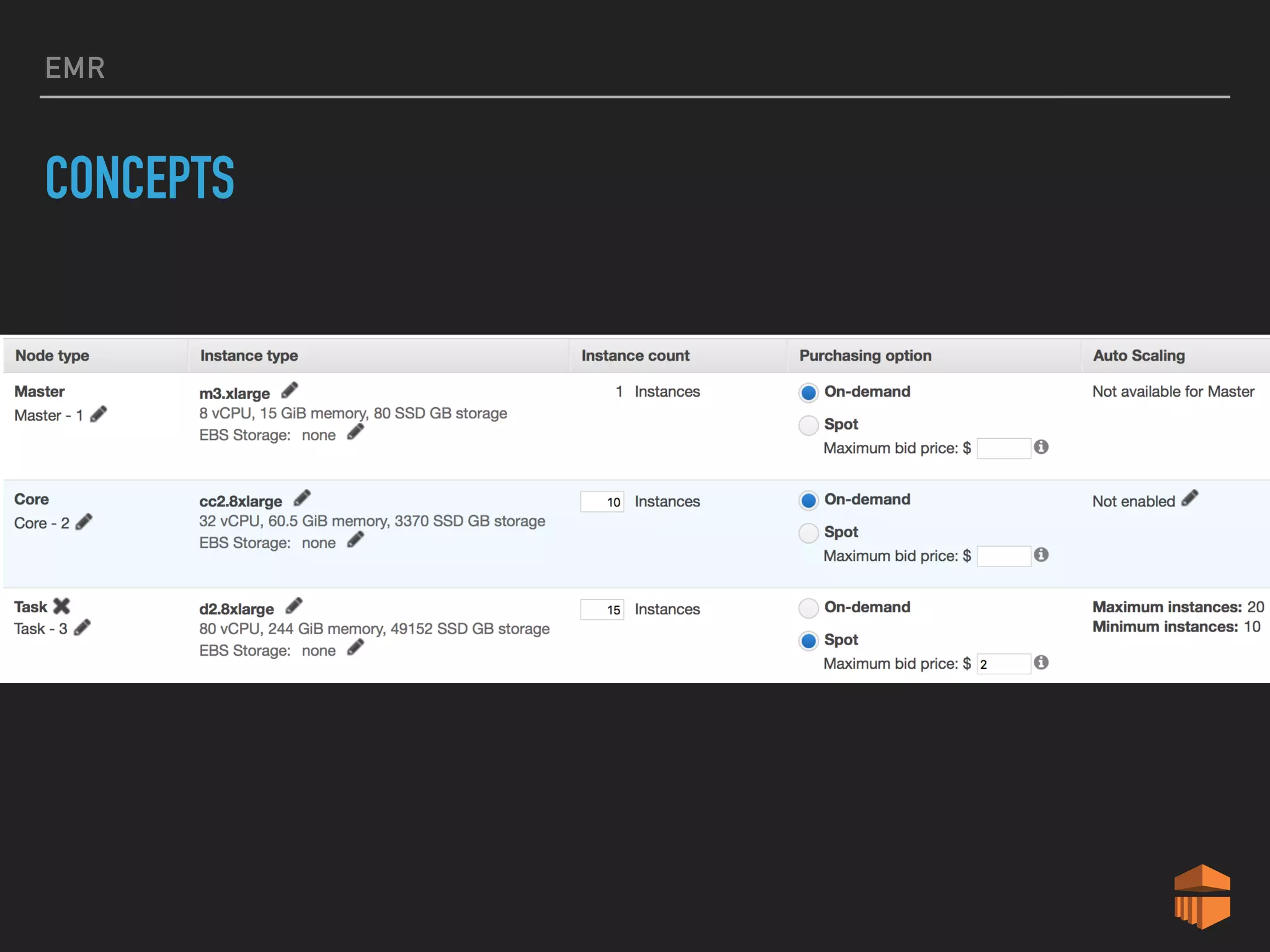







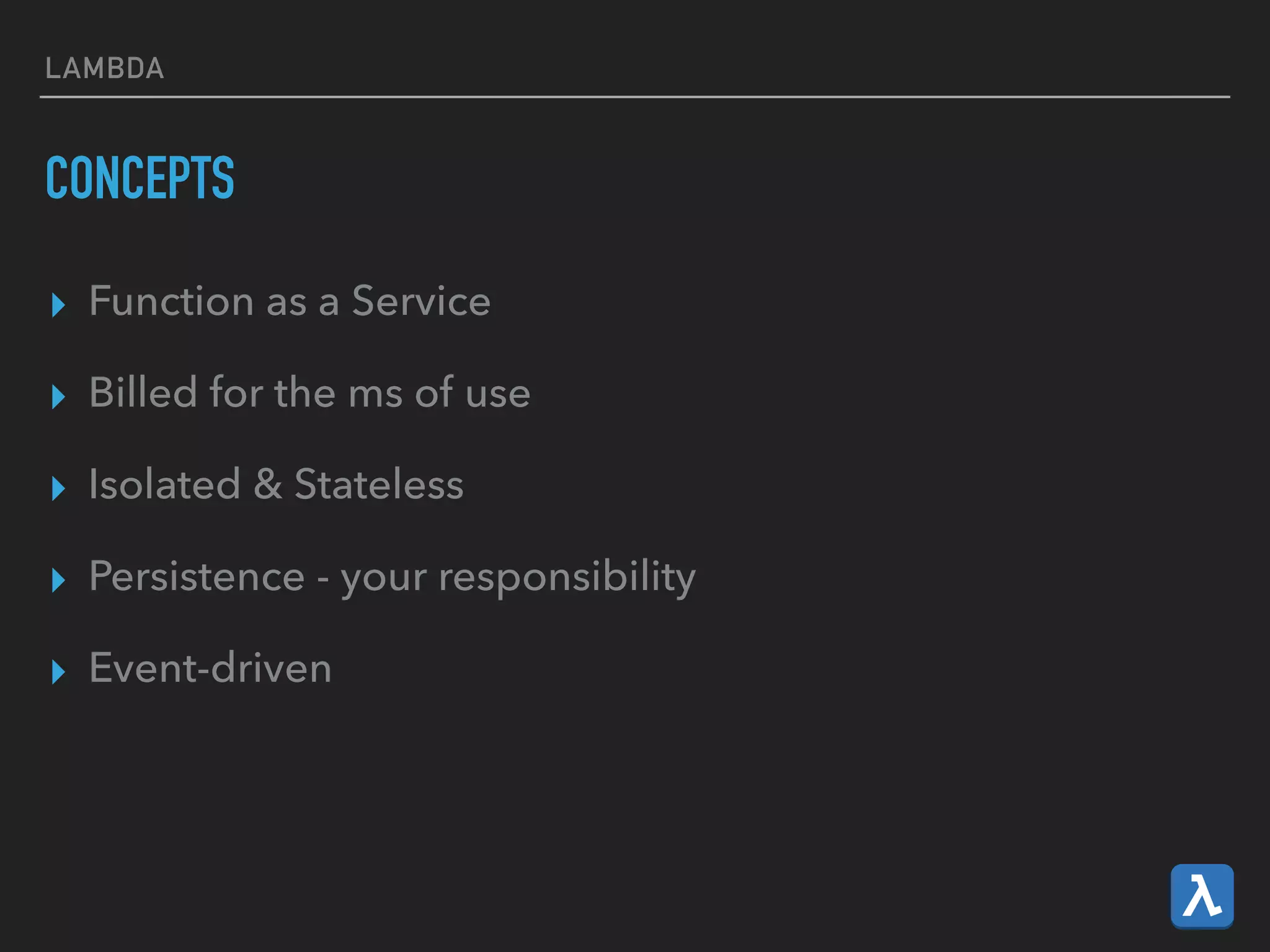
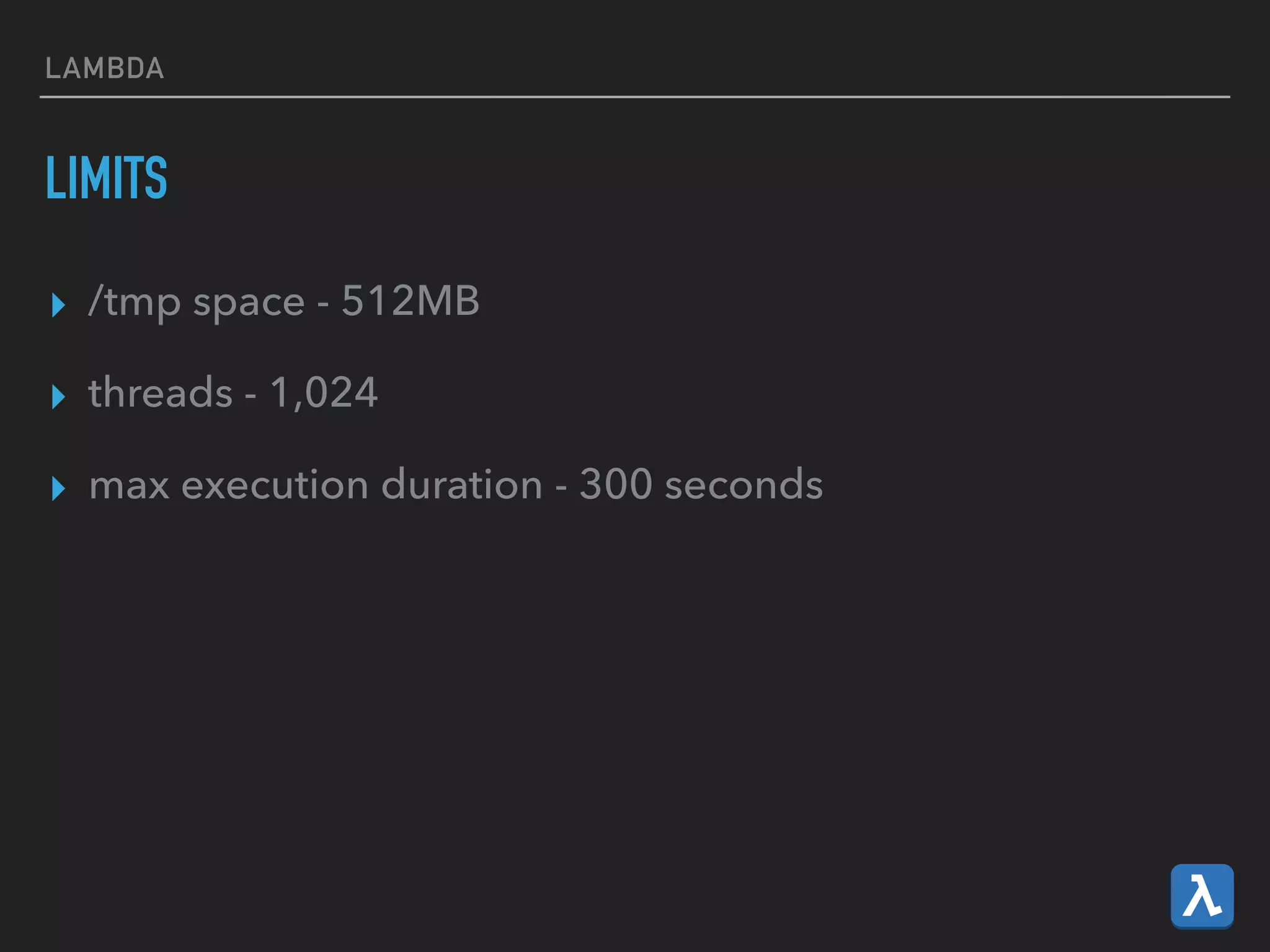
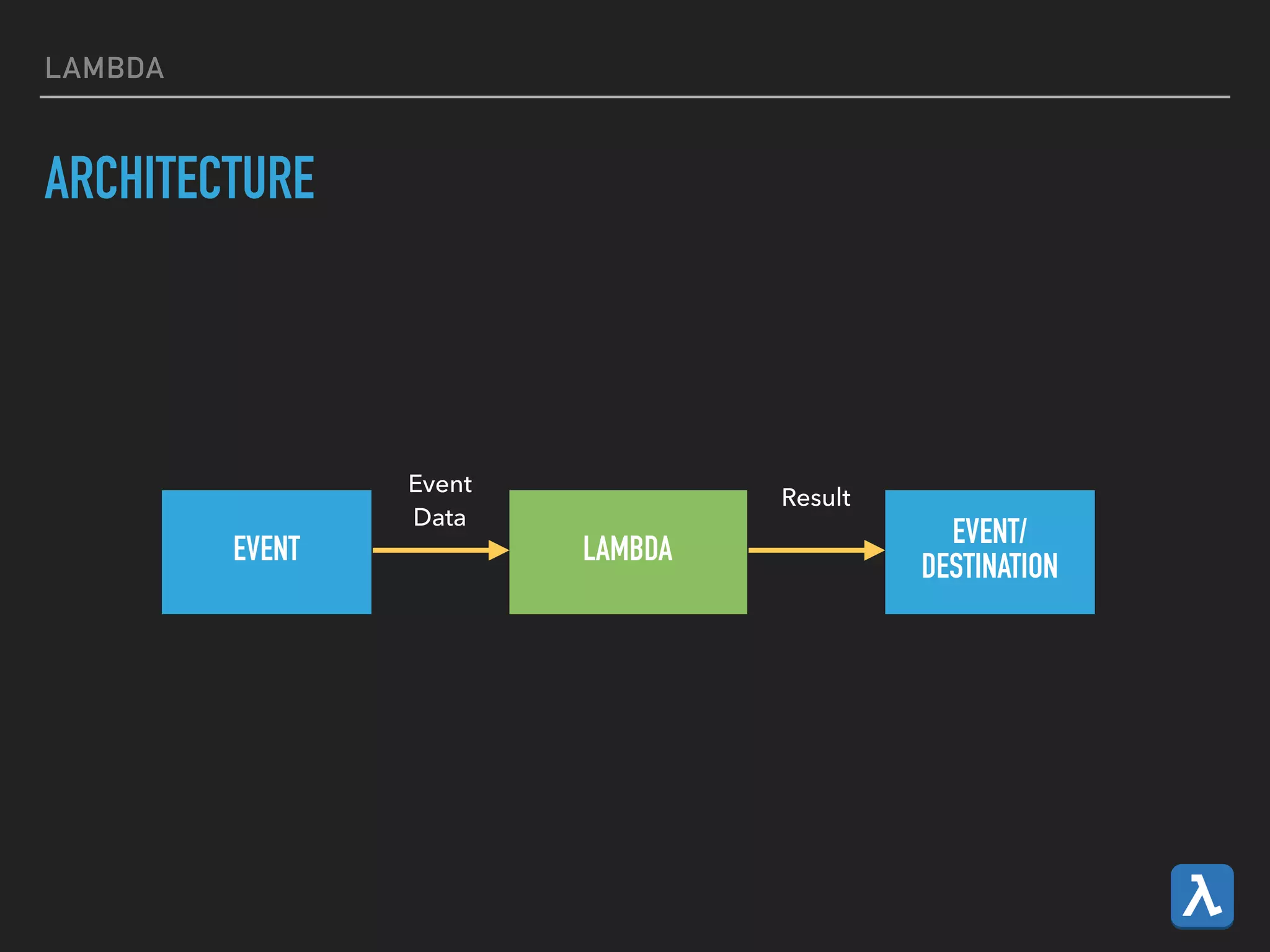
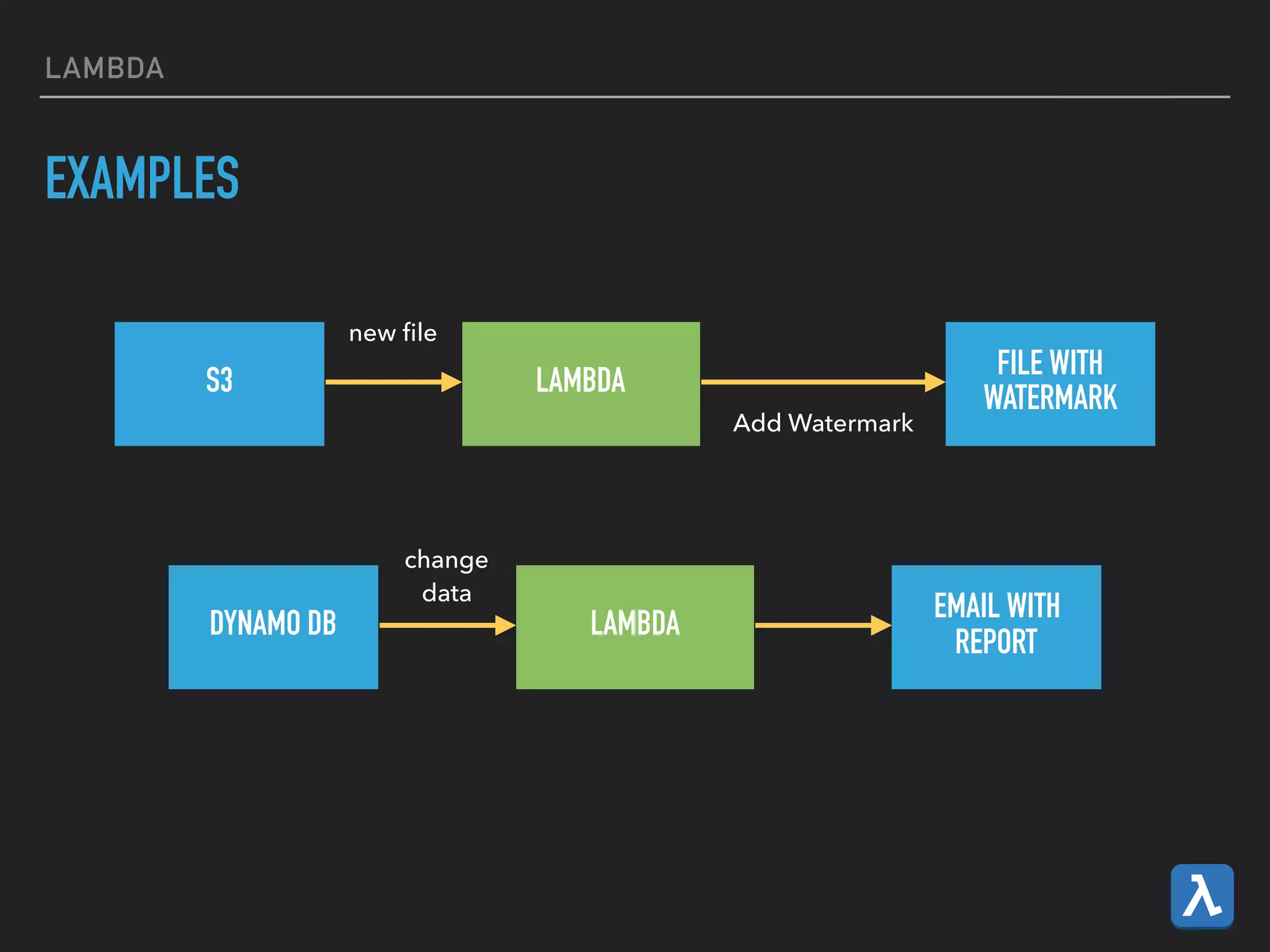



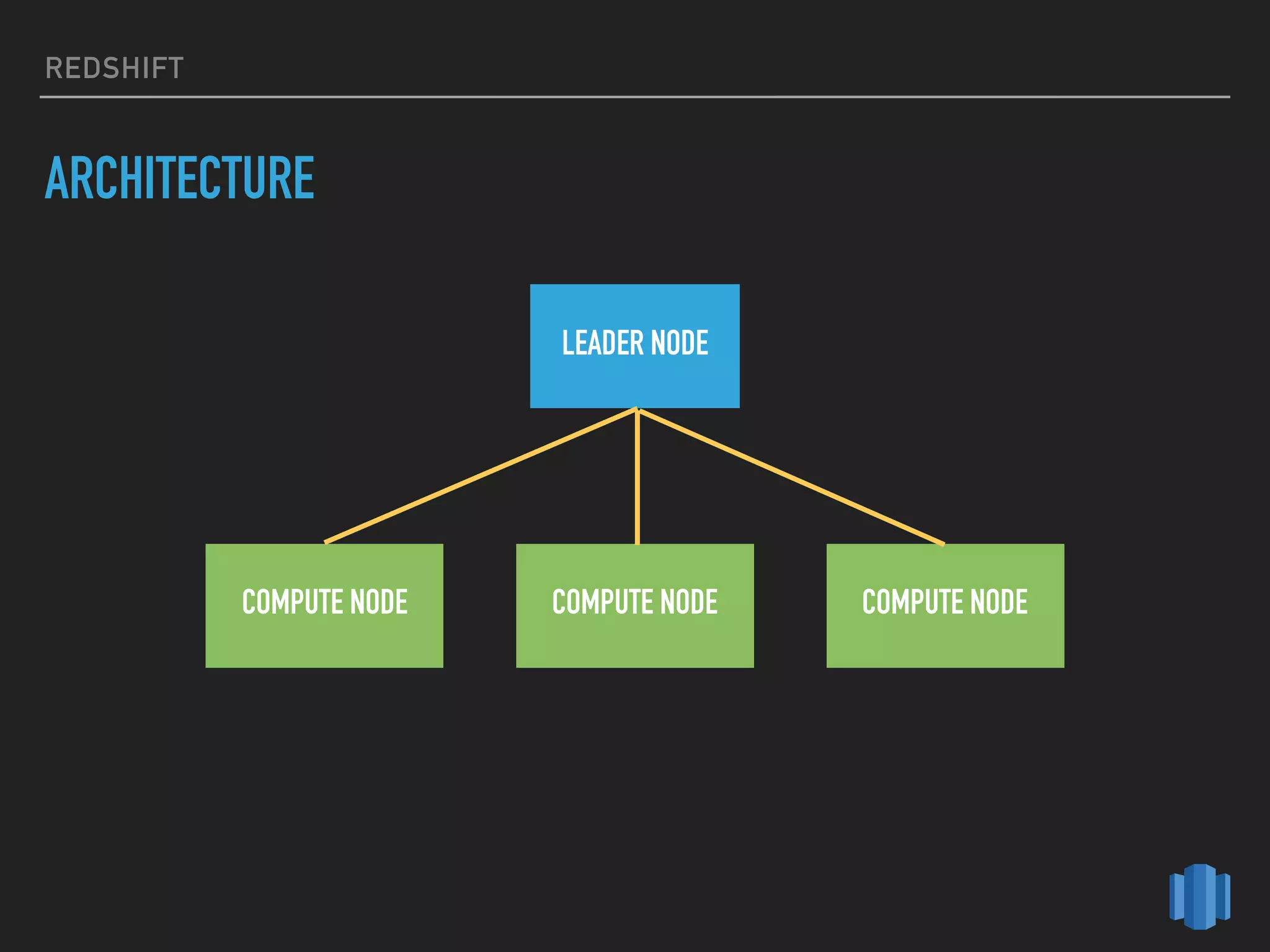








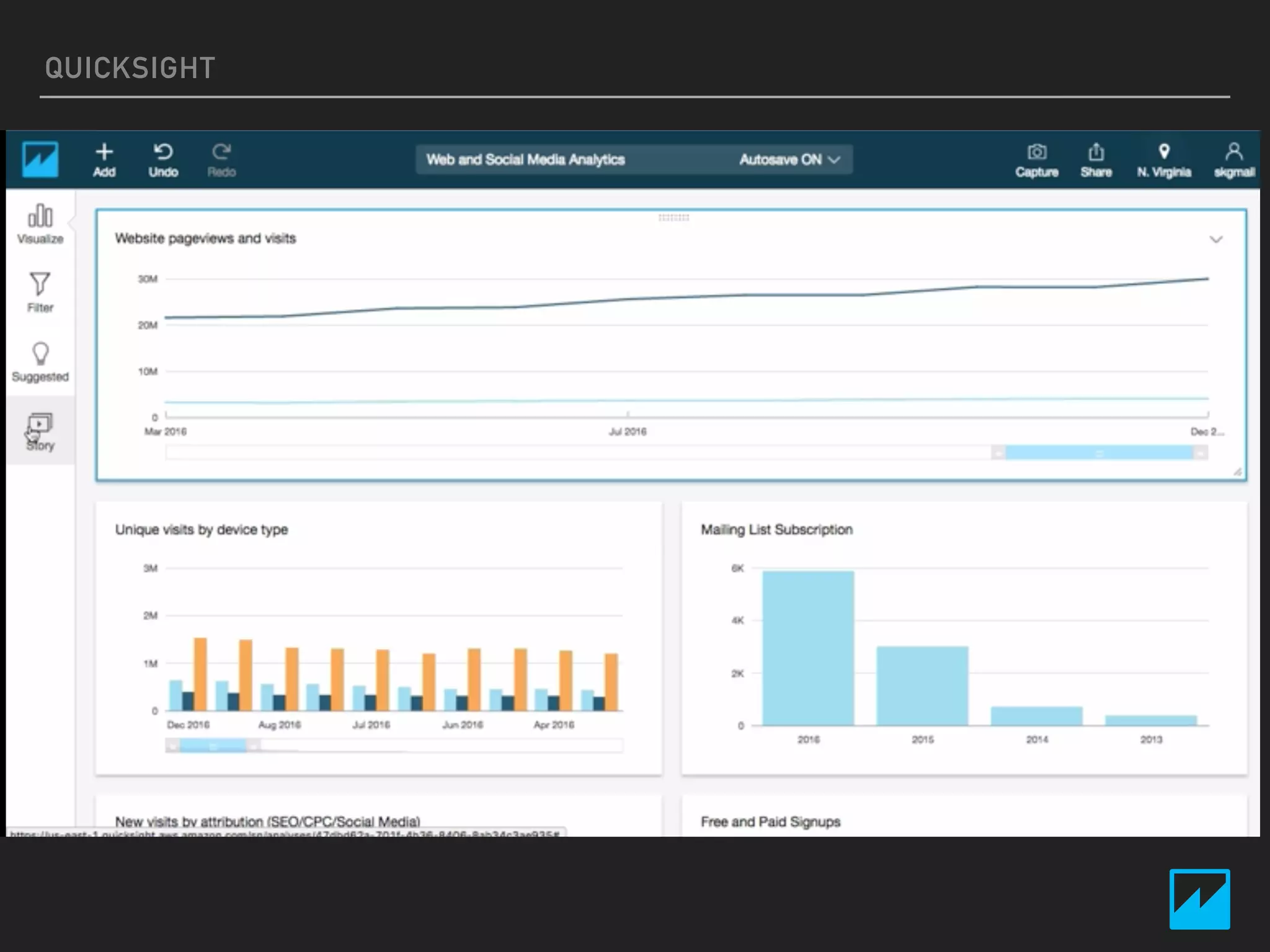





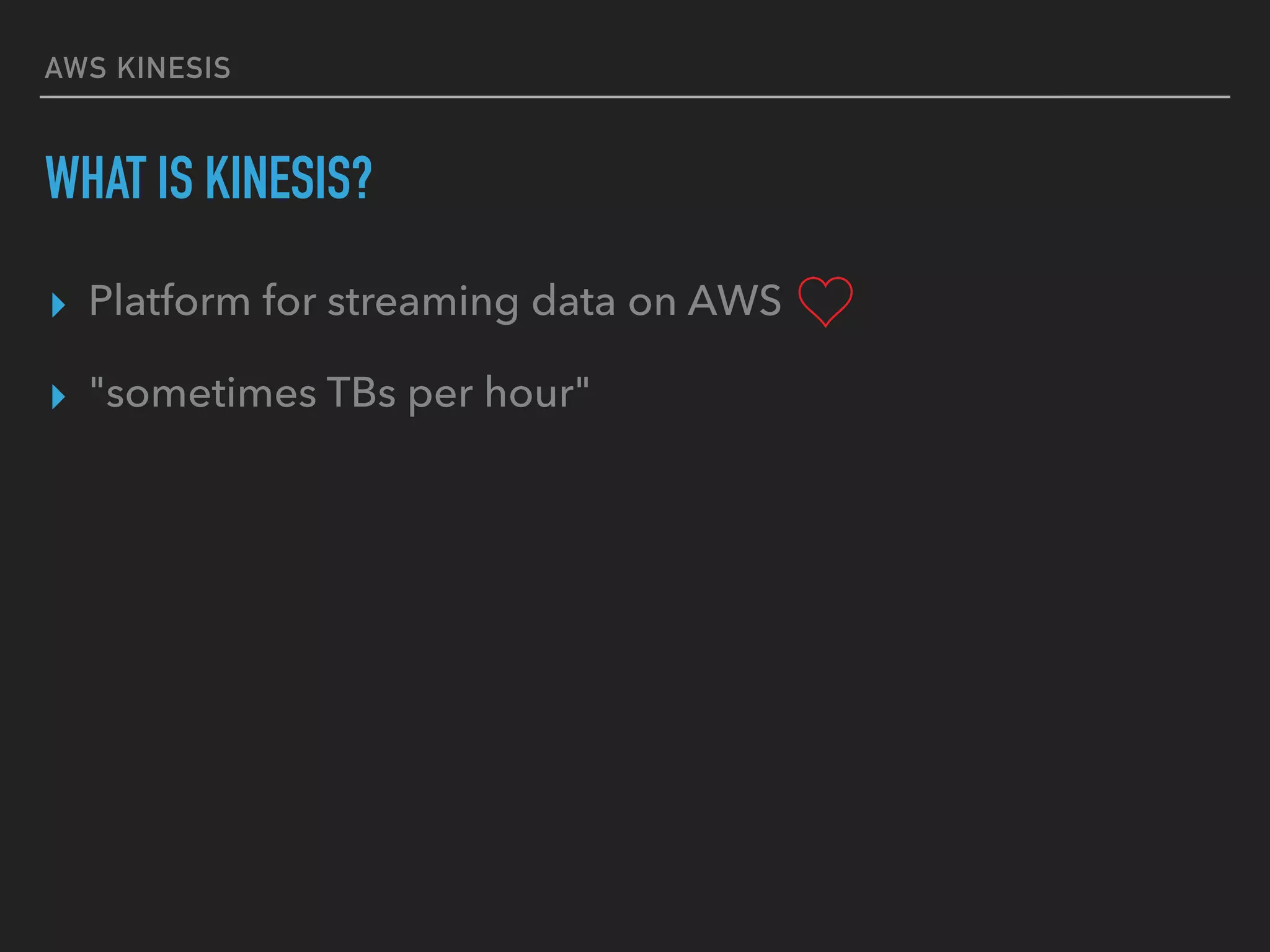
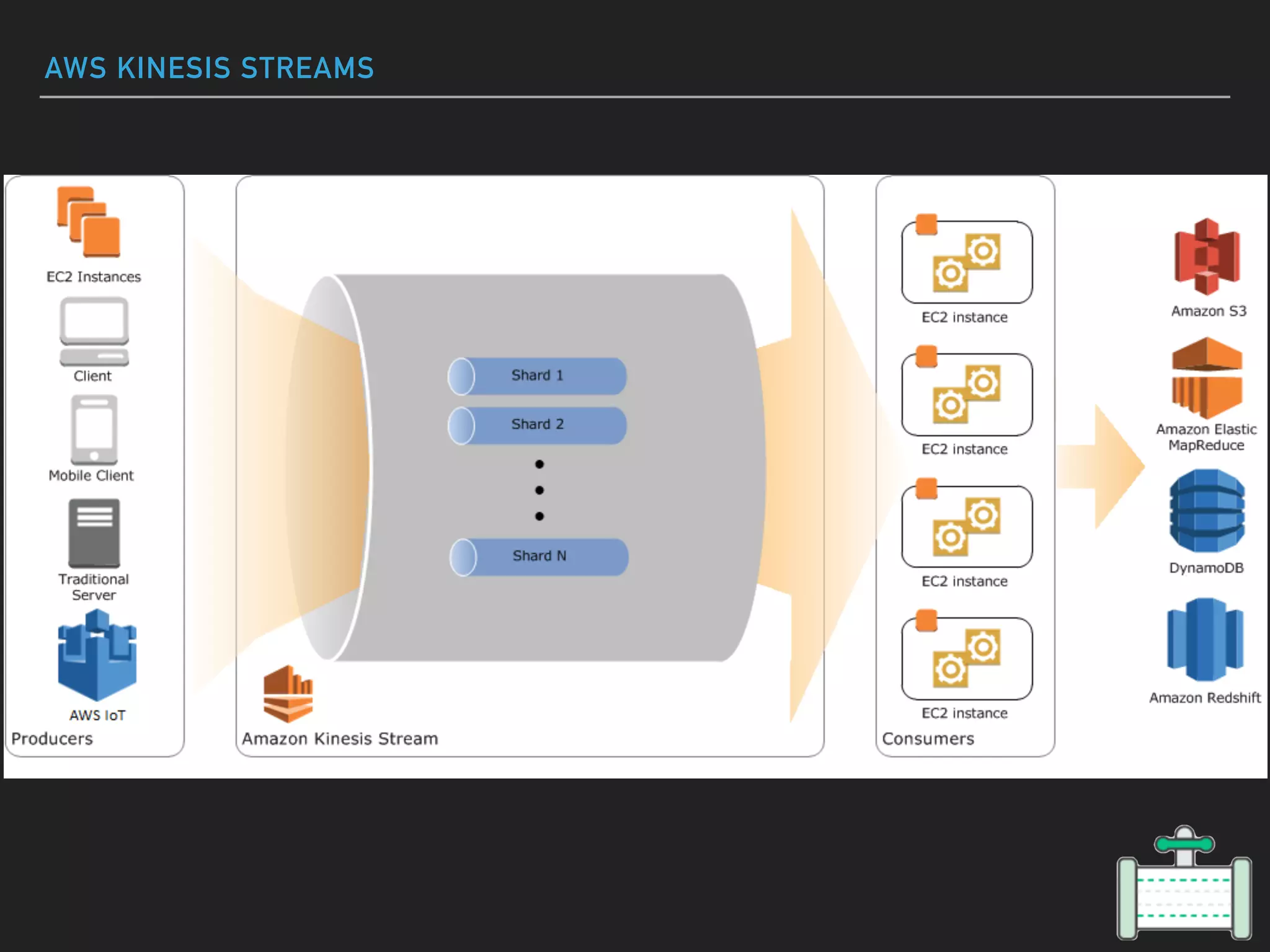
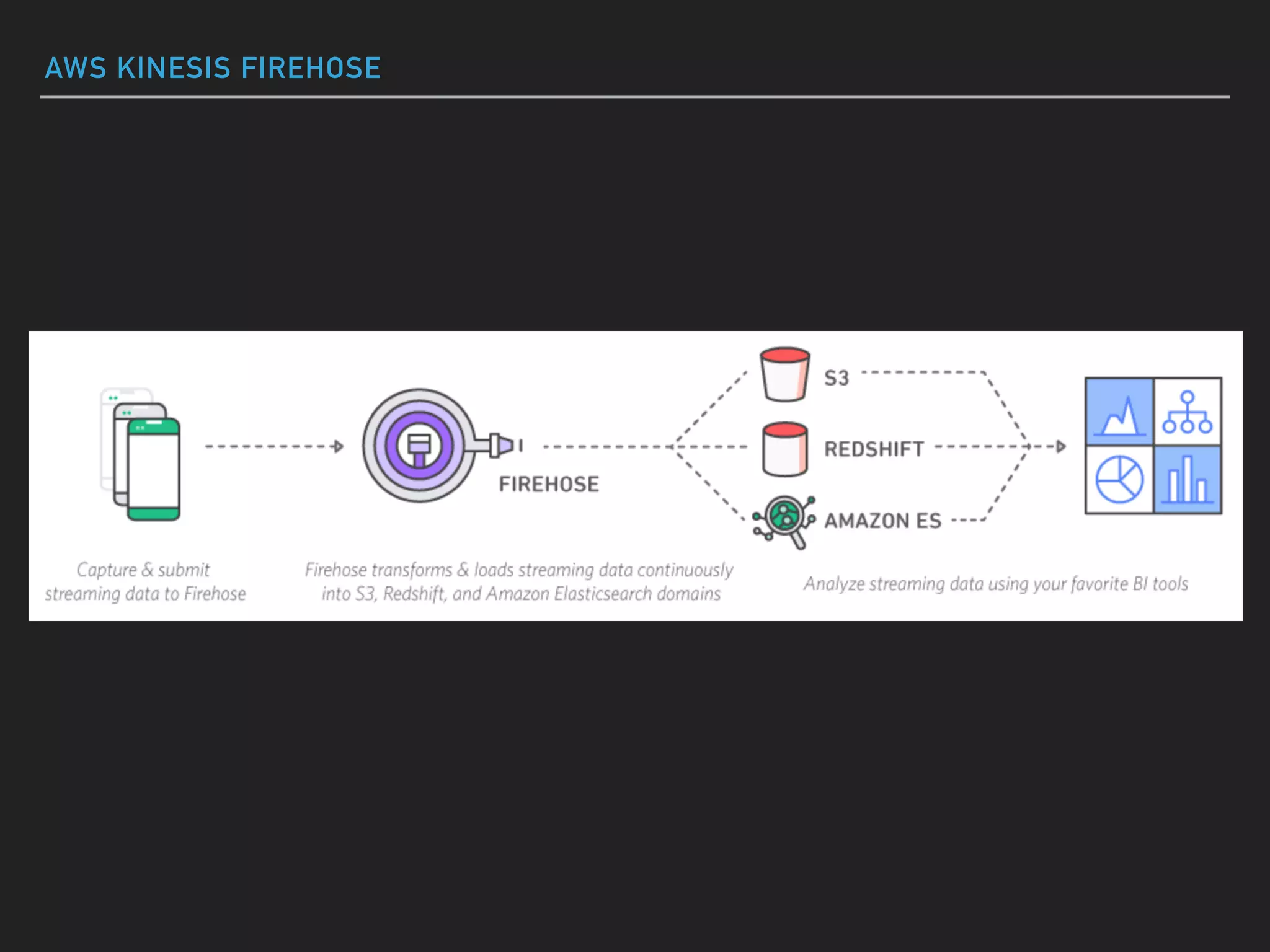
This document provides an introduction to various AWS big data services including Kinesis, Kinesis Firehose, Kinesis Analytics, SQS, IoT, Data Pipeline, DynamoDB, EMR, Lambda, Redshift, and QuickSight. It describes the core concepts and components of each service. For services like Kinesis, Kinesis Analytics, and EMR it provides details on architecture, terminology, pricing models, and best practices. The document aims to give readers an overview of the AWS big data landscape and how the different services can be used together in a big data context.






















































