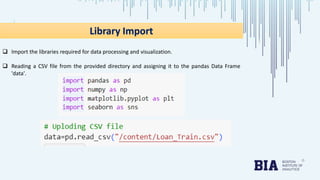
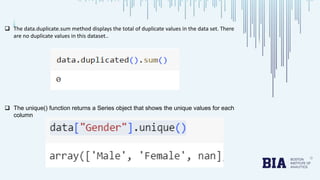
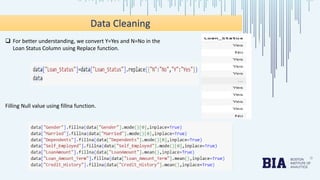
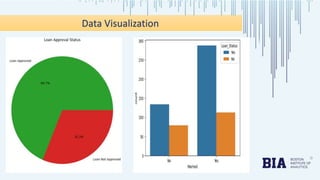
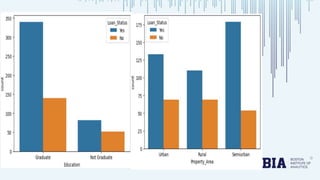
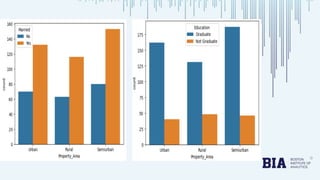
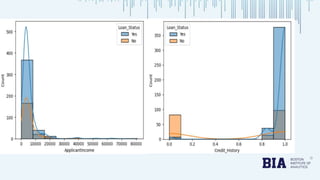
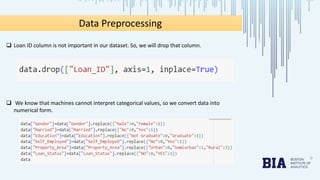
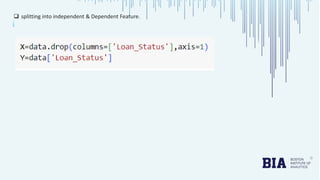
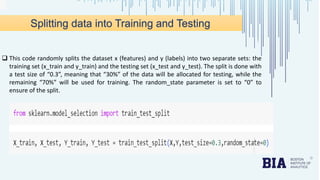
The document presents a bank loan approval analysis aimed at automating the loan eligibility process based on customer details. It details the data preparation, exploratory data analysis, model building using logistic regression, SVC, and KNN, ultimately finding logistic regression to be the most effective model with an accuracy of 79% for training and 82% for testing. Observations indicate that educated, married individuals in semi-urban areas have a higher likelihood of loan approval.