Downloaded 10 times






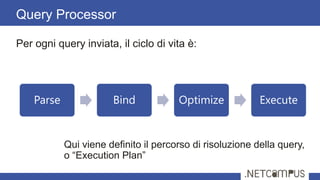
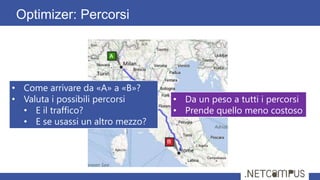




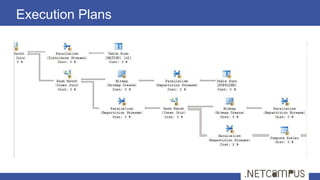






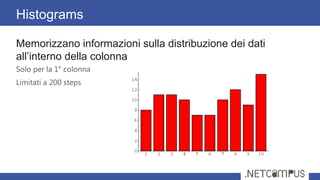

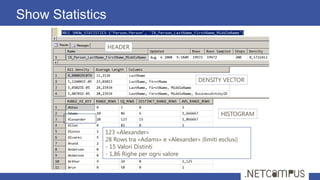




Il documento tratta dell'ottimizzazione delle query in SQL Server, dettagliando il ciclo di vita di una query, dalla parsing all'esecuzione, e l'importanza degli execution plans. Viene discusso come l'ottimizzazione si basa su stime dei costi per diverse strategie di esecuzione, con tecniche per ridurre il numero di piani da valutare. Infine, si evidenzia l'importanza delle statistiche sulla distribuzione dei dati per ottenere stime accurate e migliorare le performance delle query.















































