Download as PDF, PPTX







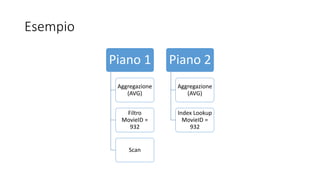











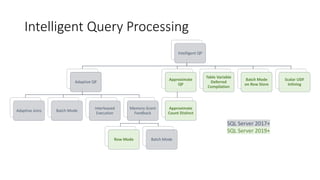








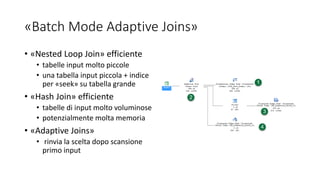



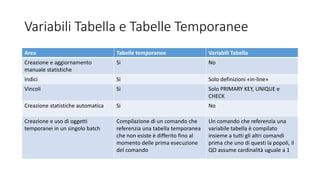















Il documento presenta le innovazioni nel modern query processing di SQL Server, coprendo argomenti come il cardinality estimator, l'auto-tuning e il query optimizer. Viene esplorato l'uso di approcci euristici per ottimizzare le query, nonché le nuove funzionalità introdotte nelle versioni recenti per migliorare le prestazioni delle query, inclusi i batch mode e il scalar UDF in-lining. Infine, sono forniti esempi pratici e tecniche di troubleshooting per un'implementazione più efficiente.












































![ACS, ECS [e Cardinality/Statistics feedback]](https://cdn.slidesharecdn.com/ss_thumbnails/icteam-itougtechday-2017adaptive-cursor-sharing-acs-extended-cursor-sharing-ecs-and-cardinalitystati-170630093042-thumbnail.jpg?width=640&height=640&fit=bounds)
















