R Apache
•
2 likes•861 views

This document provides an overview of the RApache software architecture. RApache allows R to be used as a statistical engine for web applications by embedding the R interpreter into the Apache web server using a module. This allows R functions to be called from Apache to dynamically generate web content. Examples shown include a "Hello World" example using a simple R handler function, generating plots from R code and returning them to the client, and several RApache demonstrations of applications with different capabilities. Ongoing work is focused on improving performance and interfaces.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (13)
Similar to R Apache
Similar to R Apache (20)
More from Ajay Ohri
More from Ajay Ohri (20)
R Apache
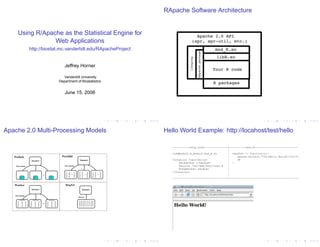
- 1. RApache Software Architecture Using R/Apache as the Statistical Engine for Web Applications http://biostat.mc.vanderbilt.edu/RApacheProject Jeffrey Horner Vanderbilt University Department of Biostatistics June 15, 2006 Apache 2.0 Multi-Processing Models Hello World Example: http://locahost/test/hello -----------http.conf---------------+----------test.R--------------------------- | LoadModule R_module mod_R.so | handler <- function(r){ Prefork Perchild | apache.write(r,"<h1>Hello World!</h1>") Parent Parent <Location /test/hello> | OK SetHandler r-handler | } Children Children Rsource /var/www/html/test.R | RreqHandler handler | </Location> | | R R R -----------------------------------+-------------------------------------------- Worker WinNT Parent Parent Children Child
- 2. GDD/NRart Example GDD/NRart Example Output library(’GDD’) library(’NRart’) r2 <- function(r) { apache.set_content_type(r,"image/png") GDD(ctx=apache.gdlib_ioctx(r),w=500,h=500,type="png") nr.image(x^3 + .28 * tan(x + t) + cos(x + 2*t)*.3i - 0.7, steps=3, points=400, col=rainbow(256), zlim=c(-pi, pi)) dev.off() OK } RApache Demonstrations Ongoing Work Full Feature Test Handler Demonstrates all the capabilities of RApache include CGI, Rmemcache manipulating HTTP headers, and file uploading. Implements client API to memcached, a possibly distributed EVT-Web cache (not a database) of small objects. R objects are Implements a web interface to a protein searching stored in memcache server via serialize(). algorithm using Extreme Value Theory. The web interface udbMySQL takes a group of related proteins as input from the user and generates a profile via an external program (MEME). Then Uses the "User Defined Database" interface to store R a model is built to predict which other proteins from a large objects of arbitrary size and structure in a MySQL table. database (MySQL) are also related to the group of proteins Getting the next release out the door that the user specified. Testing against Apache 2.2, R-2.3.1. Looking into getting Polyart rid of some of the apache.* methods in favor of a more Demonstrates the use of RApache as a web service to transparent interface, especially apache.write(). explore images created through the process of finding roots of functions, i.e. using the NRart package.